前言
这一章节我们将讲解高并发解决方案中的应用限流思路。像我们之前讲的股票数据并没有把他们直接存放到数据库,而是放到Redis中,利用缓存保证用户能看到的数据的实时性和准确性。
主体概要
- 限流概念
- 应用限流示例
- 应用限流算法
主体内容
一、限流概念
限流就是通过对并发访问/请求进行限速或一个时间窗口内的请求进行限速,从而达到保护系统的目的。一般系统可以通过压测来预估能处理的峰值,一旦达到设定的峰值阀值,则可以拒绝服务(定向错误页或告知资源没有了)、排队或等(例如:秒杀、评论、下单)、降级(返回默认数据)。
限流不能乱用,否则正常流量会出现一些奇怪的问题,从而导致用户抱怨。
二、应用限流示例
示例图

如果不做处理,130w-140w的数据会被某一时刻插入数据库,这时网络开销拉满,其他请求将无法获得资源。有的还有主库Master和从库slave,这时就会导致从库和主库的延迟特别大,那么从库查询到的数据不准确的概率会非常大。而我们要是放慢插入数据库的速度,又会是怎么样呢?结果就是如图所示,以恒定速率插入主库,从库也能保证正常同步数据。至于这个恒定速率是要根据实际场景来计算的。
三、应用限流算法
- 计数器法
- 滑动窗口
- 漏桶算法
- 令牌桶算法
1.计数器法(最简单,最容易实现的一种算法)
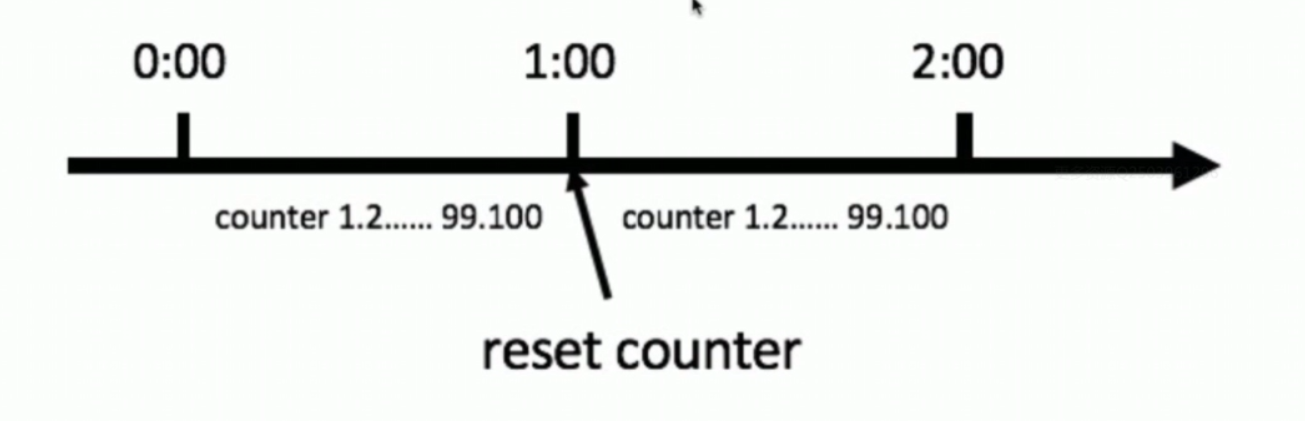
有时我们还会使用计数器来进行限流,主要用来限制一定时间内的总并发数,比如数据库连接池、线程池、秒杀的并发数;计数器限流只要一定时间内的总请求数超过设定的阀值则进行限流,是一种简单粗暴的总数量限流,而不是平均速率限流。
