No.1. k-近邻算法的特点

No.2. 准备工作,导入类库,准备测试数据

No.3. 构建训练集

No.4. 简单查看一下训练数据集大概是什么样子,借助散点图
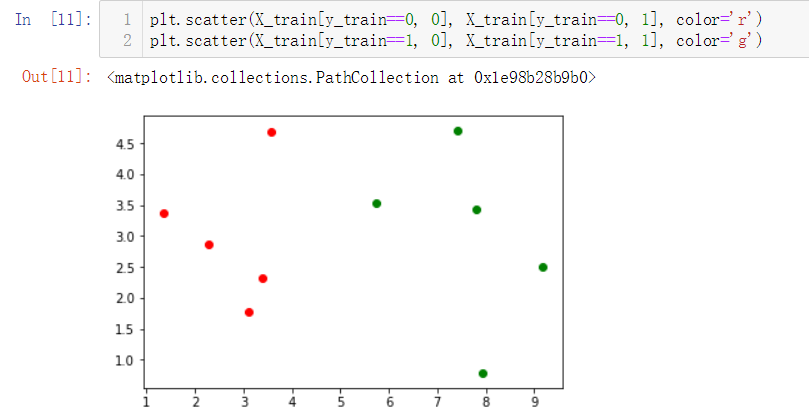
No.5. kNN算法的目的是,假如有新的数据加入,需要判断这个新的数据属于数据集中的哪一类
我们添加一个新的数据,重新绘制散点图

No.6. kNN的实现过程——计算x到训练数据集中每个点的距离
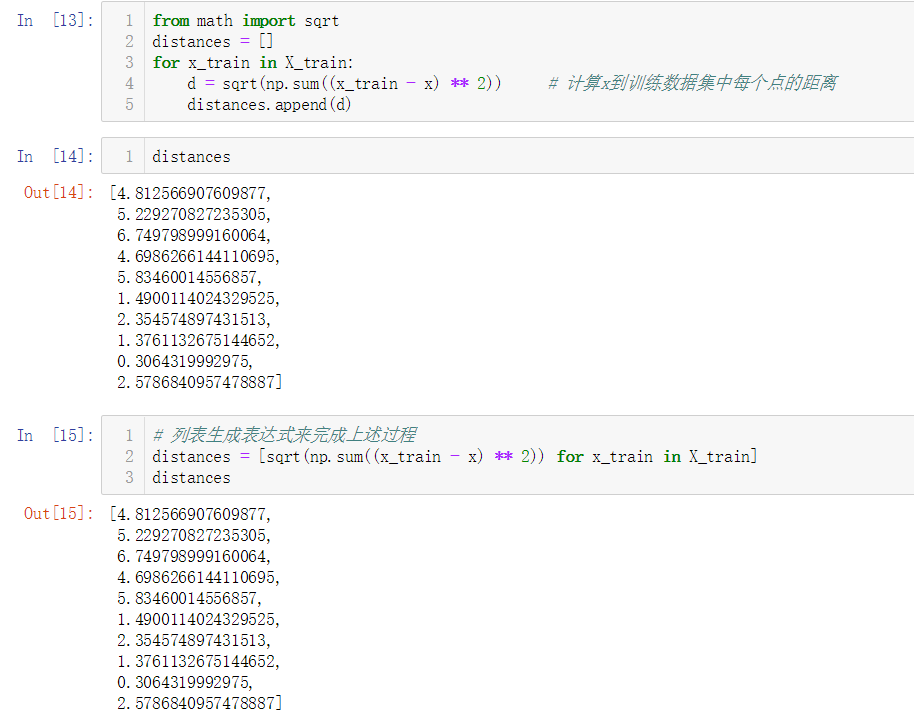
No.7. kNN的实现过程——使用argsort来获取距离x由近到远的点的索引组成的向量,进行保存

