单变量分布
x1 = np.random.normal(size=1000)
sns.distplot(x1);
 

直方图
sns.distplot(x1, bins=20, kde=False, rug=True)
 

核密度估计
sns.distplot(x2, hist=False, rug=True)
 

sns.kdeplot(x2, shade=True)
sns.rugplot(x2)

双变量分布
df_obj1 = pd.DataFrame({"x": np.random.randn(500),
"y": np.random.randn(500)})
# 散布图
sns.jointplot(x="x", y="y", data=df_obj1)
# 二维直方图
sns.jointplot(x="x", y="y", data=df_obj1, kind="hex");
# 核密度估计
sns.jointplot(x="x", y="y", data=df_obj1, kind="kde");
 

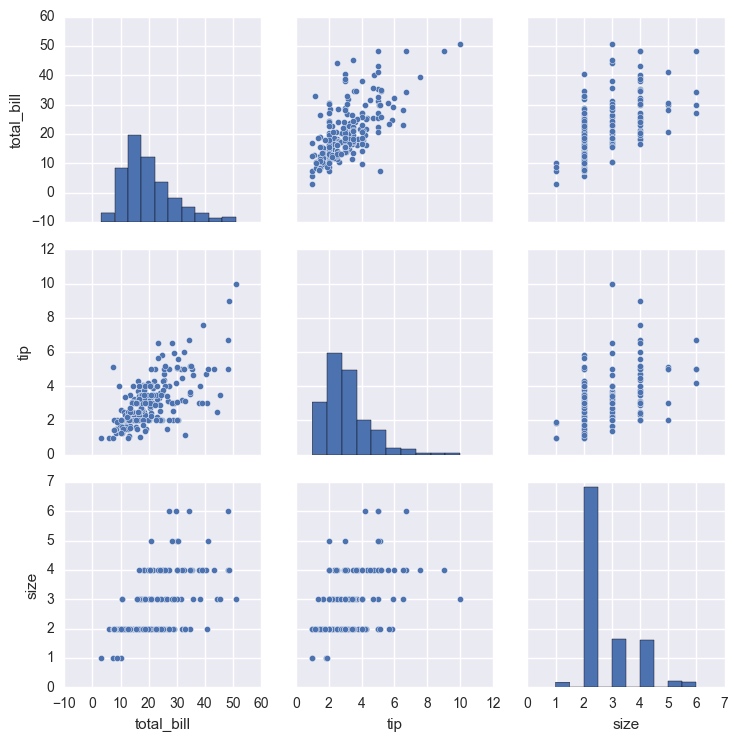
数据集中变量间关系可视化
# 数据集中变量间关系可视化
dataset = sns.load_dataset("tips")
#dataset = sns.load_dataset("iris")
sns.pairplot(dataset);

类别数据可视化
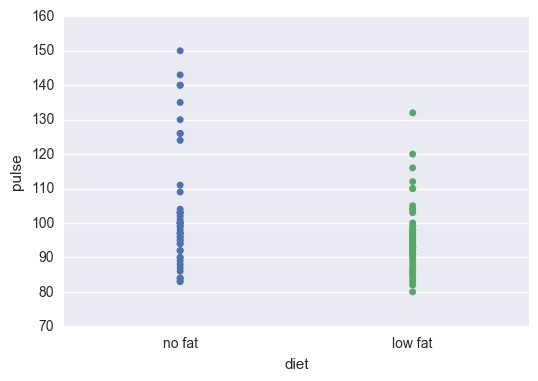
exercise = sns.load_dataset('exercise')
sns.stripplot(x="diet", y="pulse", data=exercise)

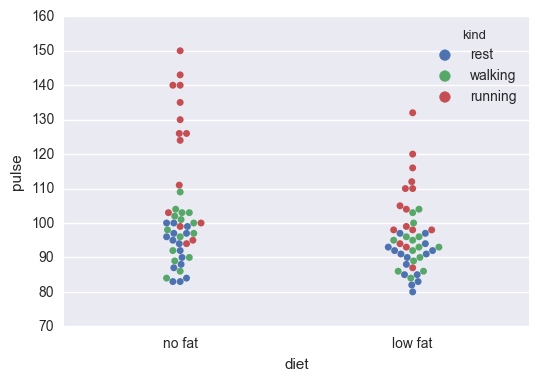
sns.swarmplot(x="diet", y="pulse", data=exercise, hue='kind')

盒子图
sns.boxplot(x="diet", y="pulse", data=exercise)

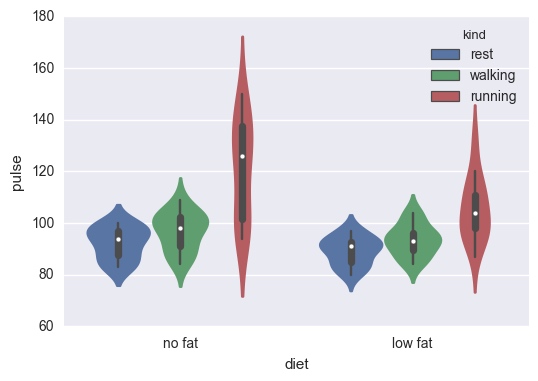
小提琴图
sns.violinplot(x="diet", y="pulse", data=exercise, hue='kind')

柱状图
sns.barplot(x="diet", y="pulse", data=exercise, hue='kind')
 

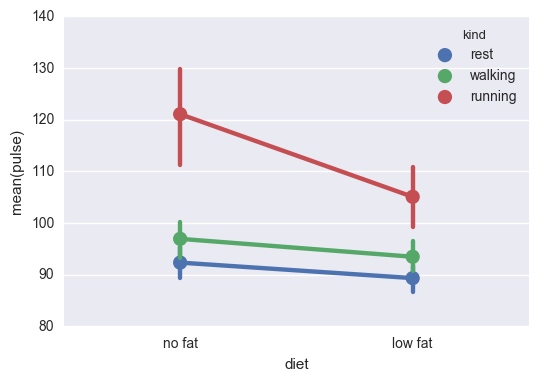
点图
sns.pointplot(x="diet", y="pulse", data=exercise, hue='kind');