2017-2018-1 学号 《信息安全系统设计基础》第13周学习总结
我认为最重要的一章是第三章。本章主要学习的就是汇编语言,信息安全的核心思维方式就是“逆向”,反汇编就是直接的逆向工程。所以我这篇博客写的是第三章的内容总结。
教材学习内容总结
程序的机器级表示
历史:
- Intel处理器系列:俗称x86,开始时是第一代单芯片、16位微处理器之一。
- DOS时代的平坦模式,不区分用户空间和内核空间,很不安全;
- 8086的分段模式;
- IA32的带保护模式的平坦模式
- 每个后继处理器的设计都是后向兼容的,可以保证较早版本上编译的代码在较新的处理器上运行。
程序编码:
- GCC将源代码转化为可执行代码的步骤:
- C预处理器——扩展源代码-生成.i文件
- 编译器——产生两个源代码的汇编代码-——生成.s文件
- 汇编器——将汇编代码转化成二进制目标代码——生成.o文件
- 链接器——产生可执行代码文件
gcc -o mstore mstore.c
gcc -Og -S mstore.c
gcc -Og -c mstore.c
两种抽象:
- 指令集结构ISA:是机器级程序的格式和行为,定义了处理器状态、指令的格式,以及每条指令对状态的影响。
- 机器级程序使用的存储器地址是虚拟地址,看上去是一个非常大的字节数组,实际上是将多个硬件存储器和操作系统软件组合起来。
机器级代码
控制
1、条件码
CF:进位标志
ZF:零标志
SF:符号标志
OF:溢出标志
2、访问条件码
SET指令根据t=a-b的结果设置条件码;
可以条件跳转到程序的某个其他部分;
可以有条件的传送数据。
3、跳转指令及其编码
jump指令
直接跳转:后面跟标号作为跳转目标
