Abstract
- Task: Binary code similarity detection
- 传统: graph matching algo
- 缺点: slow & inaccurate - 新法(本文所属): control-flow graph + (人工)筛选的特征 + GNN-> graph embedding
- 本文:
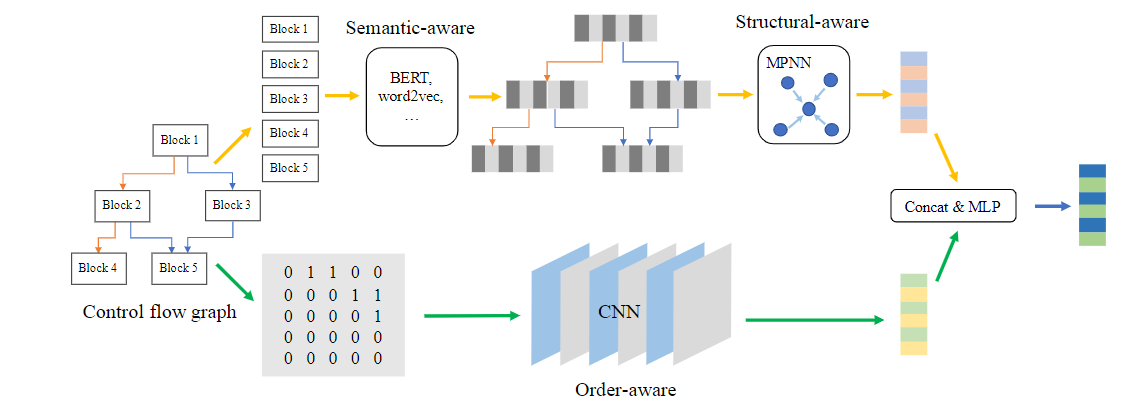
1. semantic-aware neural network
2. BERT预训练: 1个token-level, 1个block-level,2个graph level
3. 认为CFG节点的顺序信息很重要,因此在邻接矩阵上使用CNN学习以获取order特征 - 实验:
- 数据: 2tasks + 4 datasets
- outperforms
Introduction
现有NN方法
- Gemini等: Structure2vec + siamese architecture
Siamese neural network(also called twin neural network)
在两个用来比较的输入上使用相同的权重一起计算从而得到相似性度量的方法。
一般先算其中一个输出向量,得到baseline,然后再获取另一个输出向量并得到相似度度量
有点类似局部敏感hash
常用于object tracking这一类需要在大量候选中寻找相似结果的task
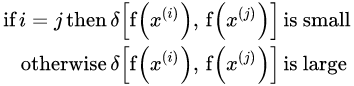
局限:
-
每个基本块都被表达是low-dimensional embedding,会导致语义信息损失?
-
没能考虑到节点顺序信息
- 认为相同功能的cfg其实block顺序改变是比较小的
- "当在不同平台上编译相同功能时,节点顺序通常不会发生太大变化。大多数节点顺序更改是添加节点,删除节点或交换多个节点"
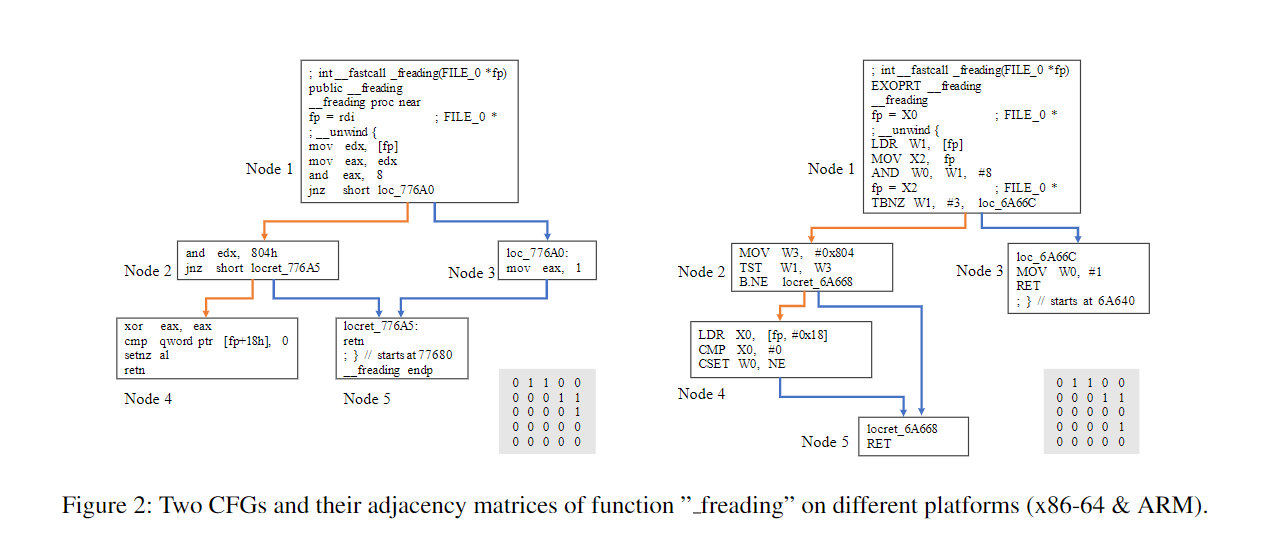
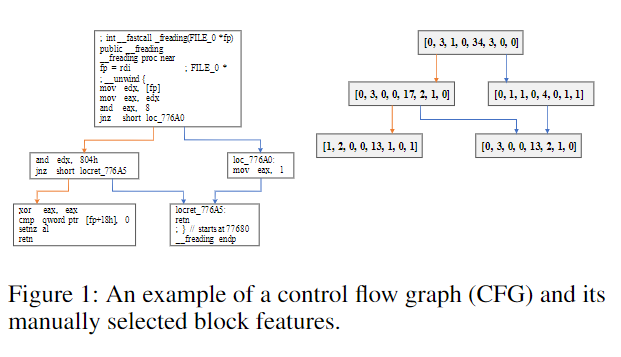
本文工作:
- semantic aware
- 把基本块中的token视为words,把基本块视作句子
- Massarelli, 2019: 使用word2vec来训练基本块中的token embeddings + attention机制来获取block embedding
