参考:
https://www.cnblogs.com/javazhiyin/p/10905294.html
https://www.jianshu.com/p/1dec08d290c1
https://www.jianshu.com/p/a77e64250a9e
https://www.cnblogs.com/nijunyang/p/12365048.html
https://baijiahao.baidu.com/s?id=1670006072186363018&wfr=spider&for=pc
深究Spring中Bean的生命周期
前言
这其实是一道面试题,是我在面试百度的时候被问到的,当时没有答出来(因为自己真的很菜),后来在网上寻找答案,看到也是一头雾水,直到看到了《Spring in action》这本书,书上有对Bean声明周期的大致解释,但是没有代码分析,所以就自己上网寻找资料,一定要把这个Bean生命周期弄明白!
网上大部分都是验证的Bean 在面试问的生命周期,其实查阅JDK还有一个完整的Bean生命周期,这同时也验证了书是具有片面性的,最fresh 的资料还是查阅原始JDK!!!
一、Bean 的完整生命周期
在传统的Java应用中,bean的生命周期很简单,使用Java关键字 new 进行Bean 的实例化,然后该Bean 就能够使用了。一旦bean不再被使用,则由Java自动进行垃圾回收。
相比之下,Spring管理Bean的生命周期就复杂多了,正确理解Bean 的生命周期非常重要,因为Spring对Bean的管理可扩展性非常强,下面展示了一个Bean的构造过程

Bean 的生命周期
如上图所示,Bean 的生命周期还是比较复杂的,下面来对上图每一个步骤做文字描述:
-
Spring启动,查找并加载需要被Spring管理的bean,进行Bean的实例化
-
Bean实例化后对将Bean的引入和值注入到Bean的属性中
-
如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法
-
如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入
-
如果Bean实现了ApplicationContextAware接口的话,Spring将调用Bean的setApplicationContext()方法,将bean所在应用上下文引用传入进来。
-
如果Bean实现了BeanPostProcessor接口,Spring就将调用他们的postProcessBeforeInitialization()方法。
-
如果Bean 实现了InitializingBean接口,Spring将调用他们的afterPropertiesSet()方法。类似的,如果bean使用init-method声明了初始化方法,该方法也会被调用
-
如果Bean 实现了BeanPostProcessor接口,Spring就将调用他们的postProcessAfterInitialization()方法。
-
此时,Bean已经准备就绪,可以被应用程序使用了。他们将一直驻留在应用上下文中,直到应用上下文被销毁。
-
如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法,同样,如果bean使用了destory-method 声明销毁方法,该方法也会被调用。
上面是Spring 中Bean的核心接口和生命周期,面试回答上述过程已经足够了。但是翻阅JavaDoc文档发现除了以上接口外,还有另外的初始化过程涉及的接口:
摘自org.springframework.beans.factory.BeanFactory, 全部相关接口如下,上述已有的就不用着重标注,把额外的相关接口着重标注下

Bean 完整的生命周期
文字解释如下:
————————————初始化————————————
-
BeanNameAware.setBeanName() 在创建此bean的bean工厂中设置bean的名称,在普通属性设置之后调用,在InitializinngBean.afterPropertiesSet()方法之前调用
-
BeanClassLoaderAware.setBeanClassLoader(): 在普通属性设置之后,InitializingBean.afterPropertiesSet()之前调用 -
BeanFactoryAware.setBeanFactory() : 回调提供了自己的bean实例工厂,在普通属性设置之后,在InitializingBean.afterPropertiesSet()或者自定义初始化方法之前调用
-
EnvironmentAware.setEnvironment(): 设置environment在组件使用时调用 -
EmbeddedValueResolverAware.setEmbeddedValueResolver(): 设置StringValueResolver 用来解决嵌入式的值域问题 -
ResourceLoaderAware.setResourceLoader(): 在普通bean对象之后调用,在afterPropertiesSet 或者自定义的init-method 之前调用,在 ApplicationContextAware 之前调用。 -
ApplicationEventPublisherAware.setApplicationEventPublisher(): 在普通bean属性之后调用,在初始化调用afterPropertiesSet 或者自定义初始化方法之前调用。在 ApplicationContextAware 之前调用。 -
MessageSourceAware.setMessageSource(): 在普通bean属性之后调用,在初始化调用afterPropertiesSet 或者自定义初始化方法之前调用,在 ApplicationContextAware 之前调用。 -
