2020-09-22
引用
Liu, Y., & Lapata, M. (2020). Text summarization with pretrained encoders. EMNLP-IJCNLP 2019 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, 3730–3740. https://doi.org/10.18653/v1/d19-1387
Text Summarization with Pretrained Encoders
Yang Liu and Mirella Lapata
Institute for Language, Cognition and Computation School of Informatics, University of Edinburgh
yang.liu2@ed.ac.uk, mlap@inf.ed.ac.uk
https://github.com/nlpyang/PreSumm.git
理由
本文探讨了BERT在自动摘要的应用,并提出了抽取式和生成式摘要的通用框架。作者通过在3个数据集进行实验,证明了BERT在抽取式摘要和抽象式摘要生成方面表现良好。
摘要
Bidirectional Encoder Representations from Transformers (BERT; Devlin et al. 2019) represents the latest incarnation of pretrained language models which have recently advanced a wide range of natural language processing tasks. In this paper, we showcase how BERT can be usefully applied in text summarization and propose a general framework for both extractive and abstractive models. We introduce a novel document-level encoder based on BERT which is able to express the semantics of a document and obtain representations for its sentences. Our extractive model is built on top of this encoder by stacking several inter sentence Transformer layers. For abstractive summarization, we propose a new fine-tuning schedule which adopts different optimizers for the encoder and the decoder as a means of alleviating the mismatch between the two (the former is pretrained while the latter is not). We also demonstrate that a two-staged fine-tuning approach can further boost the quality of the generated summaries. Experiments on three datasets show that our model achieves state of-the-art results across the board in both extractive and abstractive settings.
BERT在NLP任务中已经得到广泛使用,本文介绍BERT在抽取式摘要和抽象式摘要中的应用。提出了一个抽取式和抽象式摘要生成的通用框架,发明一种新颖的基于BERT的文档级别的编码器,可以表示文档及其句子的语义。在3个数据集进行实验,证明抽取式和抽象式摘要的效果都很好。代码见https://github.com/nlpyang/PreSumm
1 Introduction
Language model pretraining has advanced the state of the art in many NLP tasks ranging from sentiment analysis, to question answering, natural language inference, named entity recognition, and textual similarity. State-of-the-art pretrained models include ELMo (Peters et al., 2018), GPT (Radford et al., 2018), and more recently Bidirectional Encoder Representations from Transformers (BERT; Devlin et al. 2019). BERT combines both word and sentence representations in a single very large Transformer (Vaswani et al., 2017); it is pretrained on vast amounts of text, with an unsupervised objective of masked language modeling and next-sentence prediction and can be fine-tuned with various task-specific objectives.
语言模型应用到了情感分析、问答、自然语言推理、命名实体识别和文本相似度计算。优秀的预训练模型ELMo、GPT、BERT。BERT通过一个巨大的Transformer实现单词和句子的语义表示,它在大量文本上预训练,有一个无监督的目标,即掩蔽语言建模和下一个句子预测,并且可以根据不同的任务特定目标进行微调。
In most cases, pretrained language models have been employed as encoders for sentence and paragraph-level natural language understanding problems (Devlin et al., 2019) involving various classification tasks (e.g., predicting whether any two sentences are in an entailment relationship; or determining the completion of a sentence among four alternative sentences). In this paper, we examine the influence of language model pretraining on text summarization. Different from previous tasks, summarization requires wide-coverage natural language understanding going beyond the meaning of individual words and sentences. The aim is to condense a document into a shorter version while preserving most of its meaning. Furthermore, under abstractive modeling formulations, the task requires language generation capabilities in order to create summaries containing novel words and phrases not featured in the source text, while extractive summarization is often defined as a binary classification task with labels indicating whether a text span (typically a sentence) should be included in the summary.
自动摘要的目标是将文档浓缩到一个短的版本并保留绝大多是含义。抽象式摘要要求模型具有语言生成能力,目的是创建摘要,包含未在原文出现的新的单词或者短语;抽取式摘要一般定义为一个二分类器,标记句子是否为摘要。
We explore the potential of BERT for text summarization under a general framework encompassing both extractive and abstractive modeling paradigms. We propose a novel document level encoder based on BERT which is able to encode a document and obtain representations for its sentences. Our extractive model is built on top of this encoder by stacking several inter sentence Transformer layers to capture document level features for extracting sentences. Our abstractive model adopts an encoder-decoder architecture, combining the same pretrained BERT encoder with a randomly-initialized Transformer decoder (Vaswani et al., 2017). We design a new training schedule which separates the optimizers of the encoder and the decoder in order to accommodate the fact that the former is pretrained while the latter must be trained from scratch. Finally, motivated by previous work showing that the combination of extractive and abstractive objectives can help generate better summaries (Gehrmann et al., 2018), we present a two-stage approach where the encoder is fine-tuned twice, first with an extractive objective and subsequently on the abstractive summarization task.
We evaluate the proposed approach on three single-document news summarization datasets representative of different writing conventions (e.g., important information is concentrated at the beginning of the document or distributed more evenly throughout) and summary styles (e.g., verbose vs. more telegraphic; extractive vs. abstractive). Across datasets, we experimentally show that the proposed models achieve state-of-the-art results under both extractive and abstractive settings. Our contributions in this work are threefold: a) we highlight the importance of document encoding for the summarization task; a variety of recently proposed techniques aim to enhance summarization performance via copying mechanisms (Gu et al., 2016; See et al., 2017; Nallapati et al., 2017), reinforcement learning (Narayan et al., 2018b; Paulus et al., 2018; Dong et al., 2018), and multiple communicating encoders (Celikyilmaz et al., 2018). We achieve better results with a minimum-requirement model without using any of these mechanisms; b) we showcase ways to effectively employ pretrained language models in summarization under both extractive and abstractive settings; we would expect any improvements in model pretraining to translate in better summarization in the future; and c) the proposed models can be used as a stepping stone to further improve summarization performance as well as baselines against which new proposals are tested.
