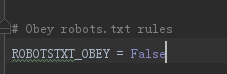
解决 scrapy 爬虫出现Forbidden by robots.txt 我们在爬取网站的时候,scrapy 默认的是遵循 robots.txt 协议,怎么破解这个文件 操作很简单,找到setting 文件 直接改成