- Zuo等,2018: 从机器翻译中获取灵感,学习跨平台的semantic relationship
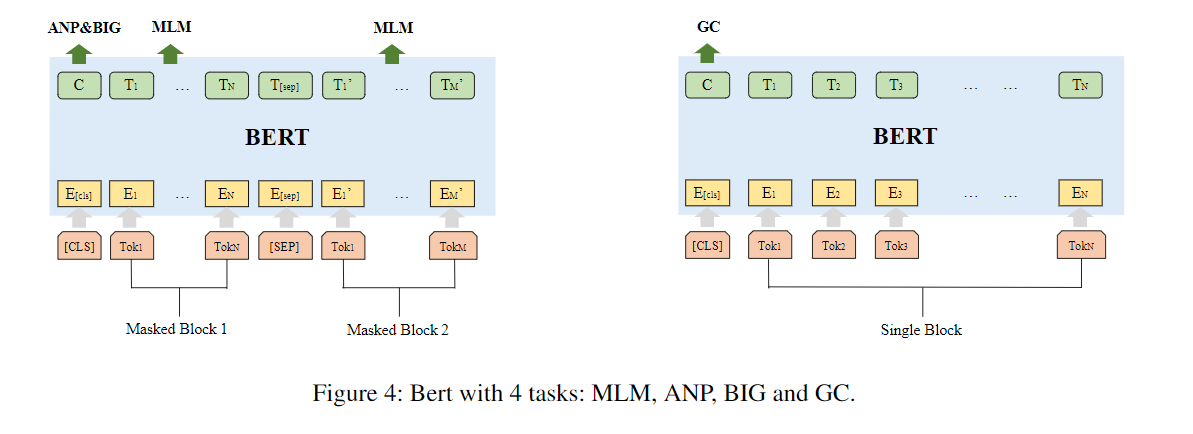
- 本文:执行以下任务学习以获取合理的block embeddings
1. token level: 按照BERT流程,首先mask the tokens来pretrain(masked language model task)
2. block level: 把相邻的block embedding放在一起训练(adjacency node prediction node, ANP)
3. graph level#1:学习两个sampled blocks是否在同一张graph中,有助于模型理解块与图之间的关系
- 后面又说是在算两个块是否相邻,感觉这个合理一丁点
4. graph level#2:判断图所对应的系统平台和编译等级
- 接着fine tune - structural aware
- MPNN + GRU - order-aware
- 3-layer CNN + adjacency matrices
Our model
获取graph semantic & structual embedding (g_{ss}) 和 order embedding (g_o), 接到一起用MLP层获取最终graph embedding
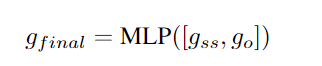

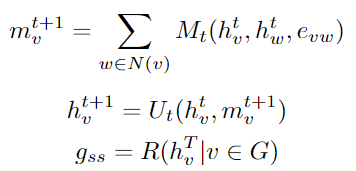
实际上:((Xu et al. 2018) has proved that sum function is the best choice for readout function R)
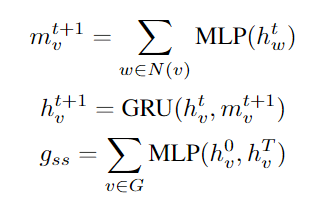
Results
两个任务:
- 跨平台
- 图分类(???????)
模型参数,训练参数,Evaluation metrics:Task1(Rank1, MRR(ean reciprocal rank) Task2(accuracy)
居然只与Gemini比?
Q: 不知道这个dataset statistics到底指什么,basic blocks?但是程序数目过少不就很快过拟合?