今天用了定闹钟的场景语料,在plato框架尝试了端到端的模型。
本文先记录英文的训练过程,然后记录中文的训练过程。
训练端到端的模型
发现使用英文的模型,还是显示有中文,所以,新建目录,重新训练
1. 用英文训练模型
工作目录:
xuehp@haomeiya002:~/git/plato-0224$
注意
metalwoz.json 和 metalwoz.hdf5 ,自动生成这2个文件
1.1. 准备文件
- 数据文件
metalwoz.csv
- 模型定义文件
metalWOZ_seq2seq_ludwig.yaml
定义了输入输出的特征
- 运行加载文件
metalwoz_text.yaml
运行Agent时使用,定义了模型的路径
1.2. 训练模型
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
训练完毕
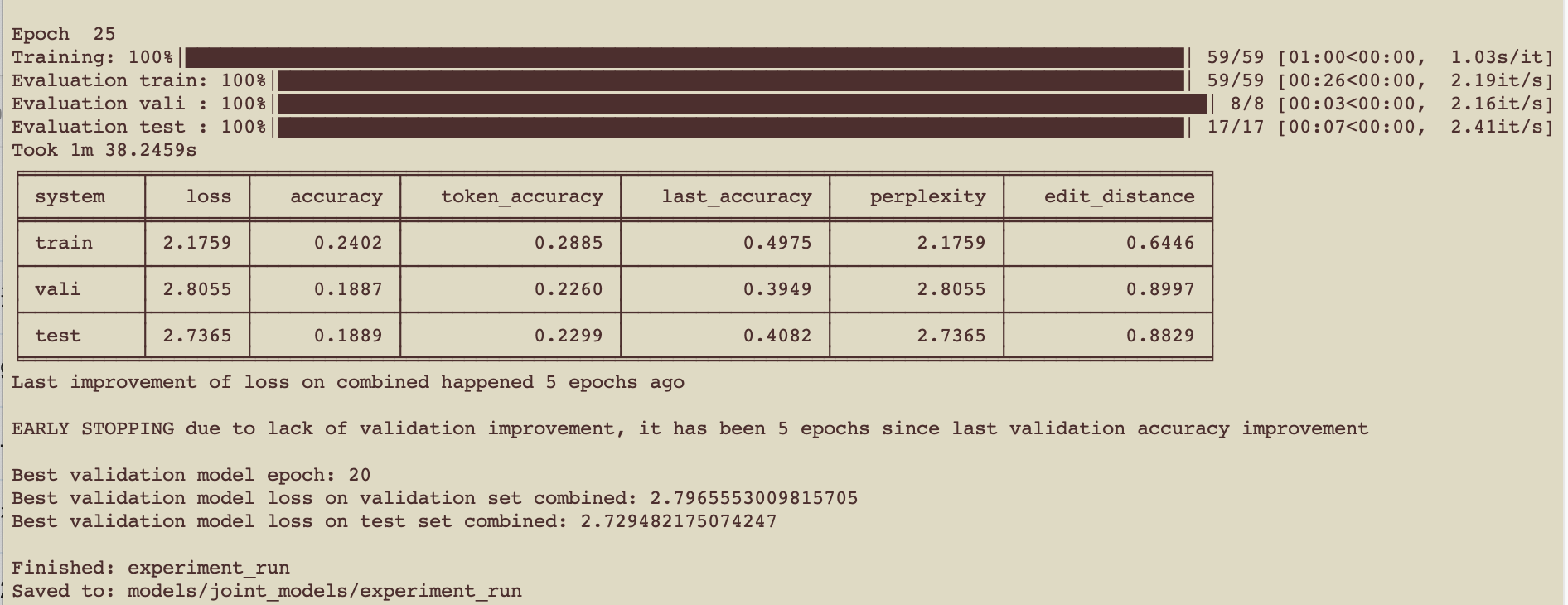
1.3. 使用模型
plato run --config metalwoz_text.yaml

看样子是可以运行起来的。
接下来使用中文语料进行训练
2. 用中文训练模型
工作目录:
xuehp@haomeiya002:~/git/plato-0223$
注意
metalwoz.json 和 metalwoz.hdf5 ,自动生成这2个文件
2.1. 准备文件
工作目录:
xuehp@haomeiya002:~/git/plato-0223$
- 数据文件
INSURANCE_zh_seg.txt
这是翻译成中文的语料文件
已分词的对话语料文件
- 模型定义文件
metalWOZ_seq2seq_ludwig.yaml
定义了输入输出的特征
- 运行加载文件
metalwoz_text.yaml
运行Agent时使用,定义了模型的路径
2.2. 处理文件
分词,将中文的语料文件进行分词
解析,将txt文件解析为csv文件
- 定义配置文件
Parse_MetalWOZ.yaml
- 执行转换
plato parse --config Parse_MetalWOZ.yaml
解析之后的文件在data/metalwoz.csv
2.3. 训练模型
ludwig train
--data_csv data/metalwoz.csv
--model_definition_file metalWOZ_seq2seq_ludwig.yaml
--output_directory "models/joint_models/"
训练完毕
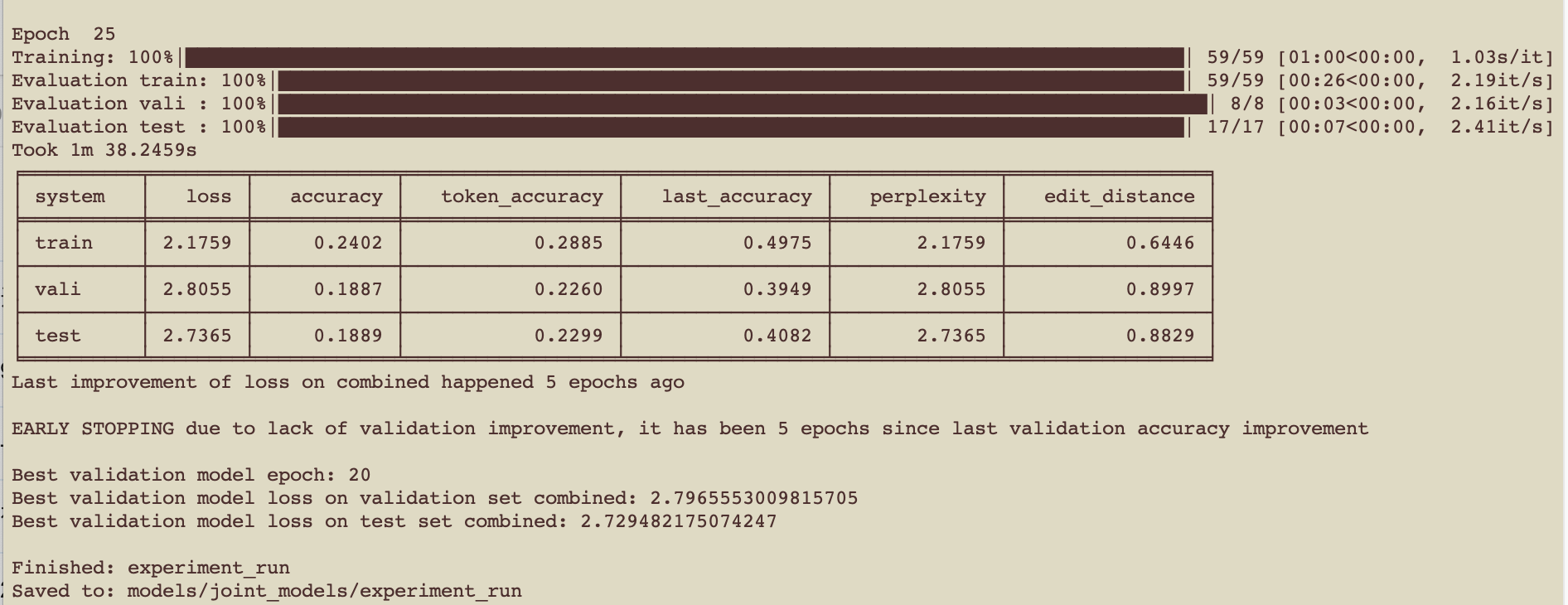
2.4. 使用模型
plato run --config metalwoz_text.yaml
