根据表格生成文本,是文本生成的一个研究方向。
本文以Puduppully的论文“ Data-to-Text Generation with Content Selection and Planning”及代码https://github.com/ratishsp/data2text-plan-py为例,了解文本生成的各个环节。
Puduppully, R., Dong, L., & Lapata, M. (2019). Data-to-Text Generation with Content Selection and Planning.
AAAI 2019.



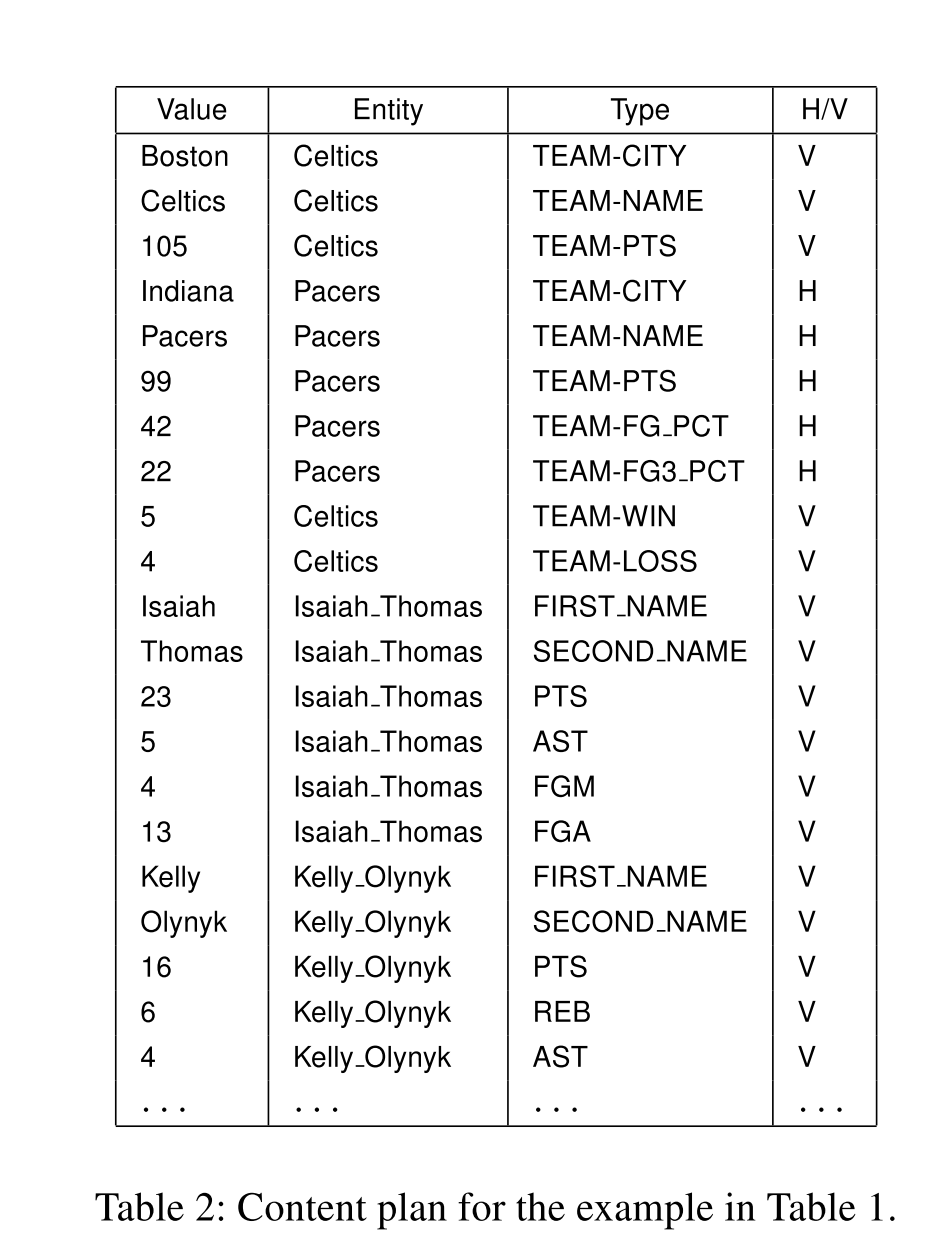
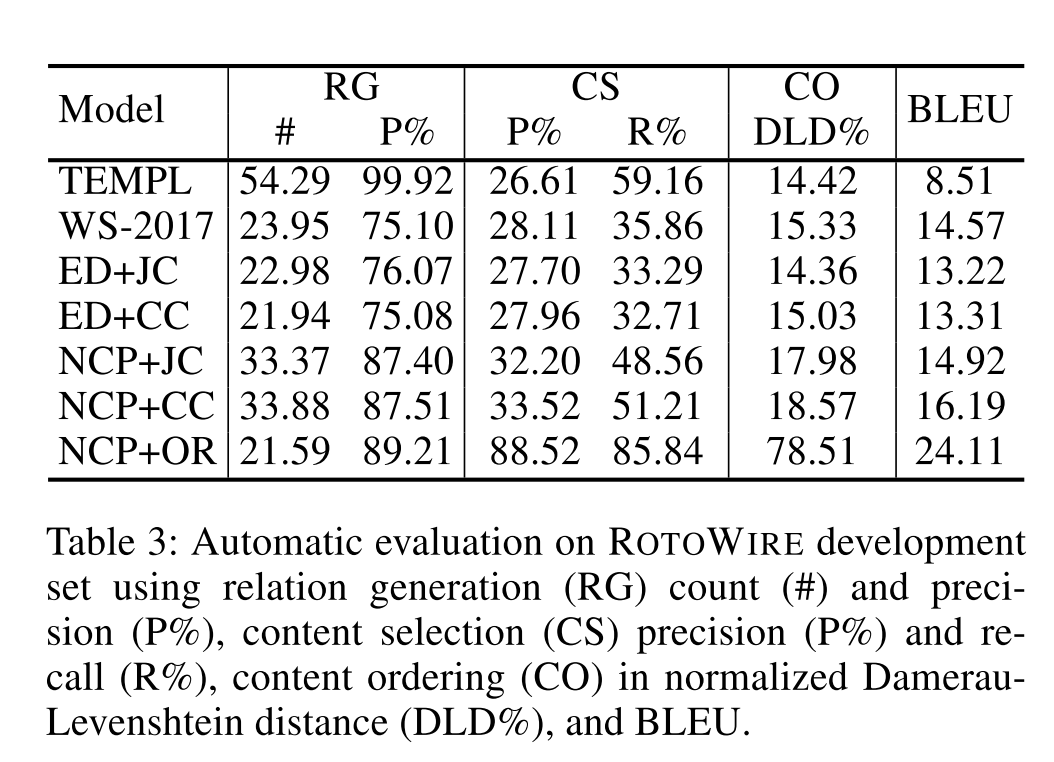
整个数据的处理过程为:
(1)原始数据
论文中数据采用的是boxscore-data,可以从https://github.com/harvardnlp/boxscore-data下载。这是篮球比赛的数据。

