Abstract
特点: 基于覆盖率,基于语法规则的fuzzing
目标: 自动生成精确的测试数据
面向程序: 如编译器等
论文主体将以一个面向教育的编译器为例展开解释
目前研究: 结合fuzzing和test-case reduction,比如delta-debugging的变体
关键技术bonsai fuzzing: 与其最小化复杂的测试集,不如直接使用迭代深化的策略生成准确的测试样例
效果: 在与现有技术达到相同代码覆盖率和错误检查能力的同时,产生的输入要小16-45%。
1. Intro
本文的灵感源自于ChocoPy,相当于静态类型的python,实现了一些python特性的子集。学生需要写parser, type checker和code generator,而老师需要自动打分,由此诞生了这个项目。这要求使用的测试数据集需要保证简单和足够能让人理解。
已有工作:
- 7,8,9;但主要集中在生成函数调用序列的同时保证整体testcases数量最少。
- 我方: 每个test case的大小都减少,而不是减少整体test case数量
- 13,14,15,16;structured input领域中目前主流的方法是首先执行fuzzing,然后再执行test-case reduction。比如CSmith和C-Reduce。
- 缺点:混乱;生成的结果很难理解;
- 为此,delta-debugging等方法只做local optimization
- 缺点:混乱;生成的结果很难理解;
本文特点:以bottom-up的策略生成corpus
- 采样语义有效的输入
- 利用resulting devrivation trees(结果生成树) 上面identifiers, linear repetations和nested expansions数目的限制来生成具体的fuzzer
本文在Coverage-guided bounded grammar fuzzers(CBGFs)上定义了偏序关系,考虑到数目有限,这些CBGFs能够构成一个高度有限的格,这个格满足格中每个CBGF产生的有效种子都会是偏序大于它的fuzzer的初始种子集的一部分。很容易理解,在格的底部是无法生成好种子的fuzzers,在格的顶部是生成数据集规模特大的fuzzers。
实验效果:
- 达到其他reduction方法98.5%代码覆盖率和98.8%mutation score的同时,生成的测试数据规模小42.5%
- 在Google Closure Compiler上,16.5% size reduction

2. Background and motivation
测试程序: typechecker
对应功能: 对于valid program,应当输出type annotated AST所构成的json文件,对于invalid program,则是输出错误信息和对应的line number
问题定义: 给定syntax定义,一份reference compiler implementation和其他设置,为typechecker通用地自动生成全面,准确,语法有效的测试集。
3. Prior work and challenges
A. Systematic Testing
1. Bounded Exhausting Testing
知名工具: Korat; TestEra; ASTGen; UDITA
特点: 使用各具特色的优化,以一定的长度限制系统性生成输入
在data structure相关的库中,或者驱动自动重构工具中,都很有效,但是对于编译器这类的任务,比如ChocoPy,就无法胜任。
以ChocoPy为例,即使只考虑一个user-defined identifier, 每个块只能放2句话,block或者expr迭代的深度不能超过2,其状态也达到了1e85量级

2. Input Structure
主要思路:枚举k-paths
该方法适用于测试parser,但是在typechecking和语法分析相关的程序上效果并不好
要测ChocoPy,至少k=12,也会带来一定负担
3. 符号执行
知名工具: JPF-SE
系统性地使用符号执行来探索输入空间,使用constraint solvers来到达指定分支。
该方法主要适用于覆盖定长的程序路径集合,缺点是指数型复杂度
在ChocoPy上无法使用
B. Fuzz Testing
挑战1: 生成足够复杂的输入
为此:Bonsai综合使用了多种fuzzing算法的变体
挑战2:输入通常大而且难读
为此:Bonsai设计了机制使得输入精确可读
1. Converage-Guided Fuzzing
知名工具:AFL;LibFuzzer
目标:最大化code-coverage
适用于输入是二进制数据的
缺点:效率不高
2. Specialized Compiler Fuzzing
知名工具:CSmith;Palka等测试Haskell;Dewey等测试Rust使用Constraint Logic Programming
缺点:不够通用
3. Grammar-based Fuzzing
本文支持EBNF
4. Semantic Fuzzing
知名工具: Zest;Nautilus;Superion
本文: 使用Zest
C. Test-Case Reduction
找到展示出指定行为的最小数据集是NP-hard。
Delta Debugging等工具能够以O(n2)找到局部最小解
缺点: 直接随机删除一些字符或者添加一些字符的策略使得大部分输入都是语义无效输入
升级为Hierarchical Delta-Debugging(HDD)
基本思路: 在AST上做DD
接着,本文给出了两个使用HDD前后的例子,这次运行花费了30秒,使得test case规模缩小了50%。

IV. Bonsai Fuzzing
主要借用了CBGF规模化的性质,BonsaiFuzzing的基本思路
用Fig6,7,8展示了Bonsai Fuzzing的效果,强调without knowledge of any typing rules


A. Bounded Grammar Fuzzing
介绍了主要的3个bounds: #identifier, 列表长度,迭代深度
引入了文法相关的符号G=(T,N,S,P),定义了程序集,指出每个程序都有idents(p), items(p)和depth(p)三个限制
B. Coverage-Guided Bounded Grammar Fuzzing
引入(F_{m,n,d}^{G, p})

C. Bonsai Fuzzing
定义了CBGF集合:
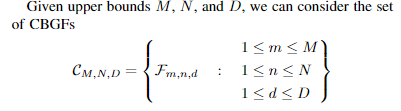
定义了偏序关系
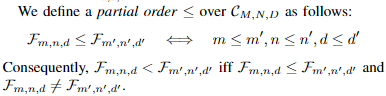
定义了前驱和后继
D. Bonsai Fuzzing with Extended Lattice
定义restricted-CBGF为仅仅保留有valid inputs的CBGF,而unrestricted-CBGF为可以保留unvalid inputs的。

增加了一维限制状态