间接跳转:*后面跟一个操作数指示符
其他跳转指令
除了jump指令外,其他跳转指令都是有条件的。有条件跳转是指根据条件码的某个组合,或者跳转或者继续执行下一条指令。
4、循环
循环结构的三种形式
do-while:先执行循环体语句,再执行判断,循环体至少执行一次。
while: 把循环改成do-while的样子,然后用goto翻译
for: 把循环改成do-while的样子,然后用goto翻译
汇编中用条件测试和跳转组合实现循环的效果。大多数汇编器根据do-while形式来产生循环代码,其他的循环会首先转换成do-while形式,然后再编译成机器代码。
5、switch语句
跳转表是一种非常有效的实现多重分支的方法,是一个数组,表项i是一个代码段的地址,这个代码段实现当开关索引值等于i时程序应该采取的动作。
教材学习
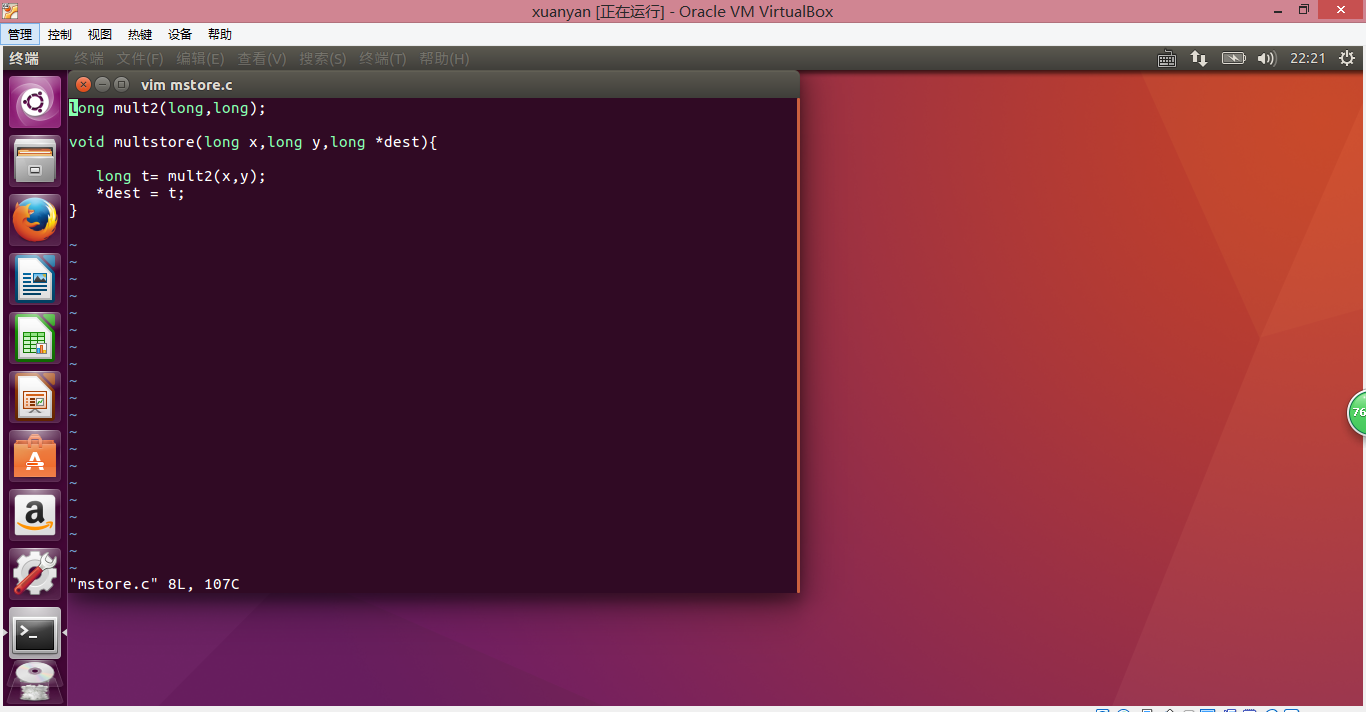
- 课本上P114页的代码如图所示:
long mult2(long,long);
void multstore(long x,long y,long *dest){
long t= mult2(x,y);
*dest = t;
}
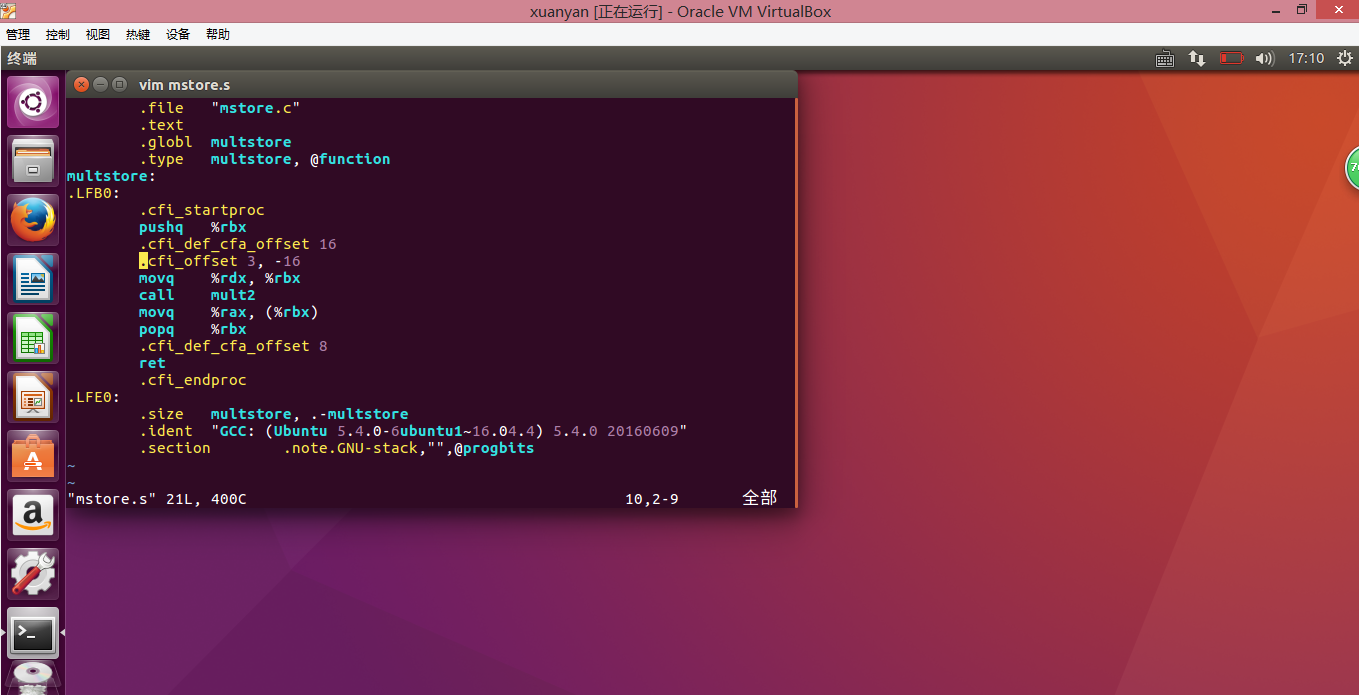
- 课本上P116页的代码如下所示
#include<stdio.h>
void multstore(long,long,long*);
int main(){
long d;
multstore(2,3,&d);
printf("2*3 --> %ld
",d);
return 0;
}
long mult2(long a,long b){
