RDD是什么
RDD, 全称为 Resilient Distributed Datasets, 是一个弹性分布式数据集。
RDD特点
- RDD 是数据集
- RDD 是一个编程模型
- RDD 之间有依赖关系, 根据执行操作的操作符的不同, 依赖关系可以分为宽依赖和窄依赖
- RDD 是只读的
- RDD 是可以分区的
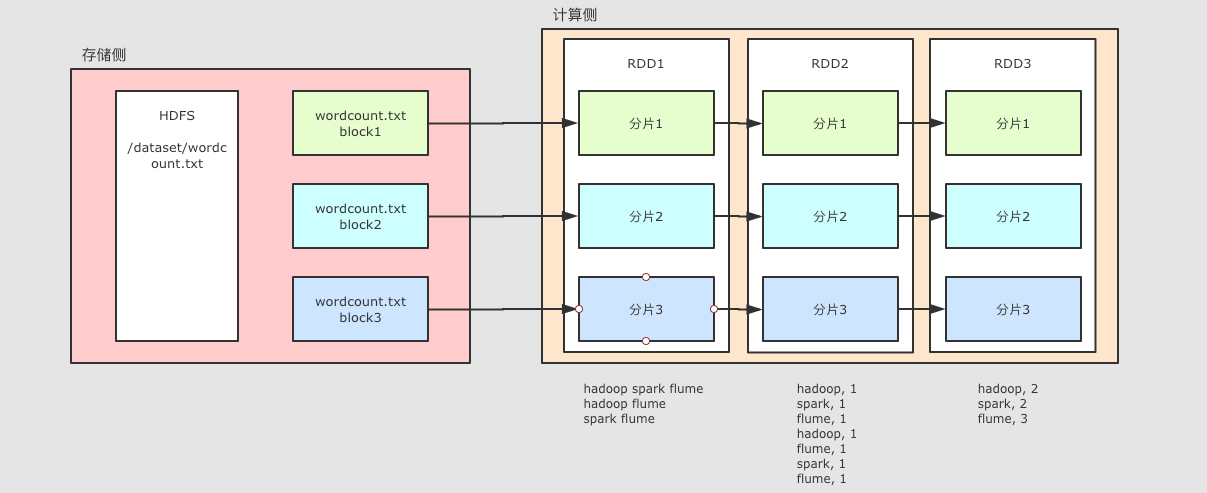
创建RDD
通过本地集合直接创建
val conf = new SparkConf().setMaster("local[2]")
val sc = new SparkContext(conf)
val list = List(1, 2, 3, 4, 5, 6)
val rddParallelize = sc.parallelize(list, 2)
val rddMake = sc.makeRDD(list, 2)
在 makeRDD 这个方法的内部, 最终也是调用了 parallelize
通过读取外部数据集来创建
val conf = new SparkConf().setMaster("local[2]")
val sc = new SparkContext(conf)
val source: RDD[String] = sc.textFile("hdfs://node01:8020/dataset/wordcount.txt")
-
textfile传入的是什么- 路径:
hdfs://file:///... /... - 如果把 Spark 应用跑在集群上, 则 Worker 有可能在任何一个节点运行
- 如果使用
file:///…形式访问本地文件的话, 要确保所有的 Worker 中对应路径上有这个文件, 否则可能会报错无法找到文件
- 路径:
-
访问方式
- 支持访问文件夹, 例如
sc.textFile("hdfs:///dataset") - 支持访问压缩文件, 例如
sc.textFile("hdfs:///dataset/words.gz") - 支持通过通配符访问, 例如
sc.textFile("hdfs:///dataset/*.txt")
- 支持访问文件夹, 例如
-
分区
- 默认情况下读取 HDFS 中文件的时候, 每个 HDFS 的
block对应一个 RDD 的partition,block的默认是128M - 通过第二个参数, 可以指定分区数量, 例如
sc.textFile("hdfs://node01:8020/dataset/wordcount.txt", 20) - 如果通过第二个参数指定了分区, 这个分区数量一定不能小于
block数 通常每个 CPU core 对应 2 - 4 个分区是合理的值
- 默认情况下读取 HDFS 中文件的时候, 每个 HDFS 的
-
支持的平台
- 支持 Hadoop 的几乎所有数据格式, 支持 HDFS 的访问
- 通过第三方的支持, 可以访问AWS和阿里云中的文件, 详情查看对应平台的 API