在3个单文档新闻摘要数据集验证本文想法。三大贡献:没有使用复制机制、强化学习、多通信编码器,使用最小需求模型取得了更好的结果;在抽取式和生成式摘要中,使用预训练模型;本文提出的模型可以作为进一步提高摘要性能的基础,也可以作为测试新思路的基准。
2 Background
2.1 Pretrained Language Models
Pretrained language models (Peters et al., 2018; Radford et al., 2018; Devlin et al., 2019; Dong et al., 2019; Zhang et al., 2019) have recently emerged as a key technology for achieving impressive gains in a wide variety of natural language tasks. These models extend the idea of word embeddings by learning contextual representations from large-scale corpora using a language modeling objective. Bidirectional Encoder Representations from Transformers (BERT; Devlin et al. 2019) is a new language representation model which is trained with a masked language modeling and a “next sentence prediction” task on a corpus of 3,300M words.
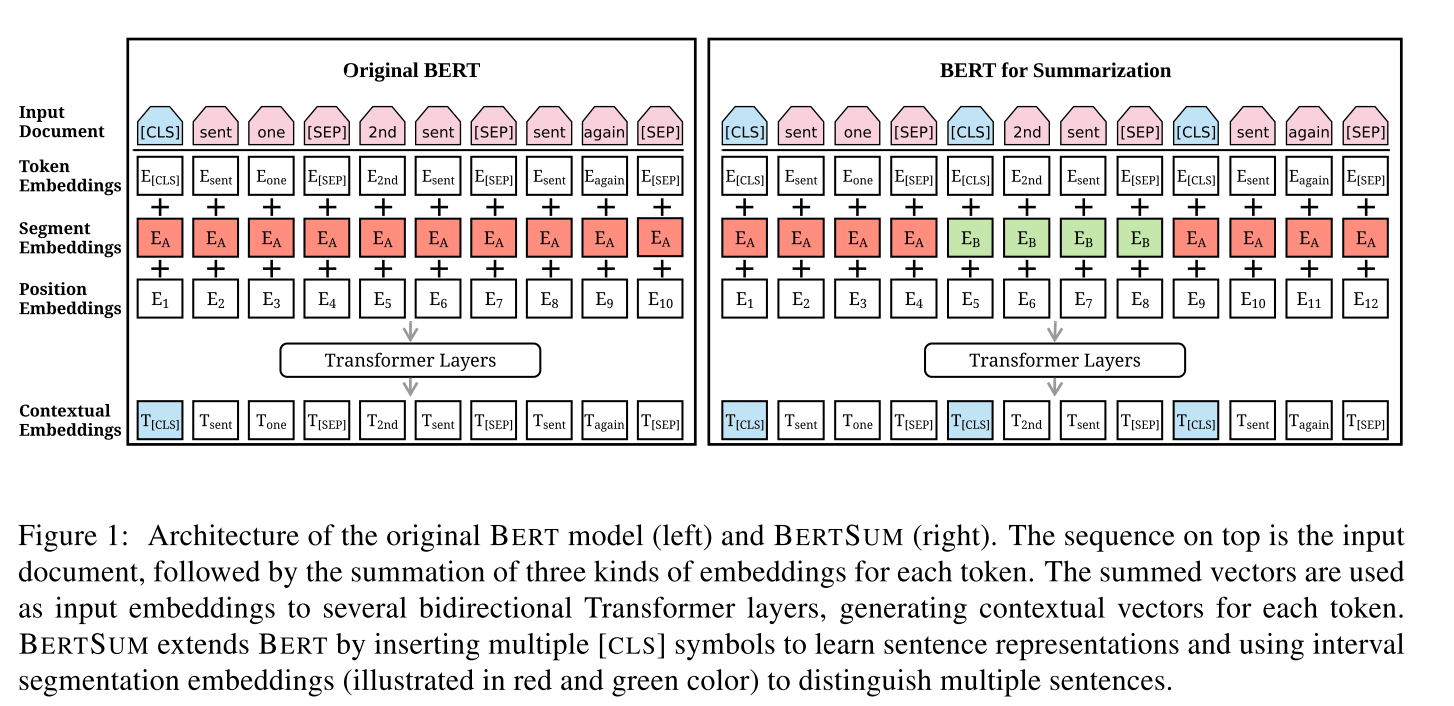
The general architecture of BERT is shown in the left part of Figure 1. Input text is first preprocessed by inserting two special tokens. [CLS] is appended to the beginning of the text; the output representation of this token is used to aggregate information from the whole sequence (e.g., for classification tasks). And token [SEP] is inserted after each sentence as an indicator of sentence boundaries. The modified text is then represented as a sequence of tokens (X = [w_{1}, w_{2}, · · · , w_{n}]). Each token (w_{i}) is assigned three kinds of embeddings: token embeddings indicate the meaning of each token, segmentation embeddings are used to discriminate between two sentences (e.g., during a sentence-pair classification task) and position embeddings indicate the position of each token within the text sequence. These three embeddings are summed to a single input vector (x_{i}) and fed to a bidirectional Transformer with multiple layers:
where (h^{0} = x) are the input vectors; LN is the layer normalization operation (Ba et al., 2016); MHAtt is the multi-head attention operation (Vaswani et al., 2017); superscript (l) indicates the depth of the stacked layer. On the top layer, BERT will generate an output vector (t_{i}) for each token with rich contextual information.
Pretrained language models are usually used to enhance performance in language understanding tasks. Very recently, there have been attempts to apply pretrained models to various generation problems (Edunov et al., 2019; Rothe et al., 2019). When fine-tuning for a specific task, unlike ELMo whose parameters are usually fixed, parameters in BERT are jointly fine-tuned with additional task-specific parameters.
2.2 Extractive Summarization
Extractive summarization systems create a summary by identifying (and subsequently concatenating) the most important sentences in a document. Neural models consider extractive summarization as a sentence classification problem: a neural encoder creates sentence representations and a classifier predicts which sentences should be selected as summaries. SUMMARUNNER(Nallapati et al., 2017) is one of the earliest neural approaches adopting an encoder based on Recurrent Neural Networks. REFRESH (Narayan et al., 2018b) is a reinforcement learning-based system trained by globally optimizing the ROUGE metric. More recent work achieves higher performance with more sophisticated model structures. LATENT (Zhang et al., 2018) frames extractive summarization as a latent variable inference problem; instead of maximizing the likelihood of “gold” standard labels, their latent model directly maximizes the likelihood of human summaries given selected sentences. SUMO (Liu et al., 2019) capitalizes on the notion of structured attention to induce a multi-root dependency tree representation of the document while predicting the output summary. NEUSUM (Zhou et al., 2018) scores and selects sentences jointly and represents the state of the art in extractive summarization.
抽取式摘要系统通过识别(并随后连接)文档中最重要的句子来创建摘要。神经网络模型将抽取式摘要视为一个句子分类问题:编码器创建句子表示,分类器预测应该选择哪些句子作为摘要。SUMMARUNNER是最早的神经方法之一,采用基于递归神经网络的编码器。REFRESH是基于强化学习的ROUGE指标全局最优化方法。最近的工作通过更复杂的模型结构实现了更高的性能。LATENT(Zhang et al., 2018)将提取摘要框架为一个潜变量推理问题,他们的潜在模型并没有最大化标准标签的可能性,而是直接最大化了给定特定句子的人类摘要的可能性。“SUMO”(Liu et al., 2019)利用结构化注意力的概念,在预测输出摘要的同时,归纳出文档的多个依赖树表示。“NEUSUM”(Zhou et al., 2018)联合打分和句子选择,代表了抽取式摘要的最高水平。
2.3 Abstractive Summarization
Neural approaches to abstractive summarization conceptualize the task as a sequence-to-sequence problem, where an encoder maps a sequence of tokens in the source document (mathbf{x} = [x_{1}, ..., x_{n}]) to a sequence of continuous representations (mathbf{z} = [z_{1}, ..., z_{n}]), and a decoder then generates the target summary (mathbf{y} = [y_{1}, ..., y_{m}]) token-by-token, in an auto-regressive manner, hence modeling the conditional probability: (p(y_{1}, ..., y_{m}|x_{1}, ..., x_{n})).
神经网络方法将抽象式摘要在概念上转化为一个序列到序列的问题,编码器将原始文档中的token序列x映射为连续的表示z,解码器以自回归的方式通过条件概率逐个token生成目标摘要y。
Rush et al. (2015) and Nallapati et al. (2016) were among the first to apply the neural encoder decoder architecture to text summarization. See et al. (2017) enhance this model with a pointer generator network (PTGEN) which allows it to copy words from the source text, and a coverage mechanism (COV) which keeps track of words that have been summarized. Celikyilmaz et al. (2018) propose an abstractive system where multiple agents (encoders) represent the document together with a hierarchical attention mechanism (over the agents) for decoding. Their Deep Communicating Agents (DCA) model is trained end-to-end with reinforcement learning. Paulus et al. (2018) also present a deep reinforced model (DRM) for abstractive summarization which handles the coverage problem with an intra-attention mechanism where the decoder attends over previously generated words. Gehrmann et al. (2018) follow a bottom-up approach (BOTTOMUP); a content selector first determines which phrases in the source document should be part of the summary, and a copy mechanism is applied only to preselected phrases during decoding. Narayan et al. (2018a) propose an abstractive model which is particularly suited to extreme summarization (i.e., single sentence summaries), based on convolutional neural networks and additionally conditioned on topic distributions (TCONVS2S).
Rush et al. (2015) and Nallapati et al. (2016) 首先将编码器解码器架构应用到文本摘要中,See et al. (2017) 通过指针生成网络(允许从原始文档中拷贝单词)增强了该模型。Celikyilmaz等人(2018)提出了一种抽象式系统,使用多个代理(编码器)代表文档,并使用分层的注意机制(在代理之上)进行解码。他们的深度沟通代理(“DCA”)模型是用强化学习端到端训练的。Paulus等人(2018)还提出了一种用于抽象摘要的深度增强模型(“DRM”),该模型通过一种内部注意机制处理覆盖问题,即解码器处理之前生成的单词。Gehrmann等人(2018)采用自下而上的方法(“BOTTOMUP”);内容选择器首先确定源文档中的哪些短语应该是摘要的一部分,在解码期间,复制机制只应用于预先选择的短语。Narayan等人(2018a)提出了一种抽象模型,该模型特别适合于极端总结(即单句总结),基于卷积神经网络,附加了主题分布的条件(TCONVS2S)。
3 Fine-tuning BERT for Summarization
3.1 Summarization Encoder
Although BERT has been used to fine-tune various NLP tasks, its application to summarization is not as straightforward. Since BERT is trained as a masked-language model, the output vectors are grounded to tokens instead of sentences, while in extractive summarization, most models manipulate sentence-level representations. Although segmentation embeddings represent different sentences in BERT, they only apply to sentencepair inputs, while in summarization we must encode and manipulate multi-sentential inputs. Figure 1 illustrates our proposed BERT architecture for SUMmarization (which we call BERTSUM).
In order to represent individual sentences, we insert external [CLS] tokens at the start of each sentence, and each [CLS] symbol collects features for the sentence preceding it. We also use interval segment embeddings to distinguish multiple sentences within a document. For (sent_{i}) we assign segment embedding (E_{A}) or (E_{B}) depending on whether (i) is odd or even. For example, for document ([sent_{1}, sent_{2}, sent_{3}, sent_{4}, sent_{5}]), we would assign embeddings ([E_{A}, E_{B}, E_{A}, E_{B}, E_{A}]). This way, document representations are learned hierarchically where lower Transformer layers represent adjacent sentences, while higher layers, in combination with self-attention, represent multi-sentence discourse.
Position embeddings in the original BERT model have a maximum length of 512; we overcome this limitation by adding more position embeddings that are initialized randomly and finetuned with other parameters in the encoder.