ApplicationContextAware.setApplicationContext(): 在普通Bean对象生成之后调用,在InitializingBean.afterPropertiesSet之前调用或者用户自定义初始化方法之前。在ResourceLoaderAware.setResourceLoader,ApplicationEventPublisherAware.setApplicationEventPublisher,MessageSourceAware之后调用。
-
ServletContextAware.setServletContext(): 运行时设置ServletContext,在普通bean初始化后调用,在InitializingBean.afterPropertiesSet之前调用,在 ApplicationContextAware 之后调用注:是在WebApplicationContext 运行时 -
BeanPostProcessor.postProcessBeforeInitialization() : 将此BeanPostProcessor 应用于给定的新bean实例 在任何bean初始化回调方法(像是InitializingBean.afterPropertiesSet或者自定义的初始化方法)之前调用。这个bean将要准备填充属性的值。返回的bean示例可能被普通对象包装,默认实现返回是一个bean。
-
BeanPostProcessor.postProcessAfterInitialization() : 将此BeanPostProcessor 应用于给定的新bean实例 在任何bean初始化回调方法(像是InitializingBean.afterPropertiesSet或者自定义的初始化方法)之后调用。这个bean将要准备填充属性的值。返回的bean示例可能被普通对象包装
-
InitializingBean.afterPropertiesSet(): 被BeanFactory在设置所有bean属性之后调用(并且满足BeanFactory 和 ApplicationContextAware)。
————————————销毁————————————
在BeanFactory 关闭的时候,Bean的生命周期会调用如下方法:
-
DestructionAwareBeanPostProcessor.postProcessBeforeDestruction(): 在销毁之前将此BeanPostProcessor 应用于给定的bean实例。能够调用自定义回调,像是DisposableBean 的销毁和自定义销毁方法,这个回调仅仅适用于工厂中的单例bean(包括内部bean) -
实现了自定义的destory()方法
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
实例化 -> 属性赋值 -> 初始化 -> 销毁
主要逻辑都在doCreate()方法中,逻辑很清晰,就是顺序调用以下三个方法,这三个方法与三个生命周期阶段一一对应,非常重要,在后续扩展接口分析中也会涉及。
- createBeanInstance() -> 实例化
- populateBean() -> 属性赋值
- initializeBean() -> 初始化
源码如下,能证明实例化,属性赋值和初始化这三个生命周期的存在。关于本文的Spring源码都将忽略无关部分,便于理解:
// 忽略了无关代码
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final 至于销毁,是在容器关闭时调用的,详见ConfigurableApplicationContext#close()
@Autowired注解原理和使用
https://blog.csdn.net/chuhx/article/details/104878246
https://blog.csdn.net/nuomizhende45/article/details/84960303
todo
如何解决循环依赖
前面说到对象的创建,那么在创建的过程中Spring是怎么又是如何解决循环依赖的呢。前面提到有个三级缓存。就是利用这个来解决循环依赖。打个比方说实例化A的时候,先将A创建(早期对象)放入一个池子中。这个时候虽然属性没有赋值,但是容器已经能认识这个是A对象,只是属性全是null而已。在populateBean方法中对属性赋值的时候,发现A依赖了B,那么就先去创建B了,又走一遍bean的创建过程(创建B)。同样也会把B的早期对象放入缓存中。当B又走到populateBean方法的时候,发现依赖了A,好吧,我们又去创建A呗,但是这个时候去创建A,发现我们在缓存能找到A(早期对象)了。就可以把B的A属性赋值了,这个时候B就初始化完成了。现在回到A调用的populateBean方法中。返回的就是B对象了,对A的B属性进行赋值就可以了。流程如下:
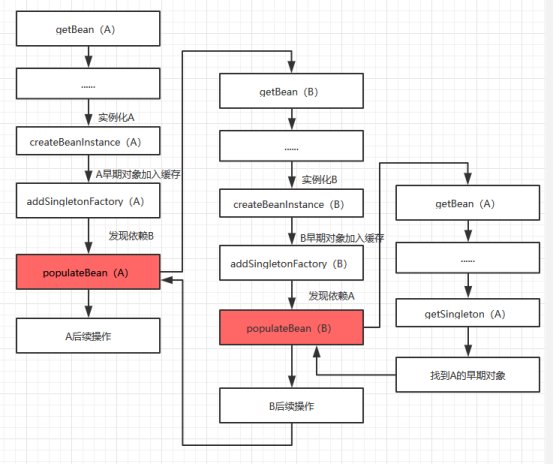
这就是Spring IOC如何解决循环依赖的原理,但是IOC无法解决两种循环依赖,一种是非单例对象的,因为非单例对象不会放入缓存的。每次都是需要创建。二是通过构造器注入,也无法解决。从上面的流程可以看出,调用构造器创建实例是在createBeanInstance方法,而解决循环依赖是在populateBean这个方法中,执行顺序也决定了无法解决该种循环依赖。对于这种,如果喜欢使用lombok的@RequiredArgsConstructor注解的小伙伴就需要注意了,这个注解会生成一个带所有属性的构造方法。通过idea直接点开对应的class文件就可以看不看这个构造方法了。
问题:解决循环依赖一定要三级缓存嘛?