比如说我们A接口1分钟访问次数不能超过100次。那么我们可以这么做,在一开始的时候,我们设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter值大于100并且与刚开始请求的时间间隔在1分钟之内,那么我们就重置这个counter。
这个方法有一个致命问题:临界问题——当遇到恶意请求,在0:59时,瞬间请求100次,并且在1:00请求100次,那么这个用户在1秒内请求了200次,用户可以在重置节点突发请求,而瞬间超过我们设置的速率限制,用户可能通过算法漏洞击垮我们的应用。
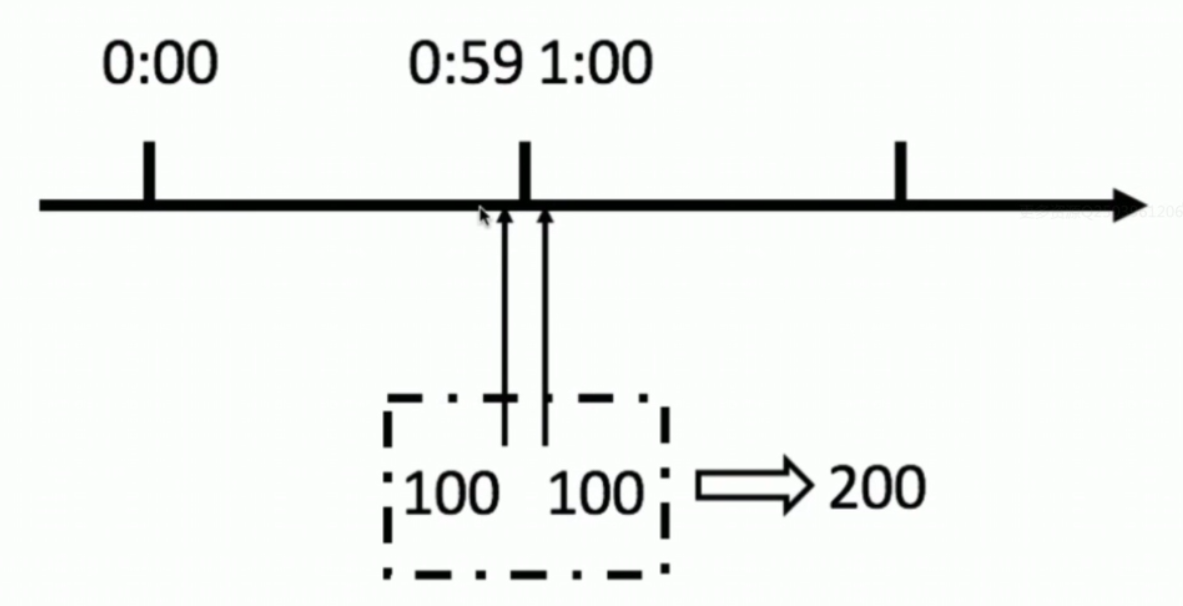
可以看出来,这是我们计算的精度太低导致的问题,解决办法就是增加精度。
2.滑动窗口
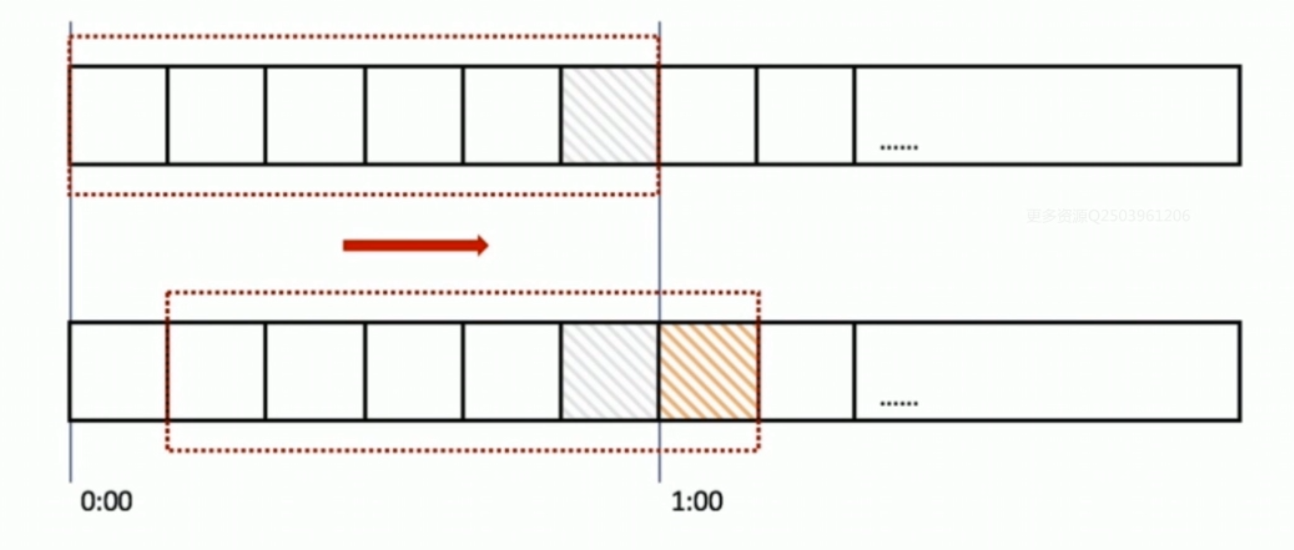
在上图中,整个红色矩形框是一个时间窗口,在我们的例子中,一个时间窗口就是1分钟,然后我们将时间窗口进行划分,如上图我们把滑动窗口划分为6格,所以每一格代表10秒,每超过10秒,我们的时间窗口就会向右滑动一格,每一格都有自己独立的计数器,例如:一个请求在0:35到达,那么0:30到0:39的计数器会+1,那么滑动窗口是怎么解决临界点的问题呢?如上图,0:59到达的100个请求会在灰色区域格子中,而1:00到达的请求会在红色格子中,窗口会向右滑动一格,那么此时间窗口内的总请求数共200个,超过了限定的100,所以此时能够检测出来触发了限流。回头看看计数器算法,会发现,其实计数器算法就是窗口滑动算法,只不过计数器算法没有对时间窗口进行划分,所以是一格。由此可见,当滑动窗口的格子划分越多,限流的统计就会越精确。