3.2 Extractive Summarization
Let (d) denote a document containing sentences ([sent_{1}, sent_{2}, · · · , sent_{m}]), where (sent_{i}) is the (i)-th sentence in the document. Extractive summarization can be defined as the task of assigning a label (y_{i} ∈ {0, 1}) to each (sent_{i}), indicating whether the sentence should be included in the summary. It is assumed that summary sentences represent the most important content of the document.
With BERTSUM, vector (t_{i}) which is the vector of the (i)-th [CLS] symbol from the top layer can be used as the representation for (sent_{i}). Several inter-sentence Transformer layers are then stacked on top of BERT outputs, to capture document-level features for extracting summaries:
where (h^{0} = PosEmb(T)); (T) denotes the sentence vectors output by BERTSUM, and function PosEmb adds sinusoid positional embeddings (Vaswani et al., 2017) to T, indicating the position of each sentence. The final output layer is a sigmoid classifier:
where (h_{i}^{L}) is the vector for (sent_{i}) from the top layer (the (L)-th layer ) of the Transformer. In experiments, we implemented Transformers with (L = 1, 2, 3) and found that a Transformer with (L = 2) performed best. We name this model BERTSUMEXT.
The loss of the model is the binary classification entropy of prediction (hat{y}_{i}) against gold label (y_{i}). Inter-sentence Transformer layers are jointly finetuned with BERTSUM. We use the Adam optimizer with (β_{1} = 0.9), and (β_{2} = 0.999)). Our learning rate schedule follows (Vaswani et al., 2017) with warming-up ((warmup = 10, 000)):
3.3 Abstractive Summarization
We use a standard encoder-decoder framework for abstractive summarization (See et al., 2017). The encoder is the pretrained BERTSUM and the decoder is a 6-layered Transformer initialized randomly. It is conceivable that there is a mismatch between the encoder and the decoder, since the former is pretrained while the latter must be trained from scratch. This can make fine-tuning unstable; for example, the encoder might overfit the data while the decoder underfits, or vice versa. To circumvent this, we design a new fine-tuning schedule which separates the optimizers of the encoder and the decoder.
We use two Adam optimizers with (β_{1} = 0.9) and (β_{2} = 0.999) for the encoder and the decoder, respectively, each with different warmup-steps and learning rates:
where ( ilde{lr}varepsilon = 2e^{−3}), and (warmupvarepsilon = 20, 000) for the encoder and ( ilde{lr}_{D} = 0.1), and (warmup_{D} =10, 000) for the decoder. This is based on the assumption that the pretrained encoder should be fine-tuned with a smaller learning rate and smoother decay (so that the encoder can be trained with more accurate gradients when the decoder is becoming stable).
In addition, we propose a two-stage fine-tuning approach, where we first fine-tune the encoder on the extractive summarization task (Section 3.2) and then fine-tune it on the abstractive summarization task (Section 3.3). Previous work (Gehrmann et al., 2018; Li et al., 2018) suggests that using extractive objectives can boost the performance of abstractive summarization. Also notice that this two-stage approach is conceptually very simple, the model can take advantage of information shared between these two tasks, without fundamentally changing its architecture. We name the default abstractive model BERTSUMABS and the two-stage fine-tuned model BERTSUMEXTABS.
4 Experimental Setup
In this section, we describe the summarization datasets used in our experiments and discuss various implementation details.
4.1 Summarization Datasets
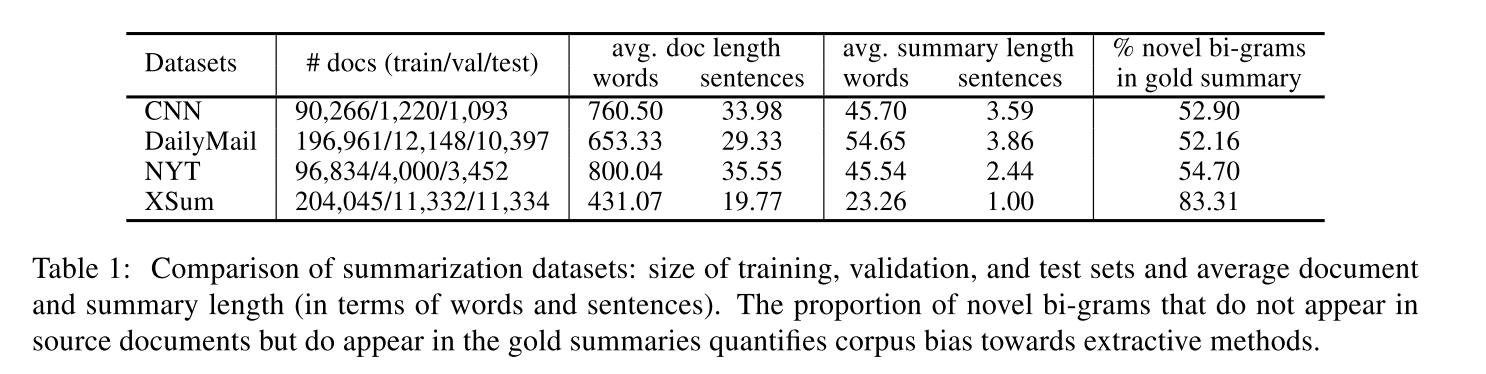
We evaluated our model on three benchmark datasets, namely the CNN/DailyMail news highlights dataset (Hermann et al., 2015), the New York Times Annotated Corpus (NYT; Sandhaus 2008), and XSum (Narayan et al., 2018a). These datasets represent different summary styles ranging from highlights to very brief one sentence summaries. The summaries also vary with respect to the type of rewriting operations they exemplify (e.g., some showcase more cut and paste operations while others are genuinely abstractive). Table 1 presents statistics on these datasets (test set); example (gold-standard) summaries are provided in the supplementary material.
