课上练习:淘宝数据分,求各个位置成交额最多的商家
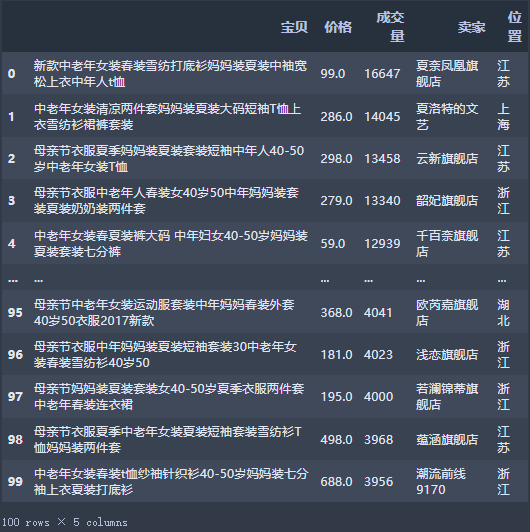
df[['位置','成交额','卖家']].groupby(['位置']).apply(lambda x:x.nlargest(3,"成交额"))
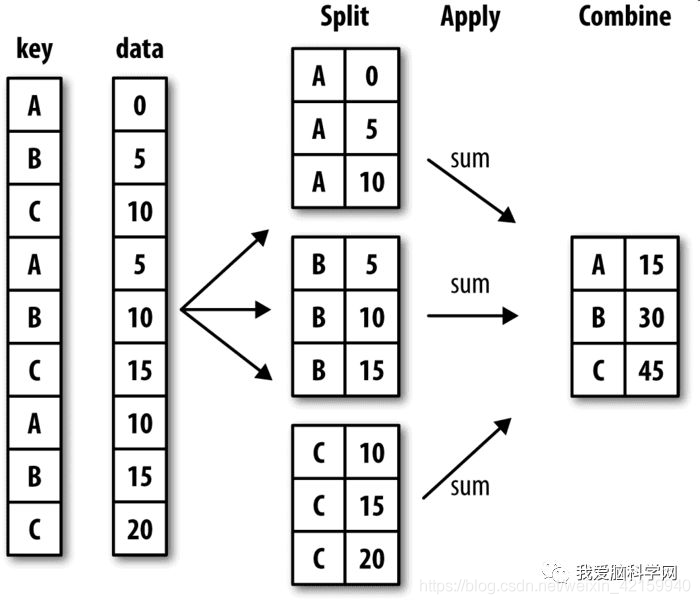
groupby和apply的联用原理
Hadley Wickham(许多热门R语言包的作者)创造了一个用于表示分组运算的术语"split-apply-combine"(拆分-应用-合并)。第一个阶段,pandas对象(无论是Series、DataFrame还是其他的)中的数据会根据你所提供的一个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。例如,DataFrame可以在其行(axis=0)或列(axis=1)上进行分组。然后,将一个函数应用(apply)到各个分组并产生一个新值。最后,所有这些函数的执行结果会被合并(combine)到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。图10-1大致说明了一个简单的分组聚合过程。
【学习经典】python 数据聚合与分组运算(part 1)_浮点型队友-CSDN博客_python分组聚合
一些关于apply和groupby的练习题: