Python2.2之前类是没有共同的祖先的,之后,引入object类,它是所有类的共同祖先object。Python2中为了兼容,分为古典类(旧式类)和新式类。Python3中全部都是新式类。
新式类都是继承自object的,新式类可以使用super。
多继承
OCP原则:多用“继承”、少修改。
继承的用途:增强基类、实现多态。
多态
在面向对象中,父类、子类通过继承联系在一起,如果可以通过一套方法,就可以实现不同表现,就是多态。
一个类继承自多个类就是多继承,它将具有多个类的特征。
多继承弊端
多继承很好的模拟了世界,因为事物很少是单一继承,但是舍弃简单,必然引入复杂性,带来了冲突。
如同一个孩子继承了来自父母双方的特征,那么到底眼睛像爸爸还是妈妈呢?孩子究竟该像谁多一点呢?
多继承的实现会导致编译器设计的复杂度增加,所以现在很多语言也舍弃了类的多继承。
c++支持多继承,Java舍弃了多继承。
Java中,一个类可以实现多个借口,一个借口也可以继承多个接口。Java的接口很纯粹,只是方法的声明,继承者必须实现这些方法,就具有这些能力,就能干什么。
多继承可能会带来二义性,例如,猫和狗都继承自动物类,现在如果一个类多继承了猫和狗类,猫和狗都有shout方法,子类究竟继承谁的shout呢?
解决方案
实现多继承的语言,要解决二义性,深度优先或者广度优先。
Python多继承实现
class ClassName(基类列表): 类体
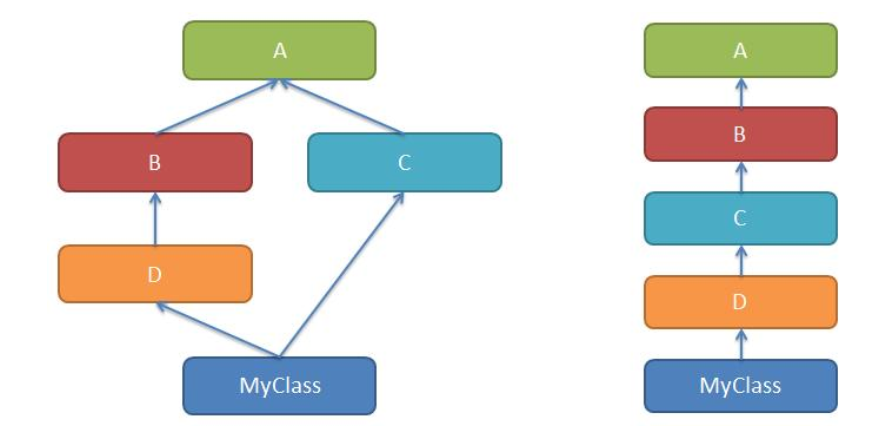
左图是多继承,右图是单一继承
多继承带来路径选择问题,究竟继承哪个父类的特征呢?
Python使用MRO(method resolution order)解决基类搜索顺序问题。
历史原因,MRO有三个搜索算法:
- 经典算法,按照定义从左到右,深度优先策略。2.2.之前,左图的MRO是MYclass,D,B,A,C,A
- 新式类算法,经典算法的升级,重复的只保留最后一个。左图的MRO是MYclass,D,B,C,A,object
- C3算法,在类被创建出来的时候,就计算出来一个MRO有序列表,2.3.之后,Python唯一支持算法。左图中的MRO是MYCLASS,d,b,c,aobject的列表。
c3算法解决了多继承的二义性。
多继承的缺点
当类很多,继承复杂的情况下, 继承路径太多,很难说清什么样的继承路径。Python语法是允许多继承,但Python代码是解释执行,只有执行到的时候,才发现错误。
团队协助开发,如果引入多继承,那代码就不可控。
不管编程语言是否支持多继承,都应当避免多继承。
Python的面向对象,我们看到的太灵活了,太开放了,所以要团队守规矩。
mixin(重要)
类有下面的继承关系
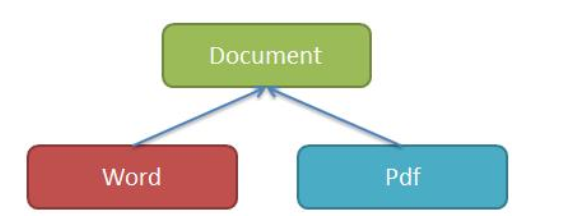
文档document类是其他所有文档类的抽象基类。Word,pdf是document的子类。
需求:为document子类提供打印能力。
思路:
1在document中提供print方法。
class Document: def __init__(self,content): self.content = content def print(self): raise NotImlementedError() class Word(Document):pass class Pdf(Document):pass
基类提供的方法不应该具体实现,因为它未必适合子类的打印,子类中需要覆盖重写。
print算是一种能力——打印能力,不是所有的document的子类都需要的,所以,从这个角度出发,有点问题。
2 需要打印的子类上增加
如果在现有子类上直接增加,违反了OCP原则,所以应该继承后增加,因此有下图。

class Printabe(): def print(self): print(self.content) class Document:#第三方库,不允许修改 def __init__(self,content): self.content = content class Word(Document):pass#第三方库,不允许修改 class Pdf(Document):pass#第三方库,不允许修改 class PrintableWord(Printabe,Word):pass print( PrintableWord.__dict__) print( PrintableWord.mro()) pw = PrintableWord("test string") pw.print() 结果为: {'__module__': '__main__', '__doc__': None} [<class '__main__.PrintableWord'>, <class '__main__.Printabe'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>] test string
看似不错,如果需要还要提供其他能力,如何继承?
应用于网络,文档应该具备序列化的能力,类上就应该实现序列化。
可序列化还可能分为使用pickle,json,messagepack等。
这个时候发现,类可以太多了,继承的方式不是很好了。
功能太多,A类需要某几样功能,B类需要另几样功能,很繁琐。
3装饰器
用装饰器增强一个类,把功能给类附加上去,那个类需要,就装饰它。
def printable(cls): def _print(self): print(self.content,"装饰器") cls.print = _print return cls class Document:#第三方库,不允许修改 def __init__(self,content): self.content = content class Word(Document):pass#第三方库,不允许修改 class Pdf(Document):pass#第三方库,不允许修改 @printable#先继承后装饰 class PrintableWord(Word):pass print( PrintableWord.__dict__) print( PrintableWord.mro()) pw = PrintableWord("test string") pw.print() @printable class PrintablePdf(Word):pass 结果为: {'__module__': '__main__', '__doc__': None, 'print': <function printable.<locals>._print at 0x0000000005A79620>} [<class '__main__.PrintableWord'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>] test string 装饰器
优点:简单方便,在需要的地方动态的增加,直接使用装饰器
4.mixin
先看代码
class Document:#第三方库,不允许修改 def __init__(self,content): self.content = content class Word(Document):pass#第三方库,不允许修改 class Pdf(Document):pass#第三方库,不允许修改 class PrintableMixin: def print(self): print(self.content,"Mixin") class PrintableWord(PrintableMixin,Word):pass print( PrintableWord.__dict__) print( PrintableWord.mro()) def printable(cls): def _print(self): print(self.content,"装饰器") cls.print = _print return cls @printable class PrintablePdf(Word):pass print(PrintablePdf.__dict__) print(PrintablePdf.mro()) 结果为: {'__module__': '__main__', '__doc__': None} [<class '__main__.PrintableWord'>, <class '__main__.PrintableMixin'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>] {'__module__': '__main__', '__doc__': None, 'print': <function printable.<locals>._print at 0x0000000005A79400>} [<class '__main__.PrintablePdf'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>]
Mixin就是其他类混合进来,同时带来了类的属性和方法。
这里看Mixin类和装饰器效果一样,也没有什么特别的,但是Mixin是类,就可以继承。
class Document:#第三方库,不允许修改 def __init__(self,content): self.content = content class Word(Document):pass#第三方库,不允许修改 class Pdf(Document):pass#第三方库,不允许修改 class PrintableMixin: def print(self): print(self.content,"Mixin") class PrintableWord(PrintableMixin,Word):pass print( PrintableWord.__dict__) print( PrintableWord.mro()) pw = PrintableWord("test string") pw.print() class SuperPrintableMixin(PrintableMixin): def print(self): print("~"*20)#打印增强 super().print() print("~"*20)#打印增强 #PrintableMixin类的继承 class SuperPrintablePdf(SuperPrintableMixin,Pdf):pass print(SuperPrintablePdf.__dict__) print(SuperPrintablePdf.mro()) spp = SuperPrintablePdf("super print pdf") spp.print() 结果为: {'__module__': '__main__', '__doc__': None} [<class '__main__.PrintableWord'>, <class '__main__.PrintableMixin'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>] test string Mixin {'__module__': '__main__', '__doc__': None} [<class '__main__.SuperPrintablePdf'>, <class '__main__.SuperPrintableMixin'>, <class '__main__.PrintableMixin'>, <class '__main__.Pdf'>, <class '__main__.Document'>, <class 'object'>] ~~~~~~~~~~~~~~~~~~~~ super print pdf Mixin ~~~~~~~~~~~~~~~~~~~~
mixin类
mixin本质上就是多继承实现的,mixin体现的是一种组合的设计模式。
在面向对象的设计中,一个复杂的类,往往需要很多功能,而这些功能有来自不同的类提供,这就需要很多的类组合在一起。
从设计模式的角度来说,多组合,少继承。
mixin类的原则
- mixin类中不应该显示的出现__init__初始化方法。
- mixin类通常不能独立工作,因为它是准备混入别的类中的部分功能实现。
- mixin类的祖先类也应是mixin类。
使用时,mixin类通常在继承列表的第一个位置,例如class PrintableWord(PrintableMixin,Word):pass
mixin类和装饰器
这两种方式都可以使用,看个人爱好。如果需要继承就得使用Mixin类的方式。
练习1,shape基类,要求所有子类都必须提供面积的计算,子类有三角形,矩形,圆。
import math class Shape: @property def area(self): raise NotImplementedError("基类未实现") class Triangle(Shape): def __init__(self,a,b,c): self.a = a self.b = b self.c = c @property def area(self): p = (self.a+self.b+self.c)/2 return math.sqrt(p*(p-self.a)*(p - self.b)*(p - self.c)) class Rectangle(Shape): def __init__(self,width,height): self.width = width self.height = height @property def area(self): return self.width*self.height class Circle(Shape): def __init__(self,radius): self.d = radius*2 @property def area(self): return math.pi*self.d*self.d*0.25 shapes = [Triangle(3,4,5),Rectangle(3,4),Circle(4)] for s in shapes: print("the area of {} = {}".format(s.__class__.__name__,s.area)) 结果为: the area of Triangle = 6.0 the area of Rectangle = 12 the area of Circle = 50.26548245743669