CNN/DailyMail contains news articles and associated highlights, i.e., a few bullet points giving a brief overview of the article. We used the standard splits of Hermann et al. (2015) for training, validation, and testing (90,266/1,220/1,093 CNN documents and 196,961/12,148/10,397 DailyMail documents). We did not anonymize entities. We first split sentences with the Stanford CoreNLP toolkit (Manning et al., 2014) and pre-processed the dataset following See et al. (2017). Input documents were truncated to 512 tokens.
NYT contains 110,540 articles with abstractive summaries. Following Durrett et al. (2016), we split these into 100,834/9,706 training/test examples, based on the date of publication (the test set contains all articles published from January 1, 2007 onward). We used 4,000 examples from the training as validation set. We also followed their filtering procedure, documents with summaries less than 50 words were removed from the dataset. The filtered test set (NYT50) includes 3,452 examples. Sentences were split with the Stanford CoreNLP toolkit (Manning et al., 2014) and preprocessed following Durrett et al. (2016). Input documents were truncated to 800 tokens.
XSum contains 226,711 news articles accompanied with a one-sentence summary, answering the question “What is this article about?”. We used the splits of Narayan et al. (2018a) for training, validation, and testing (204,045/11,332/11,334) and followed the pre-processing introduced in their work. Input documents were truncated to 512 tokens.
Aside from various statistics on the three datasets, Table 1 also reports the proportion of novel bi-grams in gold summaries as a measure of their abstractiveness. We would expect models with extractive biases to perform better on datasets with (mostly) extractive summaries, and abstractive models to perform more rewrite operations on datasets with abstractive summaries. CNN/DailyMail and NYT are somewhat extractive, while XSum is highly abstractive.
4.2 Implementation Details
For both extractive and abstractive settings, we used PyTorch, OpenNMT (Klein et al., 2017) and the ‘bert-base-uncased’2 version of BERT to implement BERTSUM. Both source and target texts were tokenized with BERT’s subwords tokenizer.
Extractive Summarization All extractive models were trained for 50,000 steps on 3 GPUs (GTX 1080 Ti) with gradient accumulation every two steps. Model checkpoints were saved and evaluated on the validation set every 1,000 steps. We selected the top-3 checkpoints based on the evaluation loss on the validation set, and report the averaged results on the test set. We used a greedy algorithm similar to Nallapati et al. (2017) to obtain an oracle summary for each document to train extractive models. The algorithm generates an oracle consisting of multiple sentences which maximize the ROUGE-2 score against the gold summary.
When predicting summaries for a new document, we first use the model to obtain the score for each sentence. We then rank these sentences by their scores from highest to lowest, and select the top-3 sentences as the summary.
During sentence selection we use Trigram Blocking to reduce redundancy (Paulus et al., 2018). Given summary (S) and candidate sentence (c), we skip (c) if there exists a trigram overlapping between (c) and (S). The intuition is similar to Maximal Marginal Relevance (MMR; Carbonell and Goldstein 1998); we wish to minimize the similarity between the sentence being considered and sentences which have been already selected as part of the summary.
Abstractive Summarization In all abstractive models, we applied dropout (with probability 0.1) before all linear layers; label smoothing (Szegedy et al., 2016) with smoothing factor 0.1 was also used. Our Transformer decoder has 768 hidden units and the hidden size for all feed-forward layers is 2,048. All models were trained for 200,000 steps on 4 GPUs (GTX 1080 Ti) with gradient accumulation every five steps. Model checkpoints were saved and evaluated on the validation set every 2,500 steps. We selected the top-3 checkpoints based on their evaluation loss on the validation set, and report the averaged results on the test set.
During decoding we used beam search (size 5), and tuned the α for the length penalty (Wu et al., 2016) between 0.6 and 1 on the validation set; we decode until an end-of-sequence token is emitted and repeated trigrams are blocked (Paulus et al., 2018). It is worth noting that our decoder applies neither a copy nor a coverage mechanism (See et al., 2017), despite their popularity in abstractive summarization. This is mainly because we focus on building a minimum-requirements model and these mechanisms may introduce additional hyper-parameters to tune. Thanks to the subwords tokenizer, we also rarely observe issues with out-of-vocabulary words in the output; moreover, trigram-blocking produces diverse summaries managing to reduce repetitions.
5 Results
5.1 Automatic Evaluation
We evaluated summarization quality automatically using ROUGE (Lin, 2004). We report unigram and bigram overlap (ROUGE-1 and ROUGE-2) as a means of assessing informativeness and the longest common subsequence (ROUGE-L) as a means of assessing fluency.
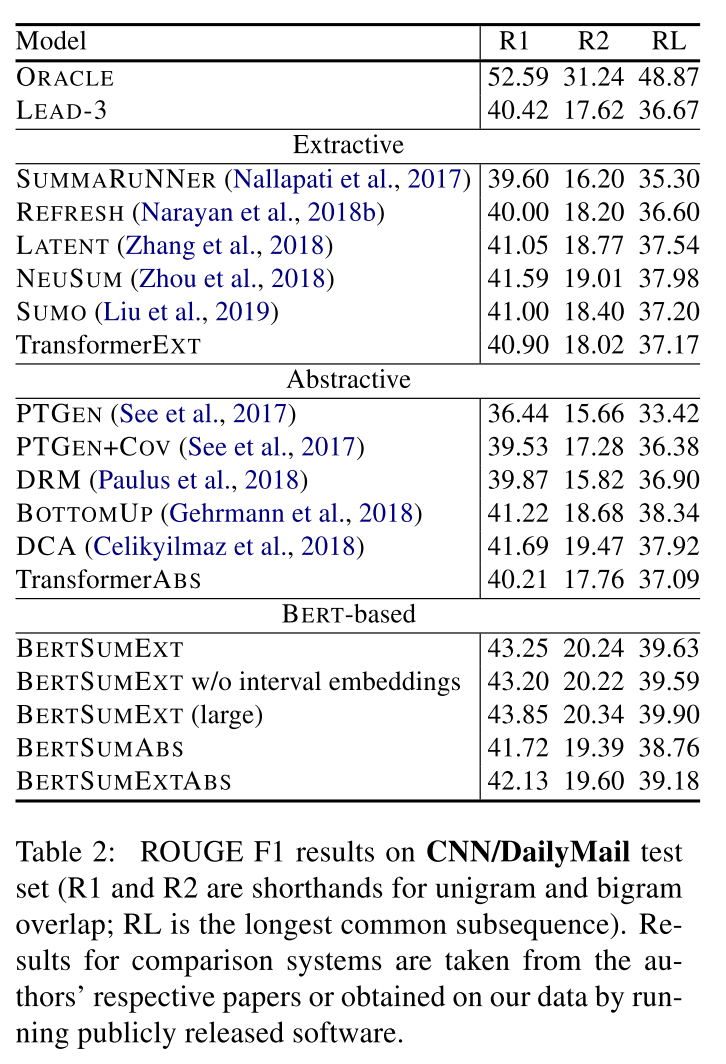
Table 2 summarizes our results on the CNN/DailyMail dataset. The first block in the table includes the results of an extractive ORACLE system as an upper bound. We also present the LEAD-3 baseline (which simply selects the first three sentences in a document).
