序列化模块
在讲序列化模块之前,先来看序列化的概念:
我们在进行文件存储时 用的都是str字符串,但是在网络上传输时都是采用bytes类型;
序列化: 数据类型---》字符串类型
反序列化: 字符串类型----》数据类型
1. json
优点:通用的序列化格式;
缺点:只有少部分数据类型可以转化为字符串类型;
有时候别人可能需要使用我们写的代码中的数据,我们也有可能使用别人代码中的数据,或者我写了一段python代码,有数据要传给另一个用c++写的人,这其中数据传输都需要使用json模块
a. json.dumps() ---->把数据类型转为字符串; json.loads() ---->将字符串格式的再转回来;
import json dic={'k1':'v1','k2':'v2','k3':'v3'} print(dic,type(dic)) # 首先看一下没被json.dumps转化的字典 str_dic=json.dumps(dic) print(str_dic,type(str_dic)) # json.dumps()转化之后的字典已经变为字符串类型啦 dic_1=json.loads(str_dic) # 把json.dumps() 转化为字符串 再使用json.loads()转回来 print(dic_1,type(dic_1))
运行结果:
b. json.dump() ---->在文件中操作数据类型,先转为字符串 再写入文件; json.load()----->在文件中操作,将序列化为字符串类型的再转回来;
import json f=open('info','w',encoding='utf-8') dic={'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f) # 使用json.dump()将字典dic先转化为字符串类型,再写入字典; f.close()
运行结果:
然后我们再使用json.load(f) 从文件中读取内容,是转化回来之后的在读取出来;
import json # f=open('info','w',encoding='utf-8') # dic={'k1':'v1','k2':'v2','k3':'v3'} # json.dump(dic,f) # 使用json.dump()将字典dic先转化为字符串类型,再写入字典; # f.close() f=open('info','r',encoding='utf-8') ret=json.load(f) # 使用json.load()将写入文件的字符串类型读取出来,转为原来的类型了~ print(ret,type(ret))
运行结果:

关于使用json.dump()将数据类型转为字符串,然后写进文件,然后使用json.load()读取字符串类型内容,然后转回原来的类型,当我们写进文件的内容包含中文时 其实会出现不显示中文(而是其他进制):
import json f=open('info','w',encoding='utf-8') dict={'k1':'璇璇','k2':22} json.dump(dict,f) f.close() f=open('info','r',encoding='utf-8') ret=json.load(f) print(ret)
运行结果:
但是写进文件中的内容却是这样的: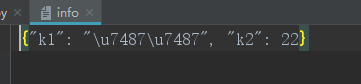
我们只需要在json.dump(dic,f,ensure_ascii=False)即可解决~
import json f=open('info','w',encoding='utf-8') dict={'k1':'璇璇','k2':22} json.dump(dict,f,ensure_ascii=False) f.close() f=open('info','r',encoding='utf-8') ret=json.load(f) print(ret)
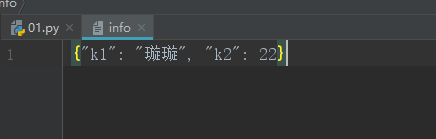
总结:
json.dumps() 和 json.loads()都是在内存中操作能使用json序列化为字符串类型的数据类型,转为字符串类型,然后再转回来;
json.dump() 和 json.load() 都是在文件中操作,先将数据类型转为字符串,再写进文件,然后读取文件中内容,再转回来;
c. 如果想要一行一行往文件中写内容,再一行一行读,应该怎么办:
import json f=open('info','w',encoding='utf-8') dic={'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f,ensure_ascii=False) json.dump(dic,f,ensure_ascii=False) # 往文件中写入两次数据,所以文件中有两个一样的字典 f.close()

可是当我们使用json.load()读取时会出错:
f=open('info','r',encoding='utf-8') print(json.load(f))
所以我们正确的操作应该是这样的:(使用json.dumps() 和 json.loads())
import json f=open('info','w',encoding='utf-8') L=[{'k1':'v1','k2':'v2','k3':'v3'},{'k11':'v11','k21':'v21','k31':'v31'},{'k41':'v41','k42':'v42','k43':'v43'}] for dic in L: str_dic=json.dumps(dic) # 对于每一个字典使用json.dumps()转为字符串 f.write(str_dic+' ') # 然后使用f.write()将转化为字符串的内容发写进文件,但是末尾加上 就是每一个字典写一行 f.close()

上面是一行一行写,接下来该一行一行读取:
import json # f=open('info','w',encoding='utf-8') # L=[{'k1':'v1','k2':'v2','k3':'v3'},{'k11':'v11','k21':'v21','k31':'v31'},{'k41':'v41','k42':'v42','k43':'v43'}] # for dic in L: # str_dic=json.dumps(dic) # 对于每一个字典使用json.dumps()转为字符串 # f.write(str_dic+' ') # 然后使用f.write()将转化为字符串的内容发写进文件,但是末尾加上 就是每一个字典写一行 # f.close() f=open('info','r',encoding='utf-8') L=[] # 用来存放从文件读取的内容 for line in f: ret=json.loads(line.strip()) # 这里的line 是刚才使用json.dumps()转化为字符串 再使用f.write()写进去的,现在 使用json.loads()再把字符串转回来 L.append(ret) print(L)
运行结果:
json 可以序列化的数据类型有:整数,字符串,列表,字典,元组(元组在使用json转成字符串 里面都变成列表了,而且转回来也是列表的格式)
json 唯独不能序列化一个集合!!
2. pickle (见下一篇博客)
优点: python中所有的数据类型都可以借助pickle序列化模块转化为字符串类型;
缺点: pickle序列化之后的内容只能由python理解;
反序列化必须依靠python代码;
3. shelve (见下下一篇博客)
优点:操作简单,直接使用序列化句柄直接操作;