2.上题圆类的数据可序列化。
import json import msgpack class SerializableMixin(): def dumps(self,t = "json"): if t == "json": return json.dumps(self.__dict__) elif t== "msgpack": return msgpack.packb(self.__dict__) else: raise NotImlementedError("没有实现的序列化") class SerializableCircleMixin(SerializableMixin,Circle): pass scm = SerializableCircleMixin(4) print(scm.area) s = scm.dumps("msgpack") print(s) 结果为: 50.26548245743669 b'x81xa1dx08'
用面想对象实现LinkedList链表。
单向链表实现append,iternodes方法。
双向链表实现append,pop,insert,remove,iternodes方法。

对于链表来说,每一个结点是一个独立的对象,结点自己知道内容是什么,下一跳是什么。而链表则是一个容器,它内部装着一个个结点对象。
所以,建议设计2个类,一个是结点Node类,一个是链表LinkedList类。
单向链表
class SingleNode:#结点保存内容和下一跳 def __init__(self,item,next = None): self.item = item self.next = next def __repr__(self): return repr(self.item) class LinkedList:#容器类,某种方式存储一个节点。 def __init__(self): self.head = None self.tail = None#思考tail属性的作用 def append(self,item): node = SingleNode(item) if self.head is None: self.head = node #设置开头结点,以后不变 else: self.tail.next = node #当前最后一个结点关联下一跳 self.tail = node #更新结尾结点 return self def iternodes(self): current = self.head while current: yield current current = current.next ll = LinkedList() ll.append("abc") ll.append(1).append(2) ll.append("def") print(ll.head,ll.tail) for item in ll.iternodes(): print(item)
单向链表2
借助列表实现
class SingleNode: def __init__(self,item,next = None): self.item = item self.next = next def __repr__(self): return repr(self.item) class SingleNode:#结点保存内容和下一跳 def __init__(self,item,next = None): self.item = None self.next = next def __repr__(self): return repr(self.item) class LinkedList(): def __init__(self): self.head = None self.tail = None #思考tail的属性 self.items = [] #为什么在单向链表中使用list,因为对于不需要插入的链表来说,检索方便。 def append(self,item): node = SingleNode(item) if self.head is None: self.head = node #设置开头结点,以后不变 else: self.tail.next = node #当前最后一个结点关联下一跳 self.tail = node #更新结尾结点 self.items.append(node) return self def iternodes(self): current = self.head while current: yield current current = current.next def getitem(self,index): return self.items[index] ll = LinkedList() ll.append("abc") ll.append(1).append(2) ll.append("def") print(ll.head,ll.tail) for item in ll.iternodes(): print(item) for i in range(len(ll.items)): print(ll.getitem(i))
class SingleNode(): """ 代表一个节点""" def __init__(self,val,next = None): self.val = val self.next = next def __repr__(self): return repr(self.val) class LinkedList(): """容器类,某种方式存储一个个节点""" def __init__(self): self.nodes = []#不需要插入的列表的来说,检索方便,但是插入,remove不合适 self.head = None self.tail = None def append(self,val): node = SingleNode(val) prev = self.tail if prev is None: self.head = node else: prev.next = node self.nodes.append(node) self.tail = node def iternodes(self): current = self.head while current: yield current current = current.next def __getitem__(self,item): return self.nodes[item] ll = LinkedList() node = SingleNode(5) ll.append(node) node = SingleNode(7) ll.append(node) for node in ll.iternodes(): print(node) print(ll[1])#可以实现检索访问 结果为: 5 7 7
