Abstract
目的: 尽量通过于一检查
工具: Skyfire
特色:使用现有的code samples学习概率性CFG,再用之生成分布很好的种子
实验:
将Skyfire生成的种子输入AFL中
对象: XSLT, XML引擎
效果:
- 能生成well-distributed inputs
- 极大增加了code coverage
- 在JS和IE11上总共发现了19个新memory corruption bugs(16个新的vulnerabilities), 32个DOS bugs
Intro
P1: Fuzzing广被应用
P2: 介绍了测试用例;测试用例生成;mutation-based和generation-based;taint analysis;symbolic execution;
P3: 在结构化数据上guided mutation-based的不足;syntax checking
P4: 挑战: 生成semantic valid test case;
P5: Grammar-based fuzzing;仍然存在的问题: 需要提供人力书写的非常麻烦的语法
P6: 介绍工具: Skyfire
- 从corpus中自动学习语法和语义信息
- 能用这些信息来fuzz需要结构化输入的程序
skyfire与现有mutation-based工具的关系(互补);与generation-based工具的关系(改进-无需人力)
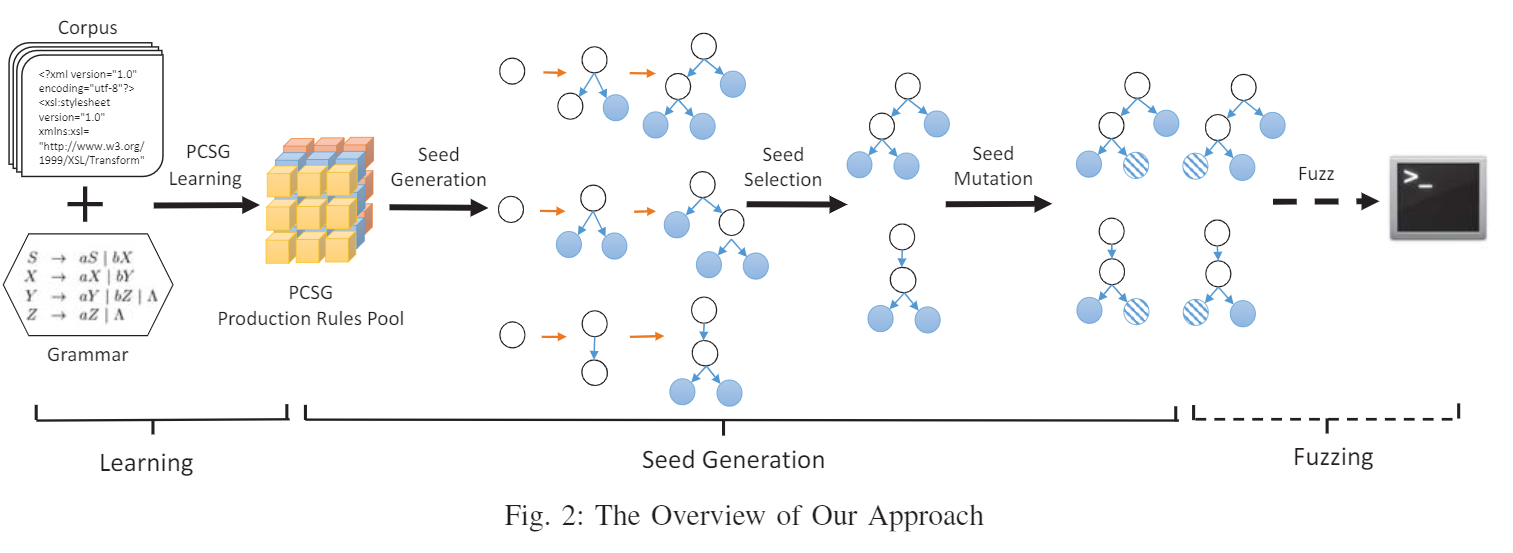
P7: 输入: corpus + grammar
基本步骤:
- 将corpus中的sample转化为AST,学习PCSG
- 注意这里上下文敏感,因此可以学到context信息
- 生成种子-不断生成直到到达no-terminal symbols remained
- 变异种子:把叶节点转化为对应的类型的
Approach
A. Target Programs
- 定义CFG
- 稍微介绍了XSL格式,以及其所需满足的semantic rule