long s=a*b;
return s;
}
- 输入指令
gcc -Og -o prog ms1.c mstore.c
objdump -d prog

- 生成的汇编代码如下:
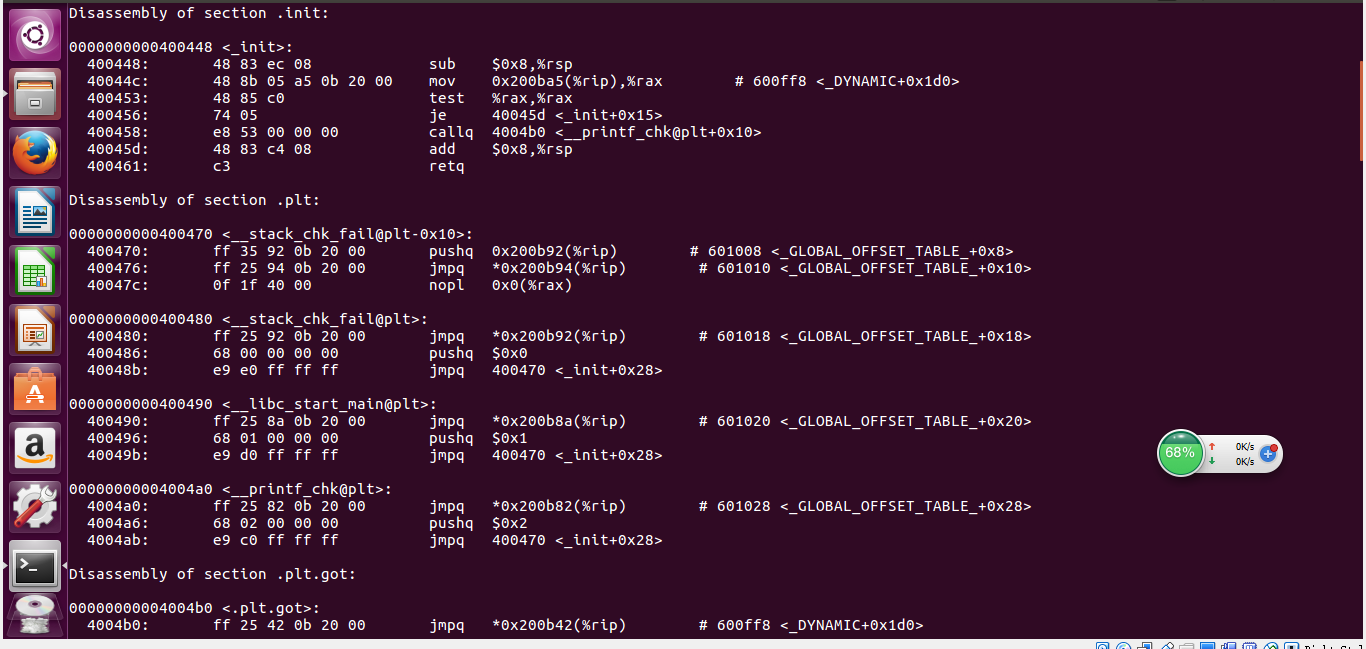
- 与P114的代码的反汇编结果对比可看出来,代码是差不多的,


家庭作业
3.58
store_prod:
movq %rdx, %rax (y-->%rax)(设为b0)
cqto (将%rax符号拓展位八字,拓展的y的高位数据保存在%rdx里,此值为y的高位:b1)
movq %rsi, %rcx (x-->%rcx )(设为a0)
sarq $63, %rcx (拓展x的符号位为64位,并保存到%rcx,此值为x的高位:a1)
imulq %rax, %rcx (k1 = b0*a1)
imulq %rsi, %rdx (k2 = a0*b1)
addq %rdx, %rcx (k1+k2)
mulq %rsi (128位无符号全乘法,计算 %rsi * %rax ,结果的高64位存储在:%rdx,低64位存储在:%rax)
addq %rcx, %rdx (k1+k2+%rdx)
movq %rax, (%rdi) (存储最终的低64位结果到内存)
movq %rdx, 8(%rdi) (存储最终的高64位结果到内存)
ret
-
等价的C代码为(((y-z)<<63)>>63)^((y-z)*x)
-
3.59
-
