在利用pandas处理表格时,往往有时我们用表格做的测试用例往往会设计考一些必填项*故意赋值为空(代表不输入)的测试用例,
比如说我们的手机号、身份证号码、社会统一信用代码等都是数字型字符串。如下所示:

pandas读取表格,会把表格中的空单元格置为float类型的Nan值,会导致数字型字符串列的数据类型从原始的str类型自动转换为float类型,如下图所示:
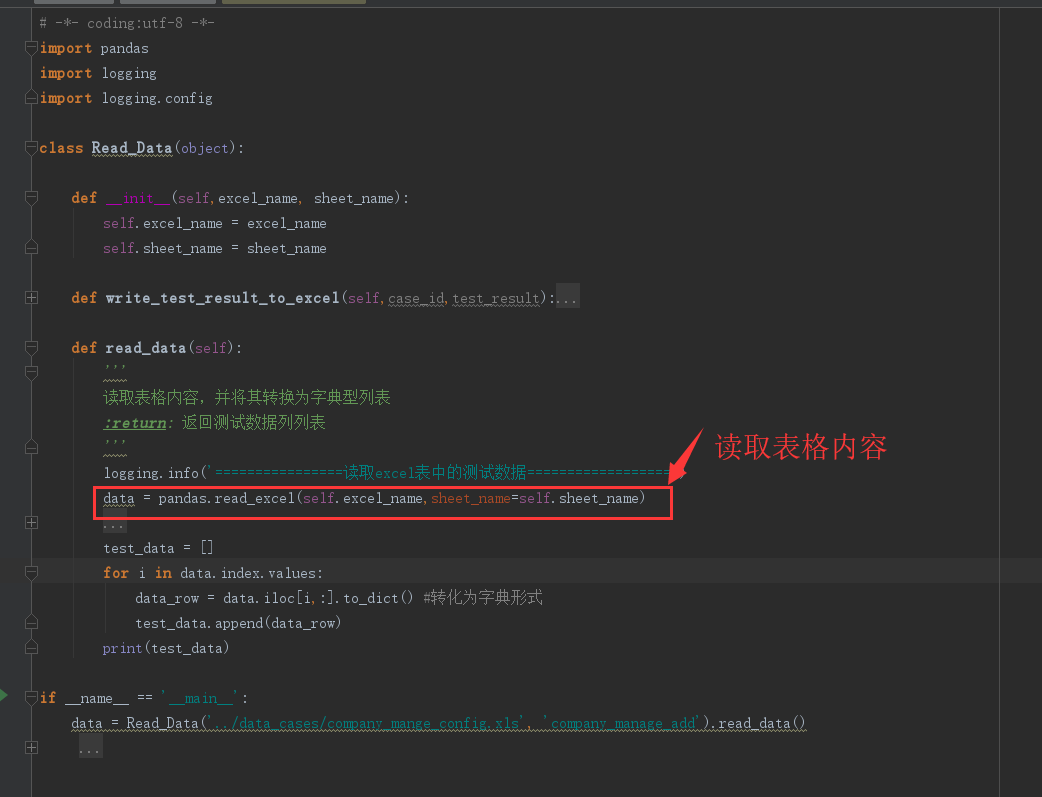
读取的效果:


从上图可看出,pandas读取excel时,遇到空白单元格会自动置为nan值,float型。
导致原始表格中的文本类型的social_code(社会信用代码)和 telno(手机号)从原始的本文str类型转变为了float类型,导致数据显示错误,不是我们想要的结果。
那如何将nan值全部置为空,并且还不会影响原始表格中的数字型字符串呢???
我们可以在读取表格时,就以字符串型读取,如下图所示:
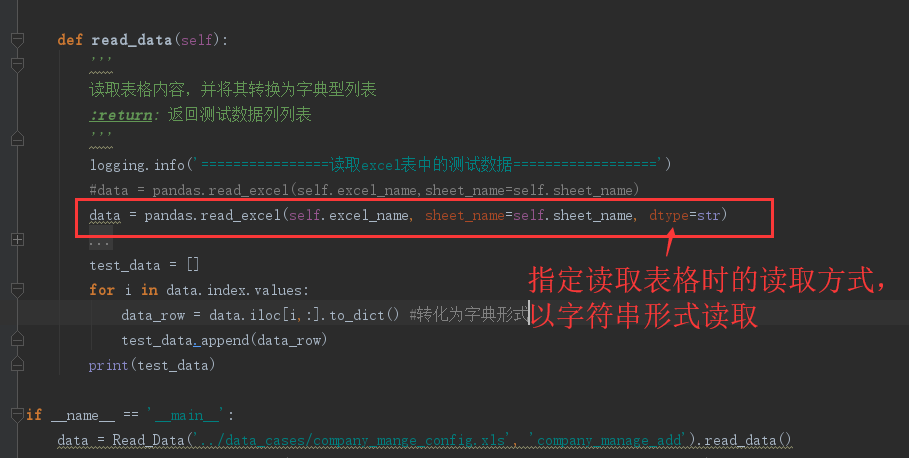
效果如下:


这时,原始的数字型字符串数据就不会受到nan值的影响了。
如果需要对nan值进行替换,直接采用fillna()填充即可。

替换、填充效果:

这样就完成了~~~~