No.1. 导入相关类库,并加载鸢尾花数据集

No.2. 这个鸢尾花数据集类似于一个字典,可以查看都有哪些键

No.3. 'DESCR'这个键对应的值为鸢尾花数据集的文档,简单对其进行查看
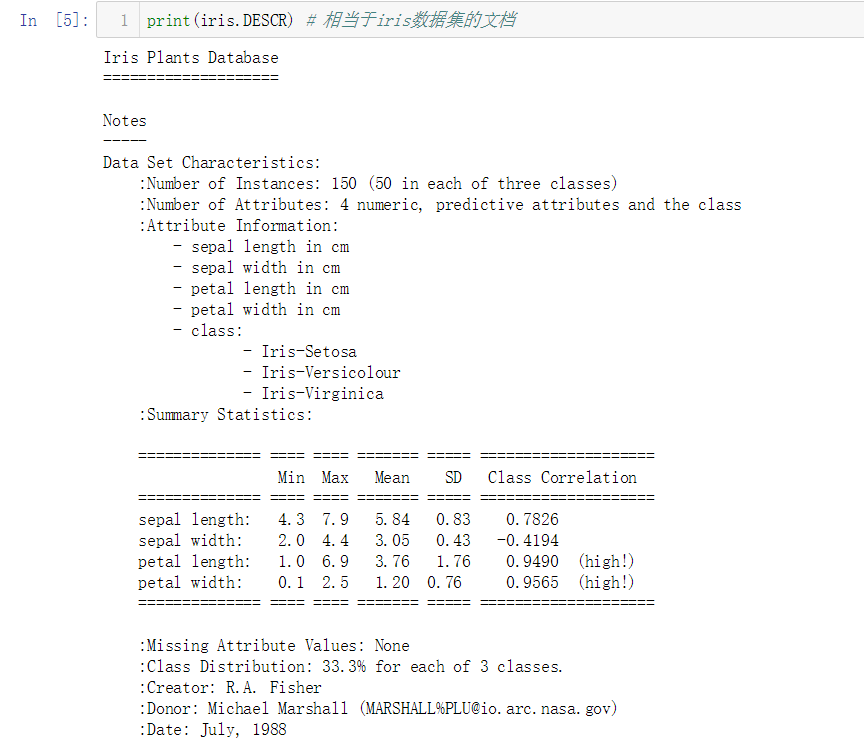
从文档中我们可以了解到,这个数据集共保存了150个鸢尾花样本;每个样本包含4个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度;共分为三类鸢尾花:Iris-Setosa、Iris-Versicolour和Iris-Virginica等等信息
No.4. 通过'data'这个键,可以访问150个样本的数据
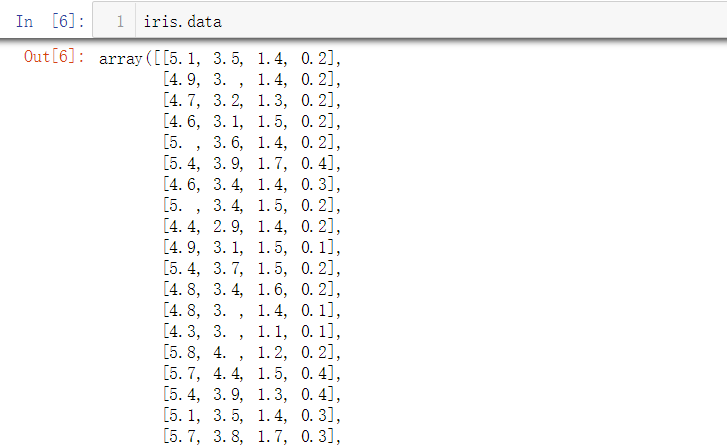
很明显,这些数据保存在一个矩阵中,我们可以检查这个矩阵的形状
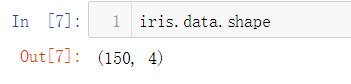
150行4列,表示150个样本,每个样本有4个特征
No.6. 每个样本所属的鸢尾花类别,通过索引的方式保存在一个向量中,可以通过'target'这个键进行访问
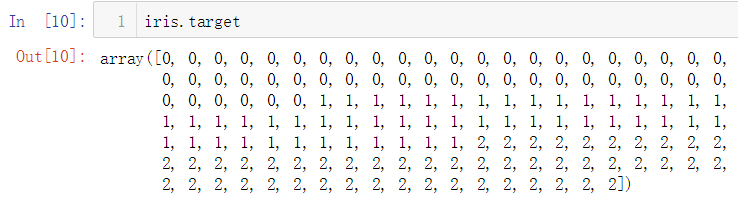
No.7. 相应的,每个索引所指代的鸢尾花名称保存在另一个向量中,可以通过'target_names'这个键进行访问

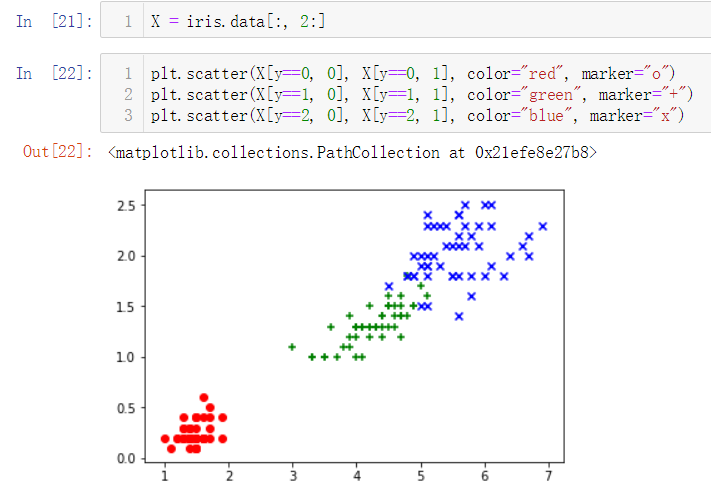
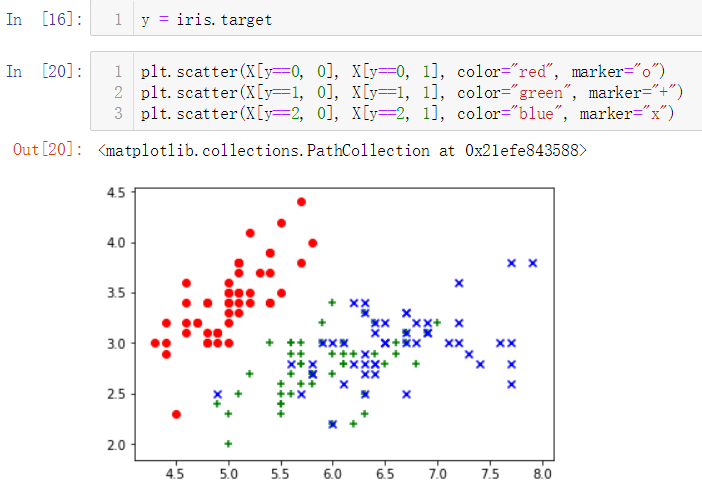
No.8. 我们可以尝试选取鸢尾花的前两个特征绘制散点图

No.9. 添加筛选条件,对不同种类的鸢尾花添加不同样式
No.10. 我们再试着绘制鸢尾花的另外两个特征的散点图