%rdx与%rax共同代表一个128位数的意思,是指用可以用计算公式%rdx*2^64+%rax来表示这个数,而并不是把这%rdx和%rax的二进制串串连起来表示这个数,区别在于,当这个数为负数的时候,%rdx是-1.意思是所有位都为1,而如果串连起来的话,显然只有%rdx的第一位为1,后面全为0.因此这里的数学公式推理才正确,所以对于汇编的第10行为什么要加上%rcx,就不要用串连起来的表示方法去想象这一行的正确性,而应该用数学公式去推.
下面用x0,y0来分别表示x和y的低位,用x1,y1来分别表示x和y的高位,用W表示2^64,因此下面的公式成立:
p = x * y
= (x1*W + x0) * (y1*W + y0)
= (x1*y1*W*W) + W(x1*y0+x0*y1) + x0*y0
公式中x1y1WW超过了128位,而且未超出128位部分始终全为0,因此可以去掉.于是公式变成了p=W(x1y0+x0y1) + x0y0,然后可以继续转化,注意这里的x0y0是很可能会超出64位的,假设x0y0的超出64位的部分为z1,未超出64位的部分为z0.那么公式可以变成如下:
p = W(x1y0+x0y1+z1) + z0
1
很明显,需要将x1y0+x0y1+z1放到最终结果的高位,即(%rdi),z0放到最终结果的低位,即8(%rdi)
然后仔细翻译下各个语句
store_prod:
movq %rdx, %rax # %rax = y0.
cqto # 有符号运算,因此用cqto,这里会自动关联%rdx和%rax分别表示高位和低位,假如y是负数,那么%rdx所有位都是1(此时值是-1),否则,%rdx全为0, %rdx = y1.
movq %rsi, %rcx # %rcx = x0.
sarq $63, %rcx # 将%rcx向右移63位,跟%rdx的含义一样,要么是-1,要么是0, %rcx = x1.
