表扫描开销
在《DB2数据库查询过程(Query Processing)----概述》一文中已经介绍过,表扫描是数据访问方式中最简单,最低效的一种。在所有的关系型数据库中都会有这种数据访问方式,不同系统中叫法可能不同(如direct search 、 data scan 、 tables scan),由于存在不同的表共用同一个Extent的情况,有时候人们认为将这种扫描方式称为表空间扫描(Tablespace Scan)更为确切。
表扫描准确的说叫全表扫描,顾名思义,是指通过扫描表中的所有行来找到查询语句中满足where子句查询条件的行的访问方式。采用表扫描进行的查询无论是否已经查找到满足条件的行都必须扫描到表中的全部行(因为不能判断剩下的行中是否有满足条件的),可想而知,对于大量数据而言,查询开销是非常可观的。
考虑这样一种情况:
EMPLOYEE表中含200000行数据;
每行数据的长度为200 字节(Byte);
表所在的表空间采用4KB数据页(去掉数据页头部,认为4KB数据页总可用空间为4000B),且数据页PCTFREE参数设定为30%(即每个数据页实际可用空间为4KB*(1-70%)=2800B)。
如此,一个数据页能存储的表行数为2800B/200B=14行,存储EMPLOYEE表中的全部行需要200000/14=14286页。
现在要查询EMPLOYEE中编号为123456的员工的姓名,SQL语句如下:
Select name From EMPLOYEE Where id=123456;
如果使用表扫描方式查找,就必须要将14286个数据页全部读入缓冲池,即进行14286次I/O操作。假设这些I/O操作都是随机I/O,按照一次I/O操作的经验开销为1/80秒计算,完成上面的SQL查询所花费的I/O时间 Cost(I/O)=14286*1/80=178.6秒,仅20万行的表查询花费近3分钟(CPU开销在这样的I/O开销面前可以忽略不计了)!这几乎是不可接受的。
虽然对相应列创建索引能够大大降低开销,但是一个表上过多的索引同样会对性能造成影响(通常意义上,一个表上的索引数量不宜超过5个),因此,表扫描是不可避免的。那么,如何解决表扫描带来的巨大的I/O开销问题呢?
I/O并行和磁盘条带化(I/O Parallelism and Disk Striping)
一种解决策略就是使用I/O并行,类似于将一份工作分割成10个部分,每个人只需完成1个部分,10个人同时工作的形式,将数据页分散到多个磁盘上,查询过程中所有磁盘同时工作,I/O开销就能够成倍降低。
举个例子:现在有10个磁盘供数据库使用,将磁盘编号为1--10.当将EMPLOYEE表中的所有数据行存储在磁盘上时,将数据页1存储在磁盘1上,数据页2存储在磁盘2上,数据页3存储在磁盘3上...以此类推,数据页N存储在磁盘(N-1)%10+1上。如图:
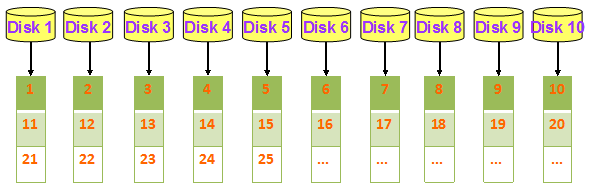
进行表扫描查询时,10个磁盘同时进行I/O操作,则虽然总的I/O次数没变,但时间开销却降为178.6/10 = 17.9秒。
这就是所谓的I/O并行,而这样使用的每一个磁盘就称为一个条带(stripe)。这种磁盘条带化策略同样应用于冗余磁盘阵列(RIAD)技术中用于提高吞吐量。
上面只是一个直观的例子,实际上是不可能以数据页为单位进行条带划分的。通常是以Extent(扩展数据块/区)为单位进行划分的。而且作为条带的设备实际上是容器。如图:
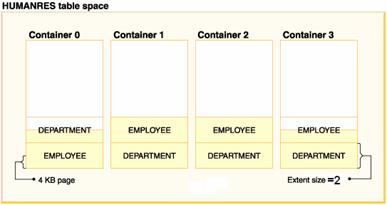