为什么在单向链表中使用list?
因为只有结点自己知道下一跳是谁,想直接访问某一个结点只能遍历。
借助列表就可以方便的随机访问某一个结点了。
双向链表
实现单向链表没有实现的pop,remove,insert方法。
class SingleNode:#结点保存内容和下一跳 def __init__(self,item,prev = None,next = None): self.item = item self.next = next self.prev = prev#增加上一跳 def __repr__(self): #return repr(self.item) return "({} <=={} ==>{})".format( self.prev.item if self.prev else None, self.item, self.next.item if self.next else None) class LinkedList(): def __init__(self): self.head = None self.tail = None #思考tail的属性 self.size = 0 #以后实现 def append(self,item): node = SingleNode(item) if self.head is None: self.head = node #设置开头结点,以后不变 else: self.tail.next = node #当前最后一个结点关联下一跳 node.prev = self.tail #前后关联 self.tail = node #更新结尾结点 return self def insert(self,index,item): if index<0:#不接受负数 raise IndexError("Not negative index {}".format(index)) current = None for i,node in enumerate(self.iternodes()): if i ==index:#找到了 current = node break else: #没有break,尾部追加 self.append(item) return #break,找到了 node = SingleNode(item) prev = current.prev next = current if prev is None:#首部 self.head = node else:#不是首元素 prev.next = node node.prev = prev node.next = next next.prev = node def pop(self): if self.tail is None:#空 raise Exception("empty") node = self.tail item = node.item prev = node.prev if prev is None:#only one node self.head = None self.tail = None else: prev.next = None self.tail = prev return item def remove(self,index): if self.tail is None:#空 raise Exception("empty") if index <0:#不接受负数 raise IndexError("not negative index {}".format(index)) current = None for i,node in enumerate(self.iternodes()): if i == index: current = node break else:#not found raise IndexError("wrong index {}".format(index)) prev = current.prev next = current.next #4种情况 if prev is None and next is None:#only one node self.head = None self.tail = None elif prev is None:#头部 self.head = next next.prev = None elif next is None:#尾部 self.tail = prev prev.next = None else:#在中间 prev.next = next next.prev = prev del current def iternodes(self,reverse = False): current = self.tail if reverse else self.head while current: yield current current = current.prev if reverse else current.next ll = LinkedList() ll.append("abc") ll.append(1) ll.append(2) ll.append(3) ll.append(4) ll.append(5) ll.append("def") print(ll.head,ll.tail) for x in ll.iternodes(True): print(x) print("=======================") ll.remove(6) ll.remove(5) ll.remove(0) ll.remove(1) for x in ll.iternodes(): print(x) print("``````````````````````````````````````") ll.insert(3,5) ll.insert(20,"def") ll.insert(1,2) ll.insert(0,"abc") for x in ll.iternodes(): print(x)
结果为:
(None <==abc ==>1) (5 <==def ==>None) (5 <==def ==>None) (4 <==5 ==>def) (3 <==4 ==>5) (2 <==3 ==>4) (1 <==2 ==>3) (abc <==1 ==>2) (None <==abc ==>1) ======================= (None <==1 ==>3) (1 <==3 ==>4) (3 <==4 ==>None) `````````````````````````````````````` (None <==abc ==>1) (abc <==1 ==>2) (1 <==2 ==>3) (2 <==3 ==>4) (3 <==4 ==>5) (4 <==5 ==>def) (5 <==def ==>None)
