所谓的KNN算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
这里举一个很简单的例子来理解一下KNN算法的原理,假设有以下数据,根据微信、电话、短信联系的次数将朋友进行归类为认识、普通、好友三个类别,如下:
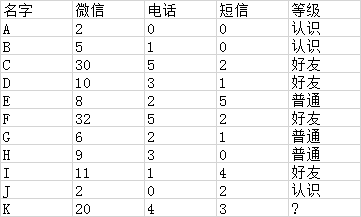
根据A-J的特征来确定K应该属于哪一类朋友?
那么就可以用下面的代码来进行归类:
#! /usr/bin/env python
# encoding:utf-8
import math
def KNNAlg():
base_data = {"A": [2, 0, 0, "认识"],
"B": [5, 1, 0, "认识"],
"C": [30, 5, 2, "好友"],
"D": [10, 3, 1, "好友"],
"E": [8, 2, 5, "普通"],
"F": [32, 5, 2, "好友"],
"G": [6, 2, 1, "普通"],
"H": [9, 3, 0, "普通"],
"I": [11, 1, 4, "好友"],
"J": [2, 0, 2, "认识"]}
target = [20,4,3] #K的数据
KNN =[]
for key,v in base_data.items():
d = math.sqrt((target[0]-v[0])**2 + (target[1]-v[1])**2 + (target[2]-v[2])**2) #计算距离
KNN.append([key,round(d,2)]) #取两位小数
KNN.sort(key=lambda dic:dic[1]) #根据第二项排序
KNN = KNN[:6] #取距离最近的6个邻居
print(KNN)
labels = {"认识": 0, "好友": 0, "普通": 0}
for s in KNN:
temp = base_data[s[0]]
#print(temp)
labels[temp[3]] += 1
labels = sorted(labels.items(),key = lambda dic: dic[1],reverse=True)
print(labels,labels[0][0],sep='
')
if __name__ == '__main__':
KNNAlg()
最后的输出:
[('好友', 4), ('普通', 2), ('认识', 0)]
好友
可以看到K是属于好友类别的。
KNN是属于惰性学习的,样本数据已经很明确的归类,新的数据只需要归类就好了,并没有一个训练的过程。其次,根据K的大小和样本容量的分布,很容易得出错误的结论,再次,样本容量很大时,计算会变得很复杂,计算量大