imulq %rax, %rcx # %rcx = y0 * x1
imulq %rsi, %rdx # %rdx = x0 * y1
addq %rdx, %rcx # %rcx = y0 * x1 + x0 * y1
mulq %rsi # 无符号计算 x0*y0,并将x0*y0的128位结果的高位放在%rdx,低位放在%rax,因此这里%rdx = z1, %rax = z0.
addq %rcx, %rdx # %rdx = y0*x1+x0*y1+z1
movq %rax, (%rdi) # 将%rax的值放到结果的低位
movq %rdx, 8(%rdi)# 将%rdx的值放到结果的高位,可以发现跟上面用数学公式推理的结果完全一致!!!!
ret
**3.60
loop:
movl %esi, %ecx # %ecx=n;
movl $1, %edx # %edx=1; --> mask
movl $0, %eax # %eax=0; --> result
jmp .L2
.L3:
movq %rdi, %r8 # %r8=x;
andq %rdx, %r8 # %r8=x&%rdx; -->x&mask
orq %r8, %rax # %rax=%rax | (x&%rdx); -->result |= x & mask
salq %cl, %rdx # %rdx=%rdx<<(n&0xFF); -->mask<<=(n&0xFF)
.L2:
testq %rdx, %rdx
jne .L3. # if %rdx!=0 goto L3. -->mask!=0
rep; ret
A.
%rdi, %r8 --> x
%esi, %ecx --> n
%rdx --> mask
%rax --> result
B.
result = 0;
mask = 1;
C.
mask != 0
D.
mask<<=(n&0xFF)
E.
result |= x & mask
F.
long loop(long x, int n)
{
long result = 0;
long mask;
for(mask = 1;mask != 0;mask = mask << (n&0xFF)){
result |= x & mask;
}
return result;
}
3.61
传送指令会对条件分别求值,于是假如xp为空指针,那么这里产生对空指针读数据的操作,显然是不可以的。于是这里不能存在*xp,可以用指针来代替,最后判断出值之后,再进行读取数据,因此这里0也必须赋予一个地址,于是需要加个变量来存储0这个数字。因此答案可以是:
long cread_alt(long *xp)
{
int t=0;
int *p = xp ? xp : &t;
return *p;
}
**3.62
这个题就是纯翻译汇编,没有什么可讲的。
case MODE_A:
result = *p2;
action = *p1;
*p2 = action;
break;
case MODE_B:
result = *p1 + *p2;
*p1 = result;
break;
case MODE_C:
*p1 = 59;
result = *p2;
break;
case MODE_D:
result = *p2;
*p1 = result;
result = 27;
break;
case MODE_E:
result = 27;
break;
default:
result = 12;
**3.63
<switch_prob>:
400590: 48 83 ee 3c sub $0x3c, %rsi
# 说明下面的数都要加上60
400594: 48 83 fe 05 cmp $0x5, %rsi
400598: 77 29 ja 4005c3 <switch_prob+0x33>
# 如果大于65,跳到4005c3那一行
40059a: ff 24 f5 f8 06 40 00 jmpq *0x4006f8(,%rsi,8)
# 跳到跳转表对应的位置,假设跳转表对应数组a[x],那么分别跳到a[0x4006f8+8*(n-60)]的位置
4005a1: 48 8d 04 fd 00 00 00 lea 0x0(,%rdi,8),%rax
# 60和62会跳到这个位置
4005a8: 00
400593: c3 retq
4005aa: 48 89 f8 mov %rdi, %rax
# 63会跳到这个位置
4005ad: 48 c1 f8 03 sar $0x3, %rax
4005b1: c3 retq
4005b2: 48 89 f8 mov %rdi, %rax
# 64会跳到这个位置
4005b5: 48 c1 e0 04 shl $0x4, %rax
4005b9: 48 29 f8 sub %rdi, %rax
4005bc: 48 89 c7 mov %rax, %rdi
