2.1 数据的初步诊断与探索
先学习一下Pandas
import pandas as pd df = pd.DataFrame() print(df)
运行结果如下图就说明环境配好啦
基本语法:
生成DataFrame
import pandas as pd
import numpy as np
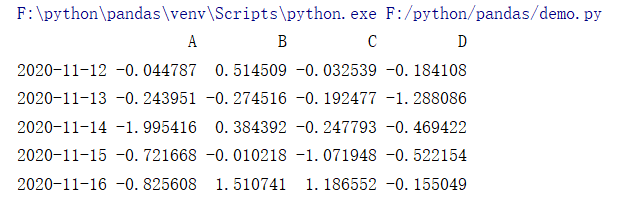
dates = pd.date_range('20201112',periods=5)
df = pd.DataFrame(np.random.randn(5, 4), index=dates, columns=list('ABCD'))
print(df)
查看 DataFrame 头部和尾部数据:
df.head()
df.tail(3)
默认显示五条数据,也可以指定。
查看数据
import pandas as pd import numpy as np dates = pd.date_range('20201112',periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD')) print(df) print(df.head(3)) #查看前三行 print(df.tail()) #查看尾部数据/默认五行 print(df.index) #显示索引 print((df.columns)) #显示列名 print(len(df.columns)) #获取字段数量/列数

2.1.1
现已使用Pandas读取数据集challenge.csv
- 请提取该数据集的字段名称,将结果存为
cols - 请获取给数据的字段和样本数量,将结果分别存为
col_num和sam_num - 请获取该数据集的前五行记录,将最后的DataFrame存为
five_data - 要求:请将
cols存为列表格式,方便后台验证
正误判定变量:cols,col_num,sam_num,five_data
import pandas as pd titanic = pd.read_csv("challenge.csv") # 获取字段名称 cols = list(titanic.columns) # 获取字段数量/列数 col_num = len(titanic.columns) # 获取样本数量/行数 sam_num = len(titanic.index) # 获取样本前5行样本 five_data= titanic.head() print(cols) print(col_num) print(sam_num ) print(five_data)
2.1.2
现已使用Numpy生成服从均匀分布的一维数据集,样本容量为100;
- 使用
scipy库中的stats模块,对生成的数据进行正态性检验,将检验的结果存为model - 提示: 可以使用
kstest()函数实现此功能;
正误判定变量:model
import numpy as np from scipy.stats import stats test_data = np.random.random(size=100) # 验证分布 model = stats.kstest(test_data,'norm') print(model)
2.2 缺失值处理和离群值检测
2.2.1
现已使用Pandas生成Series对象example_data
- 请使用
isnull()函数确定example_data是否含有缺失值,将最后的结果存为boolean_array - 请使用
fillna()函数使用字符串missing替换缺失值,将替换后的Series对象存为new_data
正误判定变量:boolean_array,new_data
import pandas as pd import numpy as np example_data = pd.Series([1,2,3,np.nan,4]) #print(example_data) # 判断是否含有缺失值 boolean_array = example_data.isnull() print(boolean_array) # 缺失值替换 new_data = example_data.fillna('missing') print(new_data)
2.3 常用的数据转换方法
2.3.1
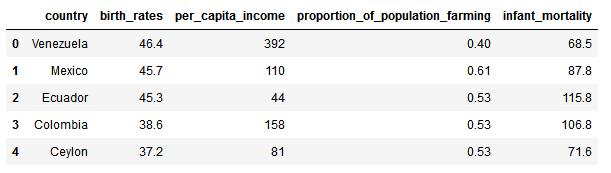
现已使用Numpy读取整个数据集birthrate.csv
- 请获取该数据集的第二列
birth_rates的最大值和最小值; - 根据Min-Max标准化的数学表达式,请将特征
birth_rates映射到区间[0, 1]之中,将其结果存为minmax_scaling_data
该数据集详情为:
正误判定变量:minmax_scaling_data
import pandas as pd data = pd.read_csv('birthrate.csv') print(data.head()) #请在下面作答 _max = max(data.birth_rates) _min = min(data.birth_rates) minmax_scaling_data = (data.birth_rates - _min)/(_max - _min) print(minmax_scaling_data)
2.3.2
现已使用Pandas读取数据集birthrate.csv
- 请对该数据集的
birth_rates特征使用四分位数作为切分点,通过qcut()函数完成等频离散化; 将最后的结果存为data_qcut
该数据集详情为:
正误判定变量:data_qcut
import pandas as pd data = pd.read_csv('birthrate.csv') #请在下面作答 data_qcut = pd.qcut(data.birth_rates,4) print(data_qcut)