The second block in the table includes various extractive models trained on the CNN/DailyMail dataset (see Section 2.2 for an overview). For comparison to our own model, we also implemented a non-pretrained Transformer baseline (TransformerEXT) which uses the same architecture as BERTSUMEXT, but with fewer parameters. It is randomly initialized and only trained on the summarization task. TransformerEXT has 6 layers, the hidden size is 512, and the feed-forward filter size is 2,048. The model was trained with same settings as in Vaswani et al. (2017).
The third block in Table 2 highlights the performance of several abstractive models on the CNN/DailyMail dataset (see Section 2.3 for an overview). We also include an abstractive Transformer baseline (TransformerABS) which has the same decoder as our abstractive BERTSUM models; the encoder is a 6-layer Transformer with 768 hidden size and 2,048 feed-forward filter size.
The fourth block reports results with fine-tuned BERT models: BERTSUMEXT and its two variants (one without interval embeddings, and one with the large version of BERT), BERTSUMABS, and BERTSUMEXTABS. BERT-based models outperform the LEAD-3 baseline which is not a strawman; on the CNN/DailyMail corpus it is indeed superior to several extractive (Nallapati et al., 2017; Narayan et al., 2018b; Zhou et al., 2018) and abstractive models (See et al., 2017). BERT models collectively outperform all previously proposed extractive and abstractive systems, only falling behind the ORACLE upper bound. Among BERT variants, BERTSUMEXT performs best which is not entirely surprising; CNN/DailyMail summaries are somewhat extractive and even abstractive models are prone to copying sentences from the source document when trained on this dataset (See et al., 2017). Perhaps unsurprisingly we observe that larger versions of BERT lead to performance improvements and that interval embeddings bring only slight gains.
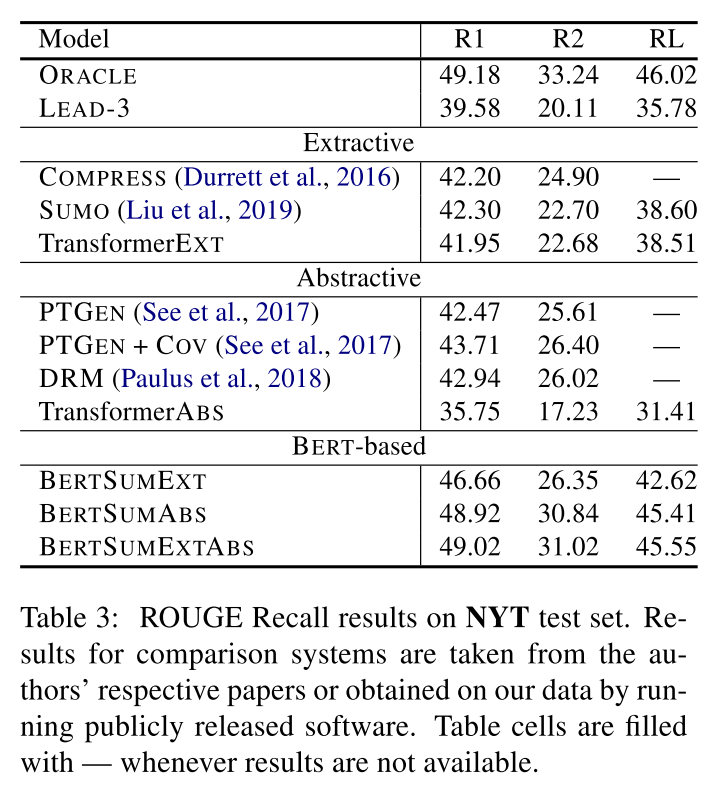
Table 3 presents results on the NYT dataset. Following the evaluation protocol in Durrett et al. (2016), we use limited-length ROUGE Recall, where predicted summaries are truncated to the length of the gold summaries. Again, we report the performance of the ORACLE upper bound and LEAD-3 baseline. The second block in the table contains previously proposed extractive models as well as our own Transformer baseline. COMPRESS (Durrett et al., 2016) is an ILP-based model which combines compression and anaphoricity constraints. The third block includes abstractive models from the literature, and our Transformer baseline. BERT-based models are shown in the fourth block. Again, we observe that they outperform previously proposed approaches. On this dataset, abstractive BERT models generally perform better compared to BERTSUMEXT, almost approaching ORACLE performance.

Table 4 summarizes our results on the XSum dataset. Recall that summaries in this dataset are highly abstractive (see Table 1) consisting of a single sentence conveying the gist of the document. Extractive models here perform poorly as corroborated by the low performance of the LEAD baseline (which simply selects the leading sentence from the document), and the ORACLE (which selects a single-best sentence in each document) in Table 4. As a result, we do not report results for extractive models on this dataset. The second block in Table 4 presents the results of various abstractive models taken from Narayan et al. (2018a) and also includes our own abstractive Transformer baseline. In the third block we show the results of our BERT summarizers which again are superior to all previously reported models (by a wide margin).
