Abstract
复杂的数据库优化往往会导致逻辑bugs
本文提出NoREC(构造不优化的参照引擎)算法
主要方法: 将query返回值与不加优化的dbms返回值之间的差异做对比
困难:DBMS实现方式很多,难以直接获取不加优化的执行结果
Solution: 将原查询重写为一个无法进行优化必须每行查询的格式
实验:
- 对象: PostgreSQL, MariaDB, SQLite, CockroachDB
- 结果: 159个新bugs(其中141个已经fixed)
- 51个optimization bugs
- 108个其他bugs或者crash bugs
Intro
已有工作
- 作者之前的工作Pivoted Query Synthesis
- 问题: 只能考虑1行,无法找到类似不该重复读取的记录重复读到了的情况
- RAGS: 用多个DBMS验证当前DBMS
- 问题: DBMS方言不同,只能验证每个DBMS都支持的核心SQL
本文工作
提出了NoREC,将带where的Query转化为检查每行record是否符合where子句的query,使得原query中获得的数据条数相当于改后query查询到的true的个数
例子如下:

在SQLITE中, query1没能读到数据,但是经过改变的query2读到了数据,因此检查出bug
Background
本文工作无法用来测试No-SQL,因为这些数据库不能完整支持SQL语法,但是可以用来测试NewSQL,因为NewSQL尝试实现NoSQL同等的scalability同时兼容SQL语法
目前已有的一些测试思路:
Automatic testing: 关键在于test case和test oracle
Optimizations in DBMS: Each DBMS typically provides a query optimizer that inspects a query, potentially simplifies it, and maps it efficiently to physical accesses.
Differetial Testing: RAGS类似的思路。Slutz实现了RAGS的思路
Controlling optimization in DBMS: 对比优化前后的执行结果,在编译器测试上已有使用,但是在DBMS上,大部分的优化没法自动关闭
Approach
基本流程:
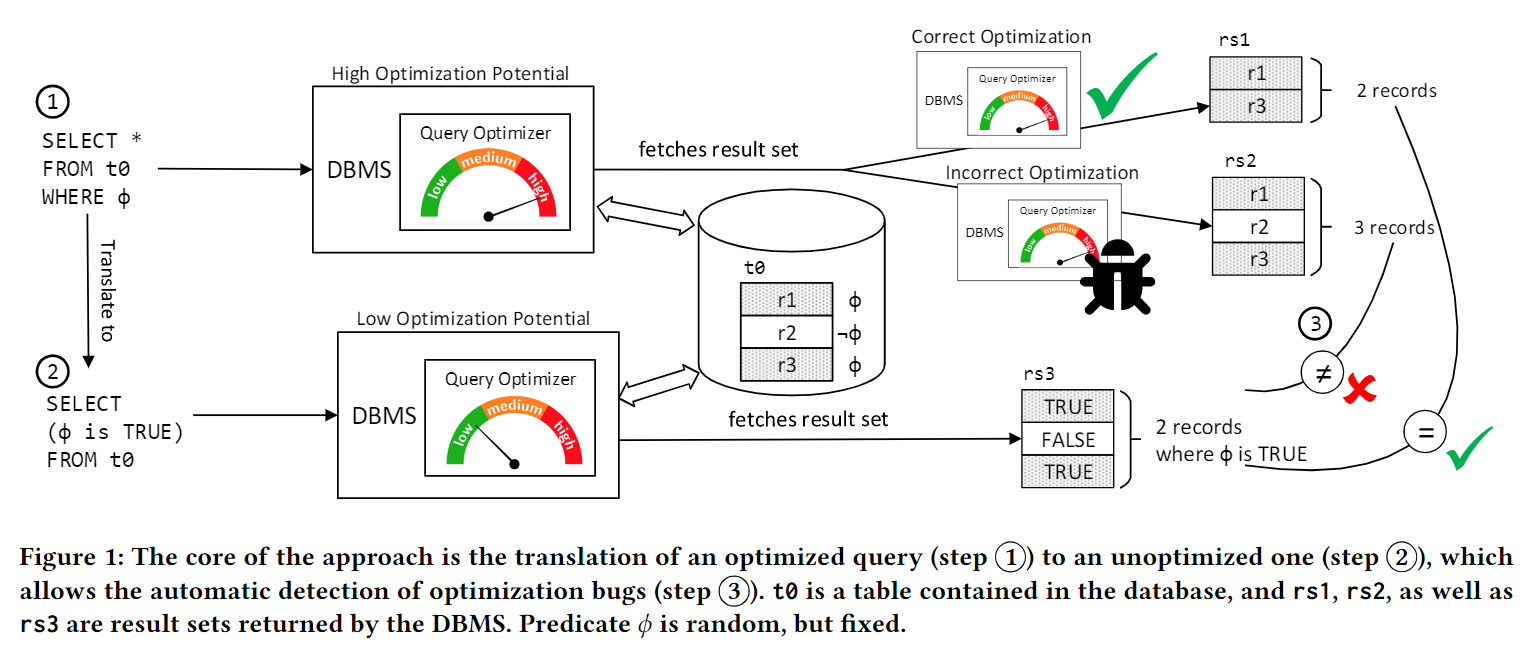
3.2 Translating the Query
当将原Query翻译为非优化Query时,除了简单的where语句移到select后面,还有如下拓展可以使用:
- 从多个表中读取
- join子句:join子句可以直接在非优化query中被拷贝,保持不变,当然,移动到on子句也是一种方法
- order by: 在非优化query中可以直接忽略
- group by: 需要添加一个query来读中间结果的counts
3.3 Determining the Row Count
计算原查询条数有两种方式1. 直接iterate 2. 使用aggregate function,如count。这两种是混用的
本文也思考过是否要比对原查询和实际查询的实际内容,然而作者的经验是这种bug是比较少见的,因此本文只对比返回数据的条数
3.4 Corner Cases and Limitations
本节探讨了本文没法覆盖到的bugs类型,以及三个看似bug但是数据库不认为是bug因此可以放在那里不管的corner cases
Ambigious queries
有些查询本身就有二义性,优化或者非优化返回的结果虽然不一样,但是合法,比如subqueries
措施: 不生成subquery
Nondeterministic functions
措施: 避免和随机数或者当时时间有关的查询
Other features
措施: 避免处理distinct子句和在多条记录上计算结果,比如aggregate或者window functions
Corner case1: Number comparison in SQLite
在sqlite中使用distinct会认为浮点数和与其值相同的整数,比如0.0和0,认为是同一个数。query1中获取到的就是0这条记录,v0.c0 0.1经过拼接得到0.01,在条件中对应TRUE,但是query2中获取到的就是0.0这条记录,v0.c0 0.1经过拼接得到0.00.01,在条件中对应False。

