建表
1 drop table if exists stu; 2 create table stu ( 3 id integer, 4 name varchar(10) 5 );
插入数据
1 insert into stu values (1,'Jason'); 2 insert into stu values (2,'Bob'); 3 insert into stu values (3,'Bob'); 4 insert into stu values (4,'Bob'); 5 insert into stu values (5,'Mike'); 6 insert into stu values (6,'Mike'); 7 insert into stu values (7,'Jack'); 8 insert into stu values (8,'Jack');
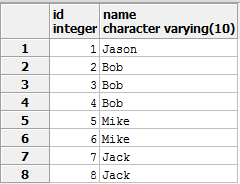
删除name相同的重复数据
1 delete from stu a 2 where exists ( 3 select 1 from stu b where a.name = b.name and b.id > a.id 4 );