5.2 Model Analysis
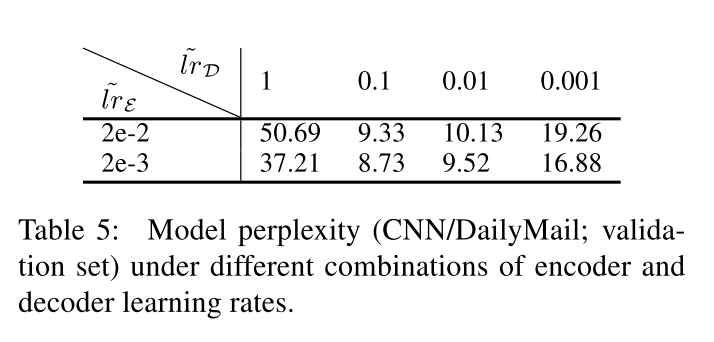
Learning Rates Recall that our abstractive model uses separate optimizers for the encoder and decoder. In Table 5 we examine whether the combination of different learning rates ( ( ilde{lr}varepsilon) and ( ilde{lr}_{D})) is indeed beneficial. Specifically, we report model perplexity on the CNN/DailyMail validation set for varying encoder/decoder learning rates. We can see that the model performs best with ( ilde{lr}varepsilon = 2e − 3) and ( ilde{lr}_{D} = 0.1).
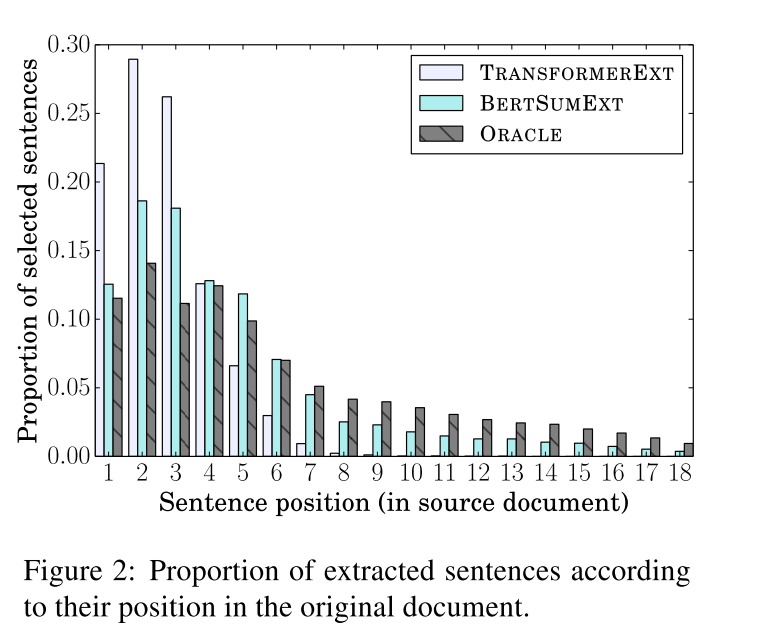
Position of Extracted Sentences In addition to the evaluation based on ROUGE, we also analyzed in more detail the summaries produced by our model. For the extractive setting, we looked at the position (in the source document) of the sentences which were selected to appear in the summary. Figure 2 shows the proportion of selected summary sentences which appear in the source document at positions 1, 2, and so on. The analysis was conducted on the CNN/DailyMail dataset for Oracle summaries, and those produced by BERTSUMEXT and the TransformerEXT. We can see that Oracle summary sentences are fairly smoothly distributed across documents, while summaries created by TransformerEXT mostly concentrate on the first document sentences. BERTSUMEXT outputs are more similar to Oracle summaries, indicating that with the pretrained encoder, the model relies less on shallow position features, and learns deeper document representations.
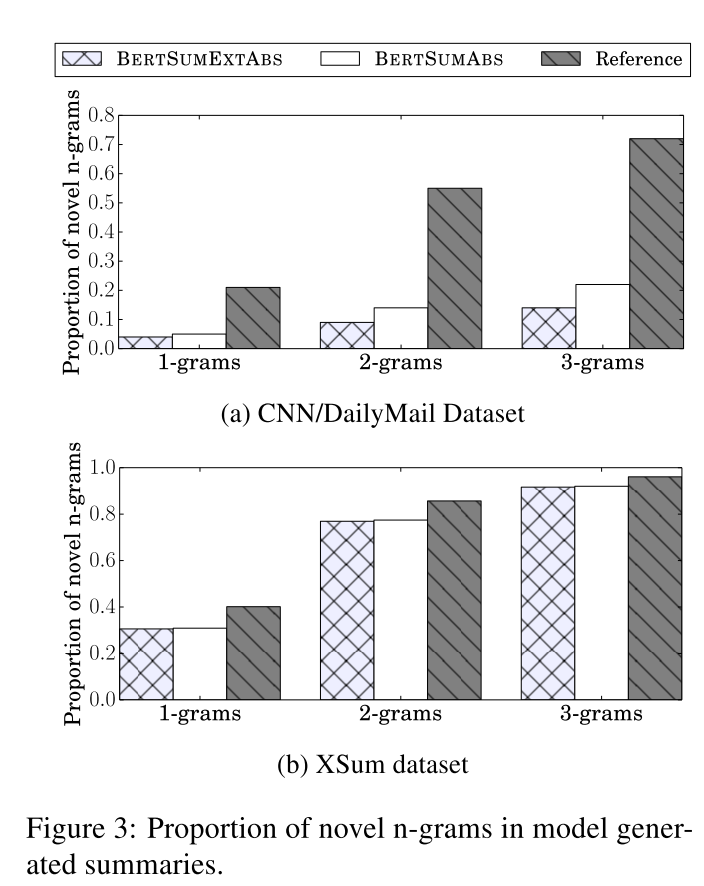
Novel N-grams We also analyzed the output of abstractive systems by calculating the proportion of novel n-grams that appear in the summaries but not in the source texts. The results are shown in Figure 3. In the CNN/DailyMail dataset, the proportion of novel n-grams in automatically generated summaries is much lower compared to reference summaries, but in XSum, this gap is much smaller. We also observe that on CNN/DailyMail, BERTEXTABS produces less novel n-ngrams than BERTABS, which is not surprising. BERTEXTABS is more biased towards selecting sentences from the source document since it is initially trained as an extractive model.