No.8. kNN的实现过程——指定需要考虑的最近的点的个数k,并获取距离x最近的k个点的y_train中的数据

No.9. kNN的实现过程——统计出属于不同类别的点的个数,并选择票数最多的类别
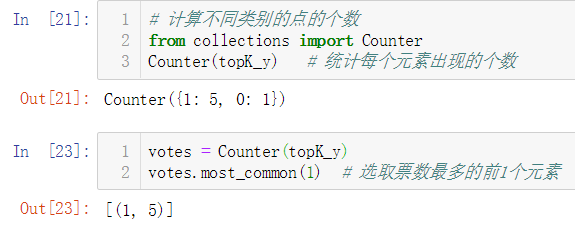
No.10. kNN的实现过程——对预测结果进行保存,结束。

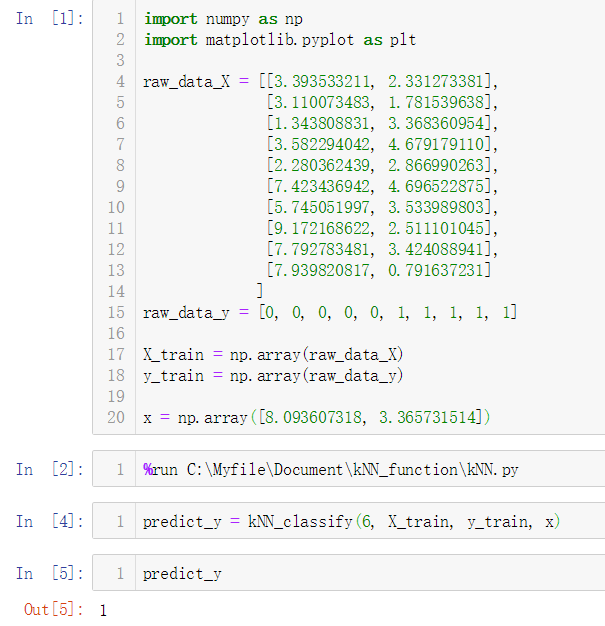
No.11. 我们可以将kNN算法封装到一个函数中

No.12. 然后我们处理好测试数据,直接调用这个封装好的函数,就能得到预测结果
No.13. 机器学习的一般流程

No.14. k-近邻算法的特殊性

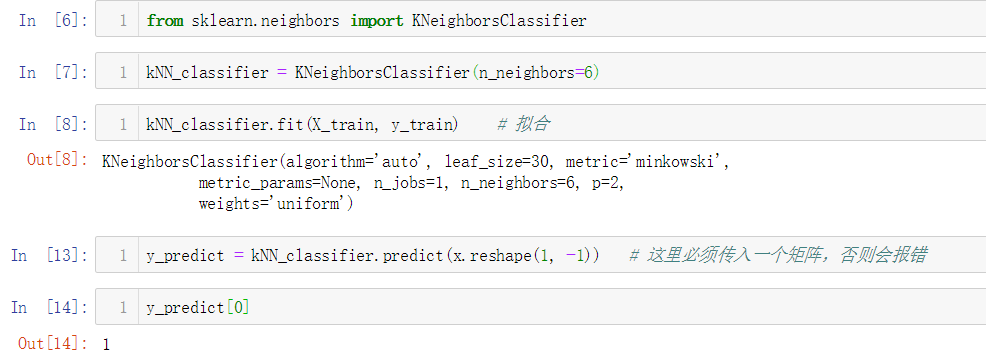
No.15. 使用scikit-learn中的kNN算法
No.16. 模仿scikit-learn封装自己的KNNClassifier类

No.17. 调用自己封装的KNNClassifier类

No.18. k近邻算法的缺点
- 缺点1:效率低下,这也是kNN算法的最大缺点,如果训练数据集有m个样本,n个特征,则预测一个新数据的时间复杂度为O(m*n)
- 缺点2:高度数据相关,容易导致预测出错
- 缺点3:预测结果不具有可解释性
- 缺点4:维数灾难,随着维数的增加,原本看似很近的两个点的距离会越来越大
