unique,top和freq似乎是对字符串统计,对数值无计算
其中top有mode作用freq也指的是众数的频数,当分类数量都为1时,按unicode排序
缺失值由NaN补上,如果为NaN,说明此列的信息不可以用这个统计变量进行统计的。
注意,数值列和字母列是不一样的。
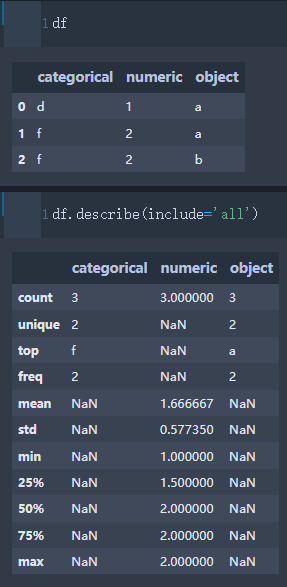
例子出自官方文档里:pandas.DataFrame.describe — pandas 1.3.5 documentation (pydata.org)
Examples -------- >>> df = pd.DataFrame({'categorical': pd.Categorical(['d','e','f']), ... 'numeric': [1, 2, 3], ... 'object': ['a', 'b', 'c'] ... }) >>> df.describe() numeric count 3.0 mean 2.0 std 1.0 min 1.0 25% 1.5 50% 2.0 75% 2.5 max 3.0 Describing all columns of a ``DataFrame`` regardless of data type. >>> df.describe(include='all') # doctest: +SKIP categorical numeric object count 3 3.0 3 unique 3 NaN 3 top f NaN a freq 1 NaN 1 mean NaN 2.0 NaN std NaN 1.0 NaN min NaN 1.0 NaN 25% NaN 1.5 NaN 50% NaN 2.0 NaN 75% NaN 2.5 NaN max NaN 3.0 NaN Describing a column from a ``DataFrame`` by accessing it as an attribute. >>> df.numeric.describe() count 3.0 mean 2.0 std 1.0 min 1.0 25% 1.5 50% 2.0 75% 2.5 max 3.0 Name: numeric, dtype: float64 Including only numeric columns in a ``DataFrame`` description. >>> df.describe(include=[np.number]) numeric count 3.0 mean 2.0 std 1.0 min 1.0 25% 1.5 50% 2.0 75% 2.5 max 3.0 Including only string columns in a ``DataFrame`` description. >>> df.describe(include=[object]) # doctest: +SKIP object count 3 unique 3 top a freq 1 Including only categorical columns from a ``DataFrame`` description. >>> df.describe(include=['category']) categorical count 3 unique 3 top f freq 1 Excluding numeric columns from a ``DataFrame`` description. >>> df.describe(exclude=[np.number]) # doctest: +SKIP categorical object count 3 3 unique 3 3 top f a freq 1 1 Excluding object columns from a ``DataFrame`` description. >>> df.describe(exclude=[object]) # doctest: +SKIP categorical numeric count 3 3.0 unique 3 NaN top f NaN freq 1 NaN mean NaN 2.0 std NaN 1.0 min NaN 1.0 25% NaN 1.5 50% NaN 2.0 75% NaN 2.5 max NaN 3.0