背景
在MultiTask任务中,不同task的loss尺度是不一样的,可能相差很大,这样会导致共享的权重被大尺度的task主导,导致小尺度loss的task学不好
为了解决这个问题,常用的一个方法是对权重加权:
![]()
这样做的缺点就是,不同task的loss大小在训练中是会发生变化的,而上面的w是固定的,不能很好的适应训练过程中loss的变化
因此GradNorm提出了一种新的方法,即把loss的权重w也当作一个参数来学习:
![]()
GradNorm
我们的目标是通过实时的调整每个loss的权重w(t),使不同task对共享层参数的更新尺度基本相同
因此论文在正常的loss之外
在正常的loss之外定义了一个gradient loss
Gradient Loss被定义为所有task在当前时间t“真实gradient和target gradient norm的L1正则”相加之和:
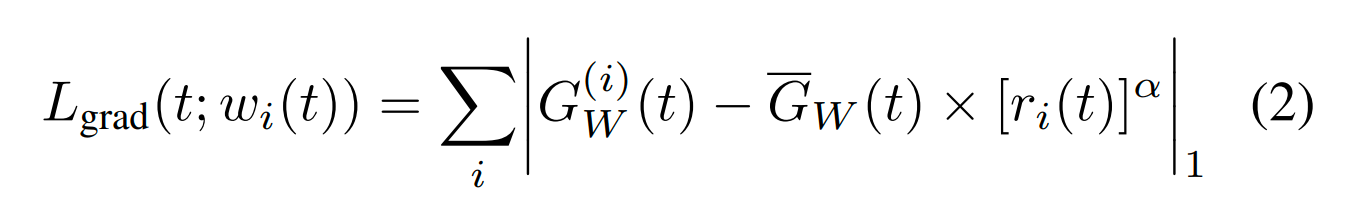

下面我们来具体解释一下上面的loss:
W 是共享层权重(论文中选了共享层最后一层权重),我们的目标就是通过调节w(t),使不同task对W的更新尺度相同
![]() 是不同加权的task loss对W的梯度的L2范数,其实就是不同task对W的更新尺度
是不同加权的task loss对W的梯度的L2范数,其实就是不同task对W的更新尺度
![]() 是所有task对W的平均更新尺度
是所有task对W的平均更新尺度
![]() 是每个task的loss的变化率,该值越小表示该task学习的越快
是每个task的loss的变化率,该值越小表示该task学习的越快
![]() 是task的相对loss变化率。该值越小表示该task学的相对越快
是task的相对loss变化率。该值越小表示该task学的相对越快
上面的loss的意思就是每个task对W的更新大小要和 所有task对W的平均更新大小乘以该task的loss的相对变化率 相同
其中乘以r(t)的目的就是希望,loss变化快的task对W的更新尺度小一些