4005bf: 48 0f af ff imul %rdi, %rdi
# 65会跳到这个位置
4005c3: 48 8d 47 4b lea 0x4b(%rdi), %rax
# 大于65和61会跳到这个位置
4005c7: c3 retq
根据上面的分析过程可得答案如下:
long switch_prob(long x, long n){
long result = x;
switch(n):{
case 60:
case 62:
result = x * 8;
break;
case 63:
result = result >> 3;
break;
case 64:
result = (result << 4) - x;
x = result;
case 65:
x = x * x;
case 61: # 也可以去掉这行
default:
result = x + 0x4b;
}
}
***3.64
store_ele:
leaq (%rsi, %rsi, 2), %rax # %rax = 3 * j
leaq (%rsi, %rax, 4), %rax # %rax = 13 * j
leaq %rdi, %rsi # %rsi = i
salq $6, %rsi # %rsi * = 64
addq %rsi, %rdi # %rdi = 65 * i
addq %rax, %rdi # %rdi = 65 * i + 13 * j
addq %rdi, %rdx # %rdx = 65 * i + 13 * j + k
movq A(, %rdx, 8), %rax # %rax = A + 8 * (65 * i + 13 * j + k)
movq %rax, (%rcx) # *dest = A[65 * i + 13 * j + k]
movl $3640, %eax # sizeof(A) = 3640
ret
A.
&D[i][j][k] = XD + L(i * S * T + j * T + k)
B.
由A题目中的公式以及汇编至第9行第10行计算出来的可得:
S * T = 65
T = 13
S * T * R * 8 = 3640
很容易可以计算出来
R = 7
S = 5
T = 13
*3.65
.L6:
movq (%rdx), %rcx # t1 = A[i][j]
movq (%rax), %rsi # t2 = A[j][i]
movq %rsi, (%rdx) # A[i][j] = t2
movq %rcx, (%rax) # A[j][i] = t1
addq $8, %rdx # &A[i][j] += 8
addq $120, %rax # &A[j][i] += 120
cmpq %rdi, %rax
jne .L6 # if A[j][i] != A[M][M]
A.
从2~5行里无法区分A[i][j]和A[j][i],只能从第6和7行来看,A[i][j]每次只移动一个单位,所以每次+8的寄存器%rdx就是指的A[i][j]。
B.
因为寄存器%rdx是A[i][j],所以另一个寄存器%rax是A[j][i]。
C.
A[j][i]每次移动一行的距离,所以可得公式:8 * M = 120,显然,M=15。
*3.66
sum_col:
leaq 1(, %rdi, 4), %r8 # %r8 = 4 * n + 1
leaq (%rdi, %rdi, 2), %rax # result = 3 * n
movq %rax, %rdi # %rdi = 3 * n
testq %rax, %rax
jle .L4 # if %rax <= 0, goto L4
salq $3, %r8 # %r8 = 8 * (4 * n + 1)
leaq (%rsi, %rdx, 8), %rcx # %rcx = A[0][j]
movl $0, %eax # result = 0
movl $0, %edx # i = 0
.L3:
addq (%rcx), %rax # result = result + A[i][j]
addq $1, %rdx # i += 1
addq %r8, %rcx # 这里每次+8*(4n+1),说明每一行有4n+1个,因此NC(n)为4*n+1
cmpq %rdi, %rdx
jne .L3 # 这里说明一直循环到3*n才结束,所以可以说明一共有3n行,因此NR(n)为3*n
rep; ret
.L4:
movl $0, %eax
ret
根据上述代码中的分析,可以得出
NR(n) = 3 * n
NC(n) = 4 * n + 1
-
3.67
相对于%rsp的偏移量 | 存储的值
---|---
%rsp+24| z
%rsp+16| &z
%rsp+| y
%rsp | x -
3.68
首先,结构体str2类型的最长单位是long,所以按照8位对齐,str1同样,也是按照8位对齐.
