MapReduce 是适合海量数据处理的编程模型。Hadoop是能够运行在使用各种语言编写的MapReduce程序: Java, Ruby, Python, and C++. MapReduce程序是平行性的,因此可使用多台机器集群执行大规模的数据分析非常有用的。
MapReduce程序的工作分两个阶段进行:
-
Map阶段
-
Reduce 阶段
输入到每一个阶段均是键 - 值对。此外,每一个程序员需要指定两个函数:map函数和reduce函数
整个过程要经历三个阶段执行:
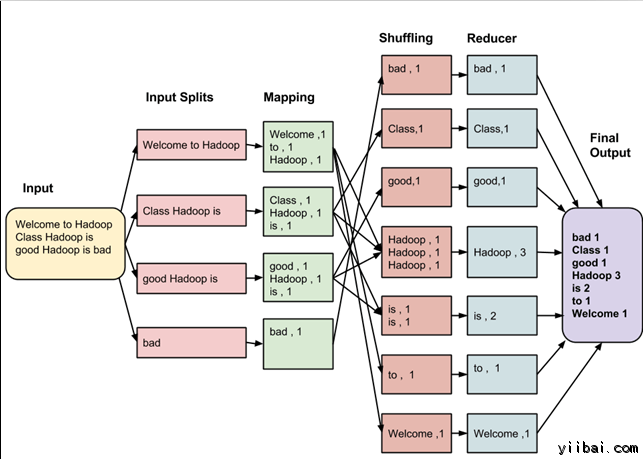
这些数据经过以下几个阶段
输入拆分:
输入到MapReduce工作被划分成固定大小的块叫做 input splits ,输入折分是由单个映射消费输入块。(注意这里的切片和hdfs中把文件切成多个block不一样,hdfs是物理切片,这里只是逻辑切片)
映射 - Mapping
这是在 map-reduce 程序执行的第一个阶段。在这个阶段中的每个分割的数据被传递给映射函数来产生输出值。在我们的例子中,映射阶段的任务是计算输入分割出现每个单词的数量(更多详细信息有关输入分割在下面给出)并编制以某一形式列表<单词,出现频率>
重排
这个阶段消耗映射阶段的输出。它的任务是合并映射阶段输出的相关记录。在我们的例子,同样的词汇以及它们各自出现频率。
Reducing
在这一阶段,从重排阶段输出值汇总。这个阶段结合来自重排阶段值,并返回一个输出值。总之,这一阶段汇总了完整的数据集。
在我们的例子中,这个阶段汇总来自重排阶段的值,计算每个单词出现次数的总和。