Corner case2: Input Columns in SQLite
如果把stat.aggregate放在where子句中,就会使得conf option中对应值为True,但是在select子句中则不会

Corner case3: Ambigious group bys
在SQLite中group by具有二义性,与optimizer hint,比如unlikely连用时会导致bug。
Q: 具体是什么样的二义性?

3.5 Query and Database Generation
用SQLancer
4 Evalutation
4.1 Methodology
- 为什么选这四个数据库来测试
- 测试过程中付出的精力不同的原因:有些回复及时,测得比较深入
- 这些数据库自身已有的测试,如SQLITE已经实现了条件100%覆盖,还写了自身的out-of-memory testing, IO error testing, crash testing, 组件失效testing, fuzz testing, dynamic analysis。CockroachDB已经有一个基于SQLSmith改编的用go实现的query generator
- 测试方法: 测试时是有软件开发者和自身的反馈,一轮轮迭代产品Sqlancer,此外,使用了C-reduce来尽量生成可理解的bug重现。
4.2 Selected Bugs
bug举例
4.3 Bugs Overview
找到了多少bug,多少个被comfirmed, 多少个被fixed,多少个是逻辑bugs,多少个是顺带得到的crash bugs,比如与order by相关的bug有多少,具体的软件版本
4.4 Comparison to PQS
对比难点,方法(如何将NoREC的有用测试用例转为PQS的,反之亦然),只被NoREC覆盖的bugs比,各自发现的bug种类
5 Discussion
- DBMS开发者对本软件的反馈
- Bug importance: 承认发现的不少bugs是程序员不太可能会写的SQL,但是即使是这种bugs,考虑到SQL生成器/code generator的存在,也是有可能自动生成的。
- Handling of joins: 现在已经够用,但是TODO WORK
- Code coverage: 认为高的代码覆盖率并不一定特别重要
- bugs种类: 认为不被发现的logic bugs才是更可怕的