关键代码位置:org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#addSingletonFactory
首先我们的一级缓存是单例缓存池(singletonObjects),二级缓存是早期对象(earlySingletonObjects),三级缓存是一个包裹对象ObjectFactory(registeredSingletons),通过getObject获取到早期对象。
从上面的流程来看,实际上二级缓存已经可以解决循环依赖了,那么为什么Spring还要包裹出来一个三级缓存呢?
从Spring Ioc(3)---bean的实例化中的源码分析我们可以看到调用三级缓存中的getObject方法实际上是调用的org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#getEarlyBeanReference这个方法。
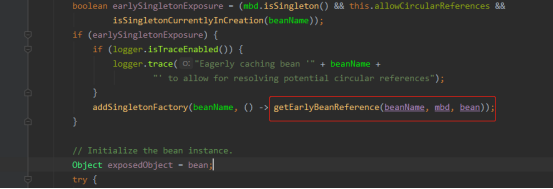
那么我就看看这个方法里面干了些什么事情:
执行SmartInstantiationAwareBeanPostProcessor这个类型处理器的getEarlyBeanReference方法。
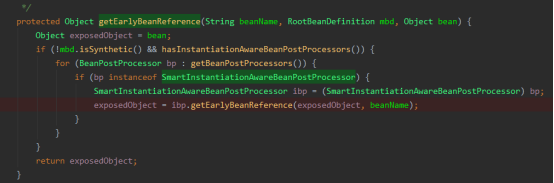
断点调试,发现Spring原生中实现了这个接口的类org.springframework.beans.factory.config.InstantiationAwareBeanPostProcessorAdapter,实际上什么事情都没有干,直接返回了,

但是如果是AOP要切的对象,会在这里生成代理对象返回,AOP流程:Spring aop(1)--- 寻找切面和代理对象执行流程源码分析
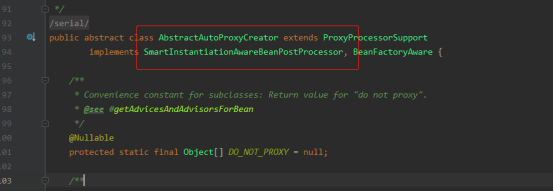
org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator#getEarlyBeanReference。
所以说第三级缓存其实是为了解决代理对象之间的循环依赖。
Spring IOC容器是如何解决循环依赖的问题?
- 什么是循环依赖?
先看代码:
public class A {
private B b;
// 省略set/get方法
}
public class B {
private A a;
// 省略set/get方法
}
可以看到A类里有一个属性是B类对象,而B类里也有一个属性是A类对象,则我们可以称A类对象与B类对象之间互相循环依赖。然后我们对把这俩个类纳入到IOC容器中进行管理,现在进行xml配置:
<bean id="a" class="com.A">
<property name="b" ref="b"/>
</bean>
<bean id="b" class="com.B">
<property name="a" ref="a"/>
</bean>
当配置好xml以后,我们创建容器,并且调用getBean方法来获取某个对象,那么会发生什么事情呢?正常逻辑应该是发生了死循环,a对象的创建需要依赖b对象,而b对象的创建同时也需要a对象。这简直就是没办法解决嘛!但是SpringIOC却解决了这个问题,并且你可以正常的获取到相应的对象而不会发生错误。
那么SpringIOC是如何解决循环依赖的问题呢?