B. Overview
三个目标以及为甚么要达成对应目标:
- correct seeds
- diverse seeds
- uncommon seeds
III PCSG Learning
A. PCSG
结构化输入一般都有很多需要满足的semantic rules,不过fuzzers一般只会满足其中一部分,一方面是因为semantic rules难以书写生成器,另外一方面也能生成更多元化的invalid test cases
例3: 用一棵XSL AST来举例说明实际存在的Semantic Rules
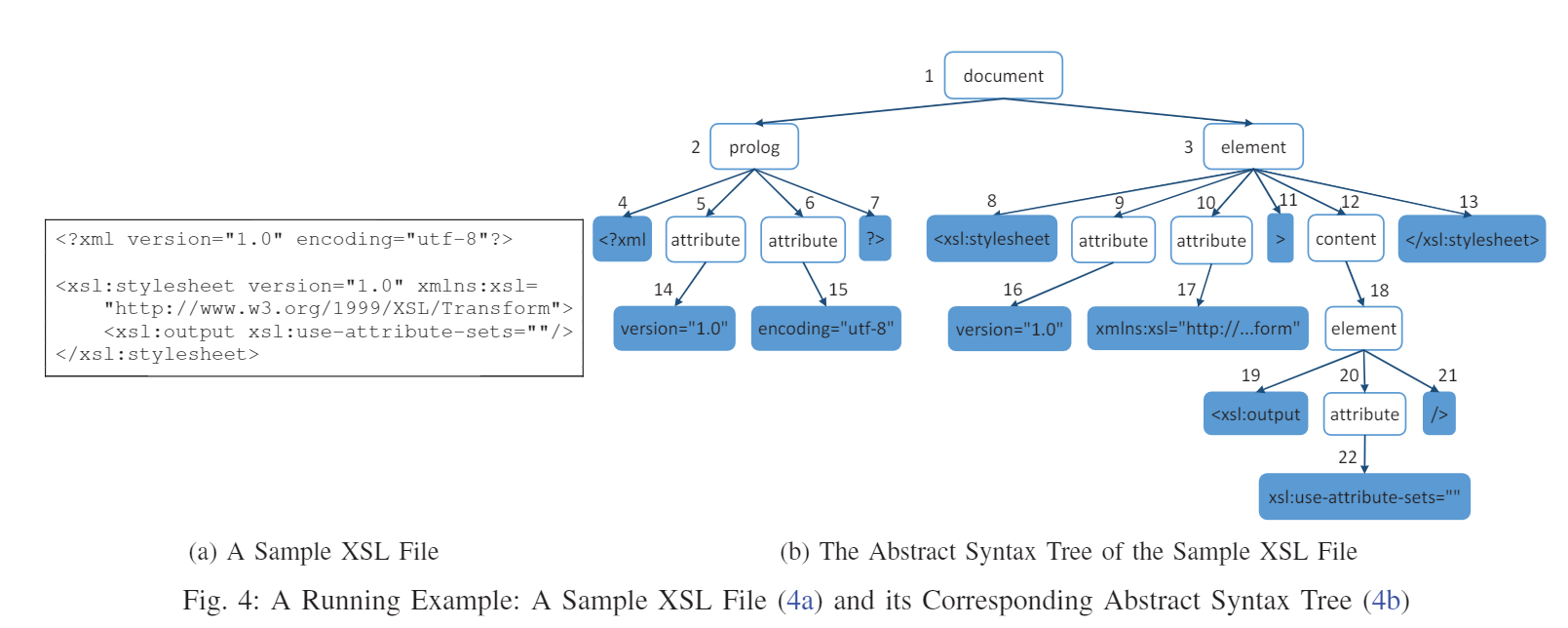

定义CSG,注意这里的上下文分别是[祖祖父节点类型,祖父节点类型,父节点类型,第一个兄弟结点的值或者类型(如果值为null)]

定义PCSG:
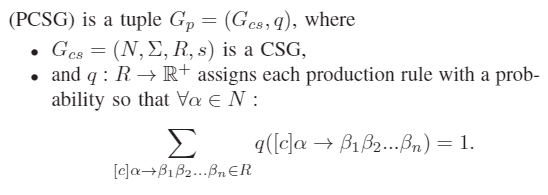
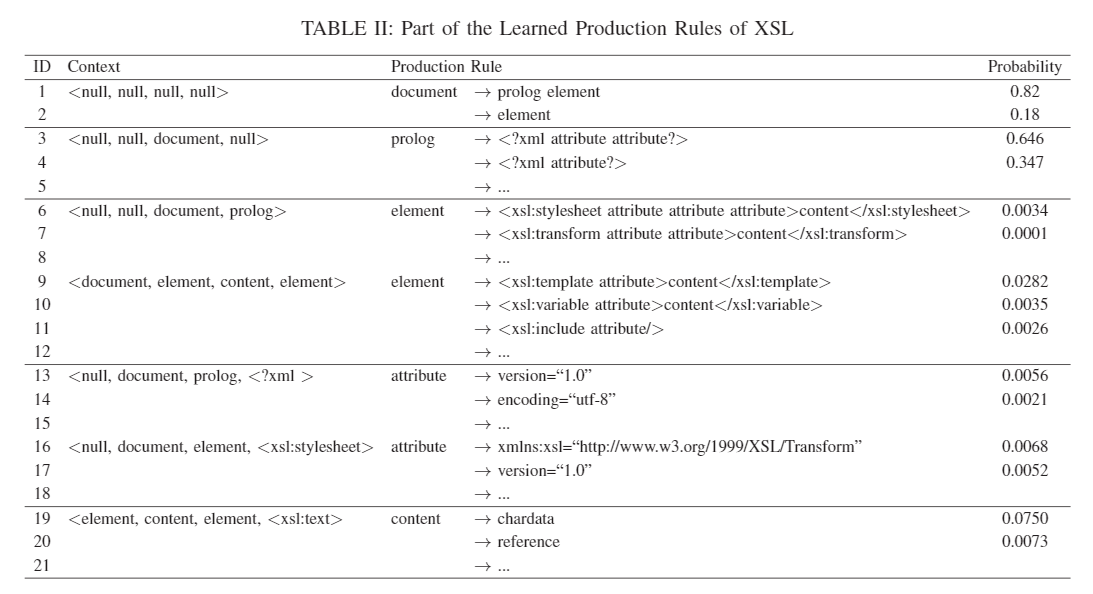
B. Learning a PCSG

IV Seed Generation
random left most deviation
需要解决的两个问题:
- 生成过程可能不会停止
- 生成的结果可能过于复杂
为此: - 偏好概率更低的规则
- 偏好频率更低的规则,同时限制同一条production rule使用的次数
- 偏好更加简单的规则
- 限制整体使用的规则数目
B. Seed Selection
- 对于开源项目,使用gcov来获取函数的line coverage和function coverage;对于闭源项目,使用PIN来获取