class SingleNode(): """ 代表一个节点""" def __init__(self,val,next = None,prev = None): self.val = val self.next = next self.prev = prev def __repr__(self): return repr(self.val) class LinkedList(): """容器类,某种方式存储一个个节点""" def __init__(self): #self.nodes = []#不需要插入的列表的来说,检索方便,但是插入,remove不合适 self.head = None self.tail = None def append(self,val): node = SingleNode(val) if self.head is None: self.head = node else: self.tail.next = node node.prev = self.tail self.tail = node def iternodes(self,reverse = False): current = self.tail if reverse else self.head while current: yield current current = current.prev if reverse else current.next def pop(self): if self.tail is None:#没有元素 raise Exception("empty!") tail = self.tail prev = tail.prev #next = tail.next#这一句在pop里面用不到 if prev is None:#只有一个元素 self.head = None self.tail = None else:#大于一个元素 self.tail = prev prev.next = None return tail.val def getitem(self,index):#索引拿,但是注意最后返回的是节点,不是节点的值,可以改成节点的值。 if index<0: return None current = None for i,node in enumerate(self.iternodes()): if i==index: current = node break if current is not None: return current def in ll = LinkedList() node = SingleNode(5) ll.append(node) node = SingleNode(7) ll.append(node) node = SingleNode("abc") ll.append(node) for node in ll.iternodes(): print(node) for node in ll.iternodes(True): print(node) ll.pop() ll.pop() for node in ll.iternodes(): print(node)
class SingleNode(): """ 代表一个节点""" def __init__(self,val,next = None,prev = None): self.val = val self.next = next self.prev = prev def __repr__(self): return repr(self.val) class LinkedList(): """容器类,某种方式存储一个个节点""" def __init__(self): #self.nodes = []#不需要插入的列表的来说,检索方便,但是插入,remove不合适 self.head = None self.tail = None def append(self,val): node = SingleNode(val) if self.head is None: self.head = node else: self.tail.next = node node.prev = self.tail self.tail = node def iternodes(self,reverse = False): current = self.tail if reverse else self.head while current: yield current current = current.prev if reverse else current.next def pop(self): if self.tail is None:#没有元素 raise Exception("empty!") tail = self.tail prev = tail.prev #next = tail.next#这一句在pop里面用不到 if prev is None:#只有一个元素 self.head = None self.tail = None else:#大于一个元素 self.tail = prev prev.next = None return tail.val def getitem(self,index):#索引拿,但是注意最后返回的是节点,不是节点的值,可以改成节点的值。 if index<0: return None current = None for i,node in enumerate(self.iternodes()): if i==index: current = node break if current is not None: return current def insert(self,index,val): if index<0: raise Exception("error") current = None for i,node in enumerate(self.iternodes()): if i==index: current = node break if current is None: self.append(val) return prev = current.prev node = SingleNode(val) if prev is None:#头部插入 self.head = node node.next= current current.prev = node else: node.prev = prev node.next = current current.prev = node prev.next = node ll = LinkedList() node = SingleNode(5) ll.append(node) node = SingleNode(7) ll.append(node) node = SingleNode("abc") ll.append(node) for node in ll.iternodes(): print(node) for node in ll.iternodes(True): print(node) ll.pop() ll.pop() for node in ll.iternodes(): print(node) ll.insert(6,6) ll.insert(7,7) for node in ll.iternodes(): print(node)