The supplementary material includes examples of system output and additional ablation studies.
5.3 Human Evaluation
In addition to automatic evaluation, we also evaluated system output by eliciting human judgments. We report experiments following a question answering (QA) paradigm (Clarke and Lapata,2010; Narayan et al., 2018b) which quantifies the degree to which summarization models retain key information from the document. Under this paradigm, a set of questions is created based on the gold summary under the assumption that it highlights the most important document content. Participants are then asked to answer these questions by reading system summaries alone without access to the article. The more questions a system can answer, the better it is at summarizing the document as a whole.
Moreover, we also assessed the overall quality of the summaries produced by abstractive systems which due to their ability to rewrite content may produce disfluent or ungrammatical output. Specifically, we followed the Best-Worst Scaling (Kiritchenko and Mohammad, 2017) method where participants were presented with the output of two systems (and the original document) and asked to decide which one was better according to the criteria of Informativeness, Fluency, and Succinctness.
Both types of evaluation were conducted on the Amazon Mechanical Turk platform. For the CNN/DailyMail and NYT datasets we used the same documents (20 in total) and questions from previous work (Narayan et al., 2018b; Liu et al., 2019). For XSum, we randomly selected 20 documents (and their questions) from the release of Narayan et al. (2018a). We elicited 3 responses per HIT. With regard to QA evaluation, we adopted the scoring mechanism from Clarke and Lapata (2010); correct answers were marked with a score of one, partially correct answers with 0.5, and zero otherwise. For quality-based evaluation, the rating of each system was computed as the percentage of times it was chosen as better minus the times it was selected as worse. Ratings thus range from -1 (worst) to 1 (best).
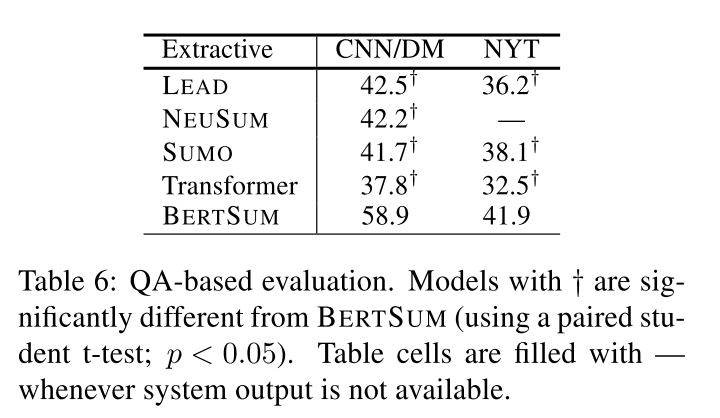
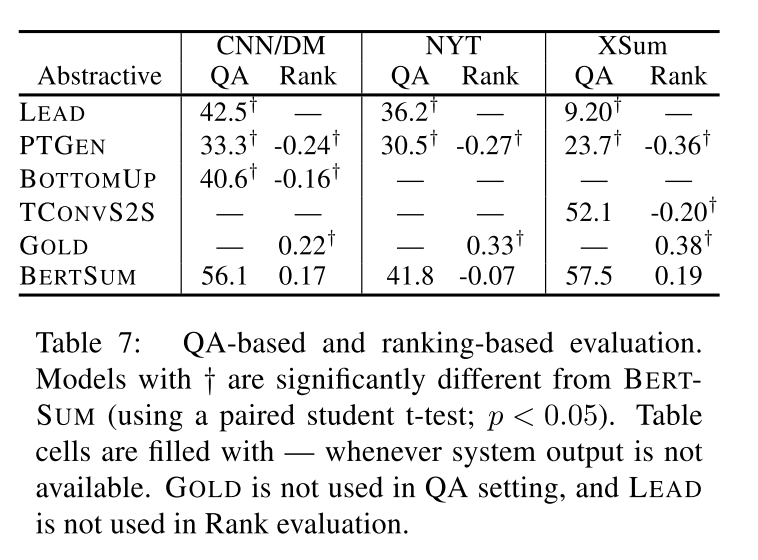
Results for extractive and abstractive systems are shown in Tables 6 and 7, respectively. We compared the best performing BERTSUM model in each setting (extractive or abstractive) against various state-of-the-art systems (whose output is publicly available), the LEAD baseline, and the GOLD standard as an upper bound. As shown in both tables participants overwhelmingly prefer the output of our model against comparison systems across datasets and evaluation paradigms. All differences between BERTSUM and comparison models are statistically significant ((p < 0.05)), with the exception of TCONVS2S (see Table 7; XSum) in the QA evaluation setting.
6 Conclusions
In this paper, we showcased how pretrained BERT can be usefully applied in text summarization. We introduced a novel document-level encoder and proposed a general framework for both abstractive and extractive summarization. Experimental results across three datasets show that our model achieves state-of-the-art results across the board under automatic and human-based evaluation protocols. Although we mainly focused on document encoding for summarization, in the future, we would like to take advantage the capabilities of BERT for language generation.
Acknowledgments
This research is supported by a Google PhD Fellowship to the first author. We gratefully acknowledge the support of the European Research Council (Lapata, award number 681760, “Translating Multiple Modalities into Text”). We would also like to thank Shashi Narayan for providing us with the XSum dataset.
相关资料:
- 《Text Summarization with Pretrained Encoders》阅读笔记 - 曾豪哈哈的文章 - 知乎 https://zhuanlan.zhihu.com/p/88953532
- [NLP&论文]Text Summarization with Pretrained Encoders论文翻译, https://www.cnblogs.com/mj-selina/p/13200657.html