再来看汇编代码:
setVal:
movslq 8(%rsi), %rax
# 说明str2的t从第8位开始的,因为按照8位对齐,因此sizeof(array[B])小于等于8
# 因为下边的t是int类型,只占4个字节,为了不让t与array共占8个字节,所以sizeof(array[B])大于4,因此可得5<=B<=8.
addq 32(%rsi), %rax
# 说明str2的u从第32位开始的,因此t与s占了24个字节,可以将2个s放在t的一行,占满8个字节,剩下的s占据两行,因此可得7<=A<=10.
movq %rax, 184(%rdi)
# 说明str1的y从第184位开始的,因此184-8<A*B*4<=184
根据汇编代码推出的三个公式:
5<=B<=8
7<=A<=10
184-8<A*B*4<=184
可以算出唯一解为:
A=9
B=5
- 3.69
<test>:
mov 0x120(%rsi), %ecx
# 这句话是访问bp的first,说明first与a一共占了288个字节
add (%rsi), %rcx
# %rcx = n
lea (%rdi, %rdi, 4), %rax
# %rax = 5 * i
lea (%rsi, %rax, 8), %rax
# %rax = &bp + 40 * i
mov 0x8(%rax), %rdx
# ap->idx = %rax + 8
# 这两句表明了&bp->a[i]的地址计算公式,即&bp+8+40i,因此可以说明,a的总大小是40
# +8说明first自己占8个字节,按照的8位对齐,因此a的第一个元素肯定是8个字节的.
movslq %ecx, %rcx
# 在这里将n进行了类型转换,int型转换成了long型,因此说明ap里的x数组一定是long型
mov %rcx, 0x10(%rax, %rdx, 8)
# 这句说明了ap->x[ap->idx]的地址计算公式是&bp + 16 + idx * 8
# +16说明了包含了first以及idx,说明idx是a的第一个元素,根据上面得出的第一个元素肯定是8个字节的结论,说明idx是long类型.
# 再因为一共占大小40,所以x数组的元素个数为(40 - 8) / 8 = 4
retq
- 3.70
注意是union类型
A.
e1.p 0
e1.y 8
e2.x 0
e2.next 8
B.
16
C.
这一问比较有难度,逻辑性也很强,还是建议尽量能够自己推出来.下面来仔细推一下,这题就不好从头开始一句句的推了, 需要跳跃性的推理(什么鬼).
1 proc:
2 movq 8(%rdi), %rax
3 movq (%rax), %rdx
4 movq (%rdx), %rdx
5 subq 8(%rax), %rdx
6 movq %rdx, (%rdi)
7 ret
先来看proc的C代码,等式右边中间有个减号,因此,可以去汇编里找到第5行的subq,所以2~4行就是赋值的被减数.
第3行和第4行代码分别加了两次星号,因此可以说明是((A).B)结构,根据第二行,因为是偏移量+8,取得是第二个值,e1.y不是指针,因此只能是e2.next,于是A为e2.next;同理,B说明也是指针,没有偏移量,是取得第一个值,因此只能是e1.p.所以被减数就推出来了为((up->e2.next).e1.p)
再看第5行,减数的偏移量是相对于%rax+8,上一条步骤中,%rax是(up->e2.next),取第二个值,而且汇编代码中并未加星号,因此说明不是指针,那么只能e1.y,因此减数是(up->e2.next).e1.y
最后只剩等式左边,来看第6行,偏移量为0说明取得第一个值,且从C代码中看未加星号,因此不是指针,所以只能是e2.x.
根据上述推理,可以得出C代码为:
void proc(union ele *up){
up->e2.x = *(*(up->e2.next).e1.p) - *(up->e2.next).e1.y;
}
本周结对学习情况
- [20155232](http://www.cnblogs.com/lsqsjsj/p/8052671.html)
- 结对学习内容
- 最重要的一章的学习
- 分享学习体会
其他(感悟、思考等,可选)
xxx
xxx