原理
SpringIOC解决循环依赖的思路就是依靠缓存,同时还得引出个概念即早期暴露引用。我们知道在IOC容器里bean的初始化的过程分为三个步骤:创建实例、属性注入实例、回调实例实现的接口方法。解决思路就在这:当我们创建实例与属性注入实例这俩个步骤之间的时候,我们引入缓存,将这些已经创建好但是并没有注入属性的实例放到缓存里,而这些放在缓存里但是没有被注入属性的实例对象,就是解决循环依赖的方法,打个比方:A对象的创建需要引用到B对象,而B对象的创建也需要A对象,而此时当B对象创建的时候直接从缓存里引用A对象(虽然不是完全体A对象,毕竟没有赋值处理),当B对象完成创建以后再被A对象引用进去,则A对象也完成了创建。
这就是SpringIOC解决bean直接循环依赖的思路当然有一个小问题,IOC能够解决的只能是属性之间的循环依赖,如果有bean之间的构造器相互依赖则就解决不了只能报错了。
- 我们现在来看看Spring IOC的源码
先看一下下面介绍源码里的缓存的表:
| 源码 | 级别 | 描述 |
|---|---|---|
| singletonObjects | 一级缓存 | 用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 |
| earlySingletonObjects | 二级缓存 | 存放原始的 bean 对象(尚未填充属性),用于解决循环依赖 |
| singletonFactories | 三级缓存 | 存放 bean 工厂对象,用于解决循环依赖 |
省略不必要的代码
protected <T> T doGetBean( final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
Object bean;
// 从缓存中取得bean的实例
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
//进行后续处理,如果是正常的普通bean则返回普通的bean,如果是实现了FactoryBean接口的bean则返回的是getObject里的内容
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// 解决依赖的问题,这个跟我们说的依赖是不一样的.可以忽略
// ......
// 创建单例 bean
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// 发生异常,销毁bean
destroySingleton(beanName);
throw ex;
}
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
// Check if required type matches the type of the actual bean instance.
// ......
return (T) bean;
}
以上是doGetBean方法里的代码,当然我省略了跟本章无关的代码。
一步步来吧,先进行初始化a对象的操作,然后发现调用的是createBean(String beanName, RootBeanDefinition mbd, Object[] args)方法,而真正起作用的是doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)方法。而在这个方法里面包含了三个重要的方法createBeanInstance、populateBean、initializeBean,看过之前系列文章的人都知道这三个方法分别代表:创建实例、属性注入、方法回调,这是bean初始化的核心方法。当然下面这段代码是在createBeanInstance和populateBean中间的一段doCreateBean的代码。
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// ......
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
这段代码在spring源码注释里描述是用来解决循环依赖的问题的。包含了一个匿名内部类ObjectFactory<T>(普通的工厂类返回的是getObject方法返回的对象),用getEarlyBeanReference实现了getObject方法。同时还调用了addSingletonFactory方法。分别来看一下各自方法的实现:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (bean != null && !mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
if (exposedObject == null) {
return null;
}
}
}
}
return exposedObject;
}
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
可以看到在addSingletonFactory方法中,会将beanName与singletonFactory形成kv关系put进singletonFactories里面。并且将earlySingletonObjects里面的key值为beanName的kv进行移除。
此时a对象的早期暴露引用已经存在了singletonFactories三级缓存里面。此时a对象进行populateBean方法进行属性注入,发现需要依赖b对象,紧接着就是去初始化b对象。继续重复上面的步骤到b对象进行属性注入这一步的时候(此时singletonFactories三级缓存里已经有了a对象的提前暴露引用和b对象的提前暴露引用的工厂对象),发现需要依赖a对象,此时去获取a对象,看代码:
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);
//继续看这个方法
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
先从singletonObjects一级缓存里取,如果没有取到,则从earlySingletonObjects二级缓存里取,如果还是没取到,则从singletonFactories三级缓存里取,取到以后进行getObject方法返回早期暴露对象引用,同时放进earlySingletonObjects二级缓存里,并且三级缓存里进行删除该kv。
那么到此,a对象的早期暴露引用已经被b对象获取到了,并且在singletonFactories三级缓存里已经没有a对象的早期暴露引用的工厂对象了,a对象的早期暴露引用存在了二级缓存earlySingletonObjects里面,当然singletonFactories三级缓存依然有b对象的早期暴露引用的工厂对象。
继续:b对象拿到了a对象的早期暴露引用,进行完属性注入以后,则返回一个b对象了同时调用方法getSingleton(String beanName, ObjectFactory<?> singletonFactory),看源码:
//我已经删除了很多无关的代码
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
// ......
