我研究了3个例子:北京大学的wiki2bio、谷歌的ToTTo、微软的WIKITABLETEXT
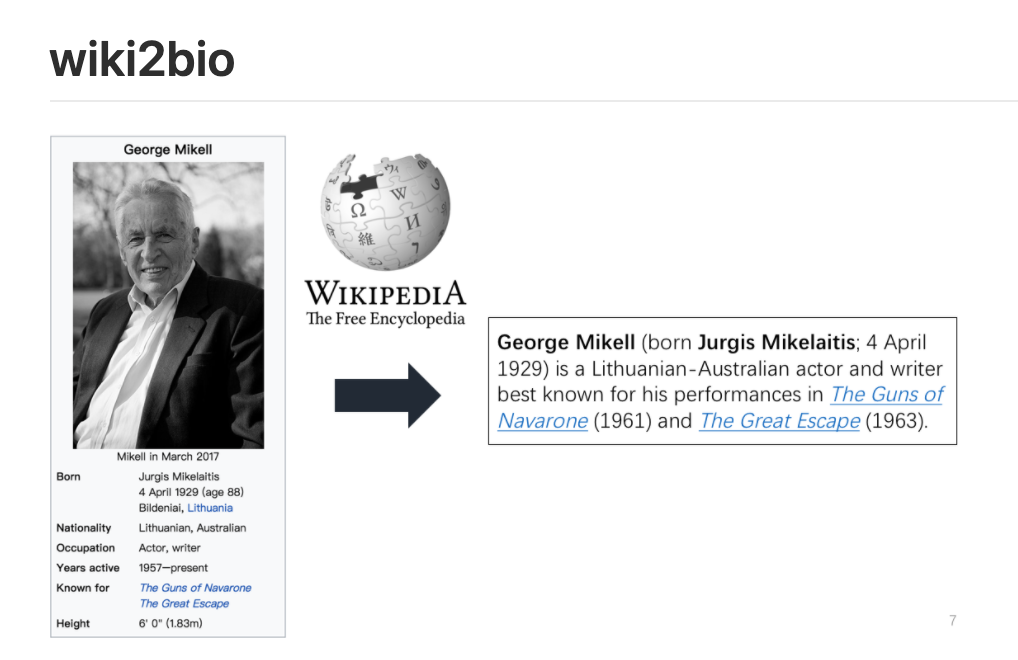
北京大学的wiki2bio
- Liu, T., Wang, K., Sha, L., Chang, B., & Sui, Z. (2018). Table-to-text generation by structure-aware seq2seq learning. 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, 4881–4888. https://arxiv.org/pdf/1711.09724.pdf
- https://github.com/tyliupku/wiki2bio
- 注意数据格式,不是二维表格
原始维基生物数据集(Lebret et al., 2016)包含约700k篇英文维基百科文章,其中580k为训练集,70k为验证集和测试集。Wiki信息框用作输入结构化数据,而文章的第一句作为目标文本。在原始数据集中,研究的领域是著名人物的传记。为了研究表到文本NLG任务中不同模型的通用性,我们首先将WIKIBIO数据集扩展到多个域。
创建WIKIBIO之后,我们收集了两个新领域的数据集:书籍和歌曲。我们根据每个域的Wikipedia类别遍历Wikipedia页面,然后抓取文章的第一句话,并对应于Wiki信息框。经过筛选和清理,我们得到了图书域的23,651个实例,歌曲域的39,450个实例。请注意,目标文本有时包含不在输入信息框中的信息。这是超出本文的few-shot 生成工作范围。因此,在接下来的实验中,我们进一步对数据集进行过滤,并将含有罕见词的数据集剔除出infobox。
与原始WIKIBIO数据集的人类域一起,我们通过将训练数据集大小改变为50、100、200和500个训练示例来进行实验。其余的数据用于测试。当训练损失没有减少时,我们停止训练。为了解决少样本训练的词汇量限制,我们对所有模型都采用(Sennrich et al., 2016)中引入的字节对编码(BPE),使用(Radford et al., 2019)中的子词单位词汇。
著名人物传记,域:Humans、Books、Songs
谷歌的ToTTo
Running with the following variables:
PREDICTION_PATH : language/totto/sample/output_sample.txt
TARGET_PATH : language/totto/sample/dev_sample.jsonl
OUTPUT_DIR : temp
MODE : test
Writing references.
Writing tables in PARENT format.
Preparing predictions.
Writing predictions.
Running detokenizers.
======== EVALUATE OVERALL ========
Computing BLEU (overall)
BLEU+case.mixed+numrefs.3+smooth.exp+tok.13a+version.1.2.6 = 45.55 86.0/63.5/44.7/31.0 (BP = 0.869 ratio = 0.877 hyp_len = 57 ref_len = 65)
Computing PARENT (overall)
Evaluated 5 examples.
Precision = 76.11 Recall = 43.83 F-score = 53.34
======== EVALUATE OVERLAP SUBSET ========
Computing BLEU (overlap subset)
BLEU+case.mixed+numrefs.3+smooth.exp+tok.13a+version.1.2.6 = 37.15 84.8/56.7/37.0/25.0 (BP = 0.809 ratio = 0.825 hyp_len = 33 ref_len = 40)
Computing PARENT (overlap subset)
Evaluated 3 examples.
Precision = 71.40 Recall = 31.35 F-score = 41.34
======== EVALUATE NON-OVERLAP SUBSET ========
Computing BLEU (non-overlap subset)
BLEU+case.mixed+numrefs.3+smooth.exp+tok.13a+version.1.2.6 = 58.26 87.5/72.7/55.0/38.9 (BP = 0.959 ratio = 0.960 hyp_len = 24 ref_len = 25)
Computing PARENT (non-overlap subset)
Evaluated 2 examples.
Precision = 83.17 Recall = 62.56 F-score = 71.35
- 代码:https://github.com/google-research/language.git,示例数据可以运行。
- 测试脚本依赖的
https://github.com/moses-smt/mosesdecoder.git不需要完全下载,准备好temp/mosesdecoder/scripts/tokenizer/detokenizer.perl即可 - 代码中sacrebleu的调用路径可直接使用
sacrebleu.tokenize_13a - 参考
https://github.com/xuehuiping/language/tree/master/language/totto
微软的WIKITABLETEXT
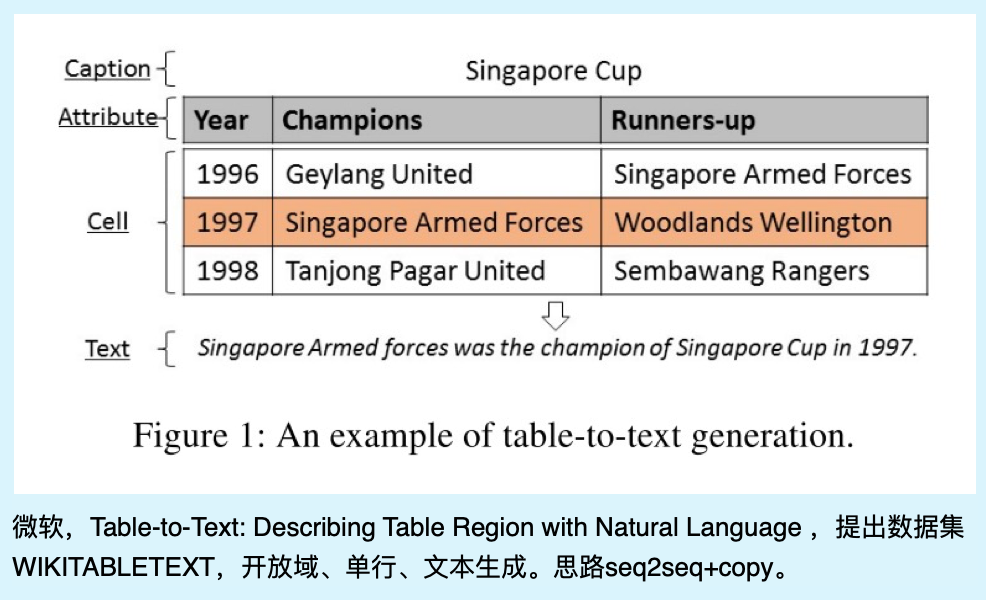
- Bao, J., Tang, D., Duan, N., Yan, Z., Lv, Y., Zhou, M., & Zhao, T. (2018). Table-to-text: Describing table region with natural language. 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, 5020–5027. https://arxiv.org/pdf/1805.11234.pdf
- https://github.com/tangduyu/Table-Intelligence 没下载下来