3.漏桶算法(Leaky Bucket)

这个算法很简单。首先,我们有一个固定容量的桶,有水进来,也有水出去。对于流进来的水,我们无法预计共有多少水流进来,也无法预计流水速度,但对于流出去的水来说,这个桶可以固定水流的速率,而且当桶满的时候,多余的水会溢出来。
4.令牌桶算法(Token Bucket)
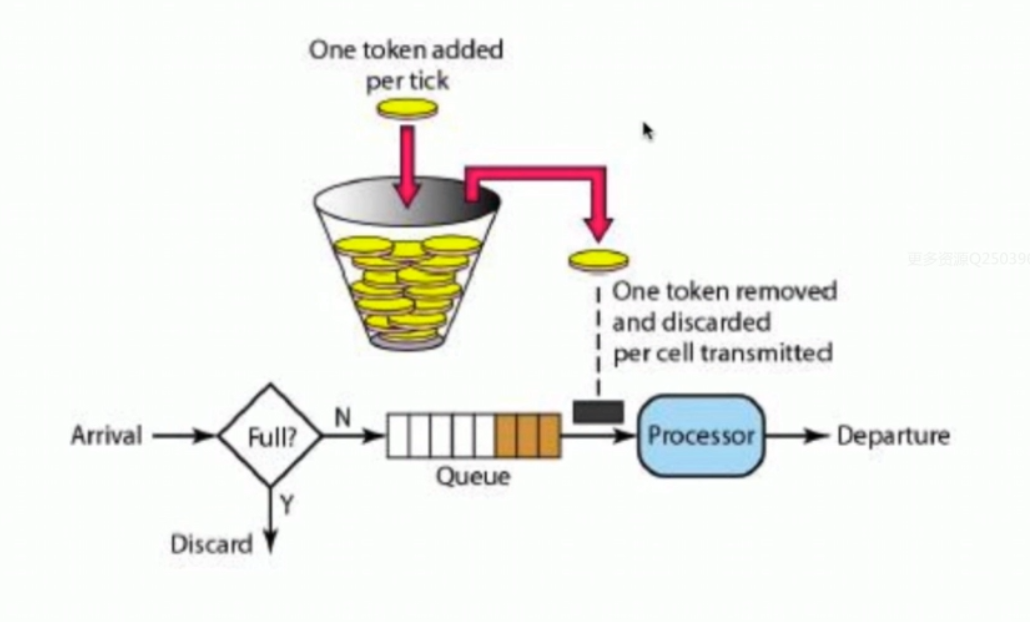
从上图中可以看出,令牌算法有点复杂,桶里存放着令牌token。桶一开始是空的,token以固定的速率r往桶里面填充,直到达到桶的容量,多余的token会被丢弃。每当一个请求过来时,就会尝试着移除一个token,如果没有token,请求无法通过。可以很好的解决临界问题。
四、算法比较
- 计数器算法VS滑动窗口算法
计数器算法:最简单,可以看成是滑动窗口的低精度的实现,滑动窗口算法由于要处理多出来的计数器,就是每一个格子存一份,所以滑动窗口在实现上需要更多的存储空间。就是说滑动窗口窗口越多,精度越高,需要的存储空间就越大。
- 漏桶算法VS令牌桶算法
令牌桶算法:以固定的速率(平均速率)生成对应的令牌放到桶中,客户端只需要在桶中获取到令牌后,就可以访问服务请求。
漏桶算法:以任意速率往桶中放入水滴,如果桶中的水滴没有满的话,可以访问服务。
在突发情况请求的时候,令牌桶中只需要客户端你能够拿到令牌就能访问服务。但是漏桶算法正好与令牌桶算法相反,令牌桶以平均速率访问,漏桶算法平滑访问。