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// ......
beforeSingletonCreation(beanName);
boolean newSingleton = false;
// ... ...
//... ...
try {
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
finally {
// ... ...
}
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}
其实就是俩个方法:singletonObject = singletonFactory.getObject();和addSingleton(beanName, singletonObject);至此我们不需要说明第一个了,着重来看一下addSingleton方法。
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
ok,上面源码已经说明了此时singletonObjects一级缓存将要存入b对象,而二级缓存earlySingletonObjects和三级缓存singletonFactories则把相关缓存的对象移除。至此b对象则只存在一级缓存singletonObjects里面了。
当b对象完成了初始化以后,a对象则进行相关属性的注入引入b的对象。完成实例化的同时a对象也会调用一次addSingleton方法,那么a对象完成以后,也就只有一级缓存singletonObjects里面才有a对象。
至此,属性的循环依赖问题则完美的得到解决。
- 文末
感谢 【减肥是生命的主旋律】 的提问和回答
有一个小问题,为什么在解决循环依赖问题的时候,我们会用到三级缓存singletonFactories呢?感觉二级缓存earlySingletonObjects就可以解决问题了呢?
那么答案就在这里:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (bean != null && !mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
if (exposedObject == null) {
return null;
}
}
}
}
return exposedObject;
}
在将三级缓存放入二级缓存的时候,会判断是否有SmartInstantiationAwareBeanPostProcessor这样的后置处理器,换句话说这里是给用户提供接口扩展的,所以采用了三级缓存。
最近面试当时问到了Spring AOP的实现方式,然后就问到了jdk动态代理为什么使用接口而不是使用继承,当时一时没转过弯来,后来自己回来看了一下原来如此,面试有时就是这样问题不难,但就是可能想不到这个点去回答。
分析
动态代理是使用反射和字节码的技术,在运行期创建指定接口和类的子类以及其实例对象的技术,通过动态代理可以对代码进行增强。java动态代理主要有两种形式:JDK原生的动态代理和CGLIB动态代理。面试中经常被问到jdk动态代理为什么要使用接口,而不是使用继承,接下来我们将生成一个代理类看看为什么要如此。
首先定义一个接口,上面也提到了要使用接口而不是继承,使用接口就是在使用生成代理类提供方法的模板。

然后实现接口,这个是具体的一个实现了,我们就是要增强这个实现类的方法。

InvocationHandler是由代理实例的调用处理程序实现的接口。每当调用代理实例的时候就会调用InvocationHandler的invoke方法。

测试,Proxy提供了创建动态代理类和实例的静态方法,它也是由这些方法创建的所有动态代理类的超类。这里为什么要使传入classLoader主要是运行时动态生成字节码,然后需要classLoader加载这个类,最终通过反射类实例生成代理类的实例。传入接口UserServive是为了给生成代理类提供方法的模板。

接下来,我们生成一个代理类,我们可以看到生成的代理类其实是继承了Proxy,而java是单继承多实现的。

总结
我们都知道java是单继承多实现的,因为生成的代理实例已经需要顶级父类Proxy了,如果你在定义成父类显然是违背了这个原则,所以jdk动态代理一般都是先定义接口,可能你会使用动态代理,但不一定会注意这个问题。
另外,为何调用代理类的方法就会自动进入InvocationHandler 的 invoke()方法呢?
其实是因为在动态代理类的定义中,构造函数是含参的构造,参数就是我们invocationHandler 实例,而每一个被代理接口的方法都会在代理类中生成一个对应的实现方法,并在实现方法中最终调用invocationHandler 的invoke方法,这就解释了为何执行代理类的方法会自动进入到我们自定义的invocationHandler的invoke方法中,然后在我们的invoke方法中再利用jdk反射的方式去调用真正的被代理类的业务方法,而且还可以在方法的前后去加一些我们自定义的逻辑。比如切面编程AOP等。