我们知道,容器可以是数据文件或者是裸设备(磁盘、磁带等),对于裸设备容器,实现的是真正的I/O并行化,因为同一时刻所有的磁盘臂都能够独自工作。而对于数据文件容器,如果这些数据文件位于一台计算机设备或者存储设备上,实现的则是伪I/O并行,I/O线程虽然是并行,但磁盘臂同一时刻只能服务于一个I/O线程。不过即便如此,伪I/O并行还是比简单的随机I/O快很多。
因此,创建表空间的时候,为其分配多个容器是非常必要的。对于Oracle数据库,表空间创建时分配容器尤其需要慎重,因为当容器不足时再行添加容器后,Oracle不会自动进行重平衡操作(重平衡即将数据重新在所有容器上平衡分配以便实现I/O的平衡,否则即使添加容器也不能显著提升性能),新版的Oracle虽然加入了自动存储管理(ASM)特性,但是限制非常大,所以最好一开始就分配适当数量的容器。对于DB2数据库则相对好很多,DB2的重平衡是非常优秀的,但是初始分配适当容器仍然是必要的,要知道重平衡操作是非常耗时的。
另外,重平衡通常是针对磁盘组而言,因为通常大型的数据库才会存在重平衡问题,而大型数据库使用的容器都是裸设备,不会是数据文件。
虽然,为了实现并行I/O而使用的磁盘条带化策略能显著提高I/O方面的性能,但是也存在一些问题。
首先,成本问题,这是显而易见的,这种策略并不能节省计算资源的开销,不管是否使用并行I/O,所需要的总的I/O数量是一样的(普通的全表扫描和磁盘条带化都属于随机I/O访问)。想要提高I/O性能就必须增加更多的磁盘设备,当然也就需要花费更多的成本。
其次,磁盘条带化实现I/O并行是一个很复杂的问题,并没有看起来那么轻松。多个磁盘的工作强度很难保证一致,如果条带磁盘组中某个磁盘过于繁忙,其I/O性能就会下降,如此不仅成为并行I/O的瓶颈,还会导致其它设备无法被充分利用,造成资源浪费。当同时进行多个SQL查询时,这种情况就非常容易发生。
最后,它会带来更多的CPU开销,CPU需要负责磁盘组的磁盘调度。不过相对于并行I/O带来的I/O性能的提升,增加的CPU开销无疑是可以接受的。
I/O预取(Prefetch I/O)
不考虑I/O并行,有没有办法提高I/O性能呢?
回顾一下磁盘结构,一次I/O的时间开销 = 磁盘臂寻道时间(seek time) + 磁盘旋转延迟(rotational latency) + 数据传输时间(transfer time)。其中寻道时间和旋转延迟是影响I/O时间的主要因素。
而对于数据库中的表,我们发现一个表中连续的数据页通常是位于磁盘上相邻的位置上。如果一次SQL查询需要进行大量I/O,那么很可能其中一个I/O请求的数据页在磁盘上相邻的其他数据页也被该查询中其它的I/O所请求,因此,可以在读入一个数据页A后接着进行一次I/O将其相邻的数据页B也读入内存中,如此读取数据页B的这次I/O就不存在磁盘臂寻道时间,而且磁盘旋转角度极小,旋转延迟也可以忽略。也就是说,该次I/O的时间开销是极小的。当后续的I/O需要请求数据页B的时候,就可以直接在内存中命中而无需进行I/O操作了。
如果不使用这种预先读取相邻数据页的策略,而是直接使用随机I/O方式进行磁盘访问,可想而知,将会导致大量的磁盘臂移动和磁盘旋转动作,耗费大量时间。
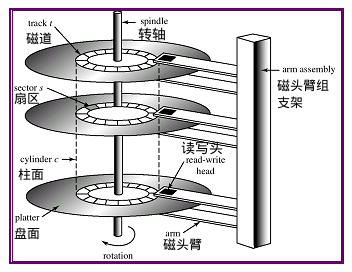
这种在数据页被请求前就将其事先读入内存的I/O策略就叫做I/O预取。
事实上,I/O预取已经被磁盘控制器(disk controller)所直接支持,无论什么时候一个磁盘页I/O被请求,磁盘控制器都会将该磁盘页所在的整个磁道读入其私有缓存中,当其他I/O请求的磁盘页在该缓存中命中后就能够避免耗时的I/O操作了。这种I/O预取策略能够比随机I/O方式快近10倍!下图是随机I/O和预取I/O的平均开销对比:

这种由磁盘控制器所支持的I/O预取存在的一个问题是:即便是只进行一个单次的I/O请求,控制器也会将整个磁道读入其私有缓存中(因为控制器不知道某次I/O是不是单独的),尽管这是不必要的。这种多余的预取将造成大概0.008ms的额外开销。
I/O顺序预取(Sequential Prefetch I/O)
DB2数据库系统提供一种更加有效的I/O预取方式,这就是I/O顺序预取。I/O顺序预取是思想是:当系统认为有必要的时候,系统会将大量连续的数据页从磁盘读入缓冲池中。通常一次I/O顺序预取的数据页数为32页。当然预取页数是可以通过Prefetch size参数自行设定的。
对于一个拥有多个容器(container)的DB来说,默认预取大小为:prefetch size = extent size * number of containers
如果只有一个container在Raid上,默认预取大小为:prefetch size = extent size * number of disks in the stripe set
如果启用了DB2_PARALLEL_IO,那么默认将启动PrefetchingSize/ExtentSize个Prefetcher,如果需要aggressive的能力(如在DSS系统中),扩大此值。如果没有启用DB2_PARALLEL_IO,那么,默认启动的Prefetcher个数等于container的个数。
DB2的I/O顺序预取不需要依赖磁盘控制器缓存,也就是说,即使磁盘控制器磁道缓存被关闭,I/O顺序预取仍然能够正常工作。顺序预取I/O时间开销的经验值同样是0.00125 秒/每次。即随机I/O效率的10倍。
I/O顺序预取技术是IBM DB2数据库系统相较其他数据库产品的一大优势,IBM也花费了大量的努力去更多的应用并收获这种I/O优势,即:当有可能的时候,将大量的I/O请求进行合理的排序以最大化I/O顺序预取的效率。
I/O列表预取(List Prefetch I/O)
如果数据库表中的连续数据页在磁盘上并非相邻的(根据数据也物理地址可以进行大致判断),那么I/O顺序预取就无法达到预期的效果,并且可能还会因为预取的额外开销影响I/O性能。
对于这种情况,DB2提供另外一种I/O预取类型:列表预取(List Prefetch)。在这种I/O方式中,数据库系统预先向磁盘控制器提供一个记录一部分需要被读入内存缓冲池的数据页的列表,磁盘控制器根据这个列表和特定的算法(如最短寻道算法、电梯算法等)来产生一个开销最小的磁盘臂移动方案。按照此方案完成清单上所有的数据页的读入后,再将另一系列数据页按此方式读入内存。下图展示了对于同一个请求数据页集合,两种不同的算法的寻道开销是不同的:
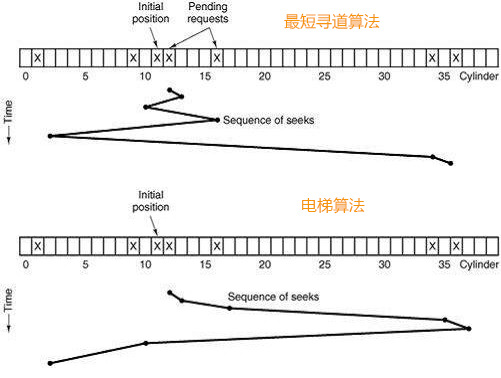
很显然,列表预取的效率是大大低于顺序预取的(后者几乎消除了寻道时间和旋转延迟,前者只是试图将寻道时间和旋转延迟最小化),但是它比随机I/O还是要快上很多的。使用列表预取,一次I/O开销的平均值为0.005 秒。下图是三种I/O方式每秒读取的数据页数的比较:

I/O预取只有对于大量的I/O才是比较有意义的,少量数据的I/O会直接使用随机I/O方式进行访问。另外,I/O预取不仅可以用于数据页的读取,同样也适用于索引页(索引页本质上也是数据页)。
I/O预取和I/O并行并不是不相容的,可以在每一个并行的磁盘设备上采用I/O预取策略,这样就能够进一步提高 I/O性能。