(2)预处理-创建数据集
运行script目录的create_dataset.py文件,生成数据集,即txt文件。

注意:这个步骤的输出文件,可以直接从网上下载:https://drive.google.com/open?id=1R_82ifGiybHKuXnVnC8JhBTW8BAkdwek
是当前目录的rotowire文件夹。作者亲自上传的数据。
(3)预处理-转成pt文件
工作目录:
/home/xuehp/git/data2text-plan-py/
conda activate data2text
export $BASE=./
export IDENTIFIER=cc
mkdir -p preprocess/roto
python preprocess.py -train_src1 $BASE/rotowire/src_train.txt -train_tgt1 $BASE/rotowire/train_content_plan.txt -train_src2 $BASE/rotowire/inter/train_content_plan.txt -train_tgt2 $BASE/rotowire/tgt_train.txt -valid_src1 $BASE/rotowire/src_valid.txt -valid_tgt1 $BASE/rotowire/valid_content_plan.txt -valid_src2 $BASE/rotowire/inter/valid_content_plan.txt -valid_tgt2 $BASE/rotowire/tgt_valid.txt -save_data $BASE/preprocess/roto -src_seq_length 1000 -tgt_seq_length 1000 -dynamic_dict -train_ptr $BASE/rotowire/train-roto-ptrs.txt
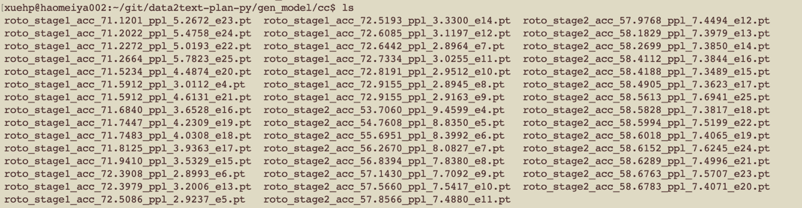
完成之后,生成pt文件:

(4)训练模型
工作目录:
/home/xuehp/git/data2text-plan-py/
conda activate data2text
export $BASE=./
export IDENTIFIER=cc
mkdir -p gen_model/cc
python train.py -data $BASE/preprocess/roto
-save_model $BASE/gen_model/$IDENTIFIER/roto
-encoder_type1 mean -decoder_type1 pointer -enc_layers1 1 -dec_layers1 1
-encoder_type2 brnn -decoder_type2 rnn -enc_layers2 2 -dec_layers2 2
-batch_size 5 -feat_merge mlp -feat_vec_size 600 -word_vec_size 600 -rnn_size 600 -seed 1234
-start_checkpoint_at 4 -epochs 25 -optim adagrad -learning_rate 0.15 -adagrad_accumulator_init 0.1
-report_every 100 -copy_attn -truncated_decoder 100 -attn_hidden 64 -reuse_copy_attn
-start_decay_at 4 -learning_rate_decay 0.97 -valid_batch_size 5
开始训练,模型文件保存到gen_model/cc目录
作者还提供了训练完毕的模型,可以从https://www.dropbox.com/sh/vo5wb2fuq7m0bk0/AABikW0KomOKIor24wD8VSFWa?dl=0下载
所以训练的步骤也可以略过
(5)使用模型进行预测
MODEL_PATH=gen_model/cc/roto_stage1_acc_71.2664_ppl_5.7823_e25.pt
python translate.py -model $MODEL_PATH -src1 $BASE/rotowire/inf_src_valid.txt -output $BASE/gen/roto_stage1_$IDENTIFIER-beam5_gens.txt -batch_size 10 -max_length 80 -min_length 35 -stage1
预测过程输出:
Loading model parameters.
('average src size', 606, 727)
PRED AVG SCORE: -0.1468, PRED PPL: 1.1582
预测结果:


共727行。这还需要词典文件进行解码才可以人工查阅。