通过其它的 RDD 衍生而来
val conf = new SparkConf().setMaster("local[2]")
val sc = new SparkContext(conf)
val source: RDD[String] = sc.textFile("hdfs://node01:8020/dataset/wordcount.txt", 20)
val words = source.flatMap { line => line.split(" ") }
source是通过读取 HDFS 中的文件所创建的words是通过source调用算子map生成的新 RDD
RDD算子
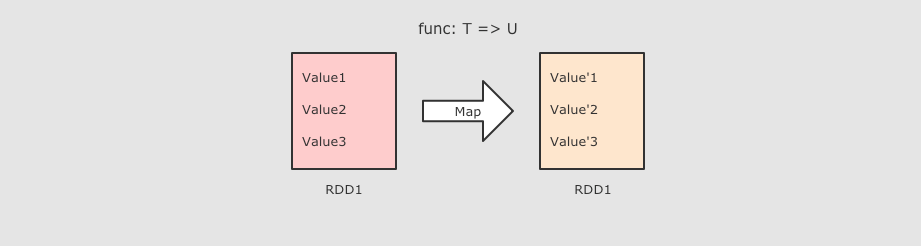
map算子
@Test
def mapTest():Unit = {
val rdd1 = sc.parallelize(Seq(1,2,3))
val rdd2 = rdd1.map(item => item*10)
val result: Array[Int] = rdd2.collect()
result.foreach(item => println(item))
sc.stop()
}

-
作用
把 RDD 中的数据 一对一 的转为另一种形式
-
调用
def map[U: ClassTag](f: T ⇒ U): RDD[U]
-
参数
f→ Map 算子是原RDD → 新RDD的过程, 这个函数的参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据 -
注意点
Map 是一对一, 如果函数是
String → Array[String]则新的 RDD 中每条数据就是一个数组
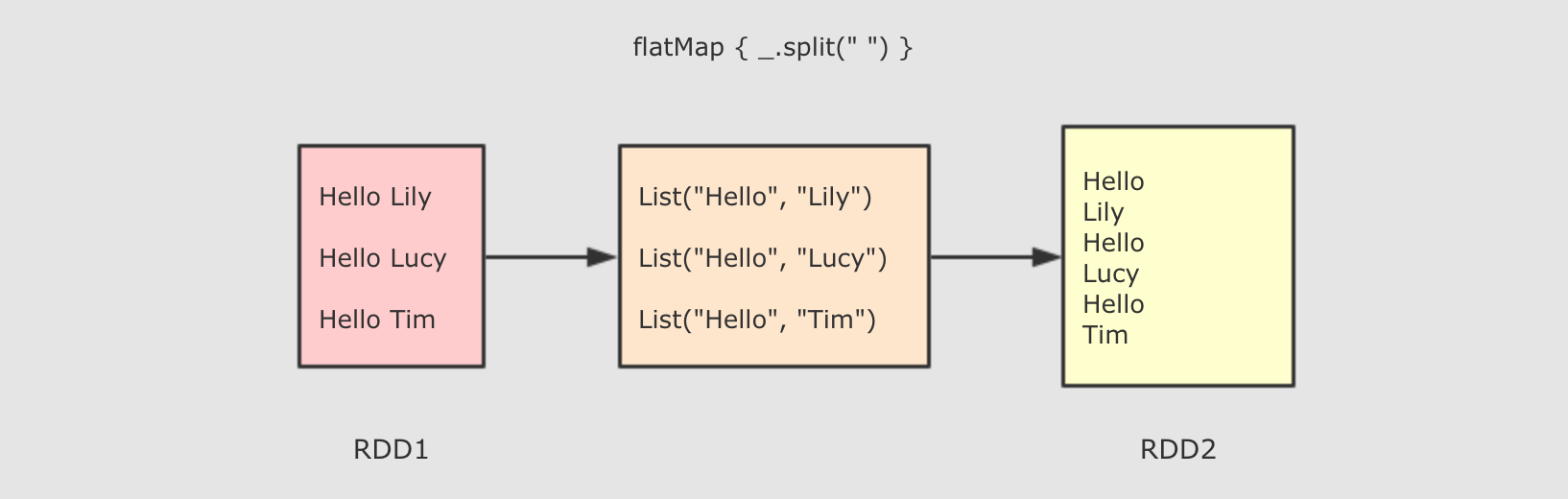
FlatMap算子
@Test
def flatmap():Unit={
val rdd1 = sc.parallelize(Seq("Hello ll","Hello lili","Hello XX"))
val rdd2 = rdd1.flatMap(item => item.split(" ") )
val result = rdd2.collect()
result.foreach(item => println(item))
sc.stop()
}

-
作用
FlatMap 算子和 Map 算子类似, 但是 FlatMap 是一对多
-
调用
def flatMap[U: ClassTag](f: T ⇒ List[U]): RDD[U]
-
参数
f→ 参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据, 需要注意的是返回值是一个集合, 集合中的数据会被展平后再放入新的 RDD -
注意点
flatMap 其实是两个操作, 是
map + flatten, 也就是先转换, 后把转换而来的 List 展开
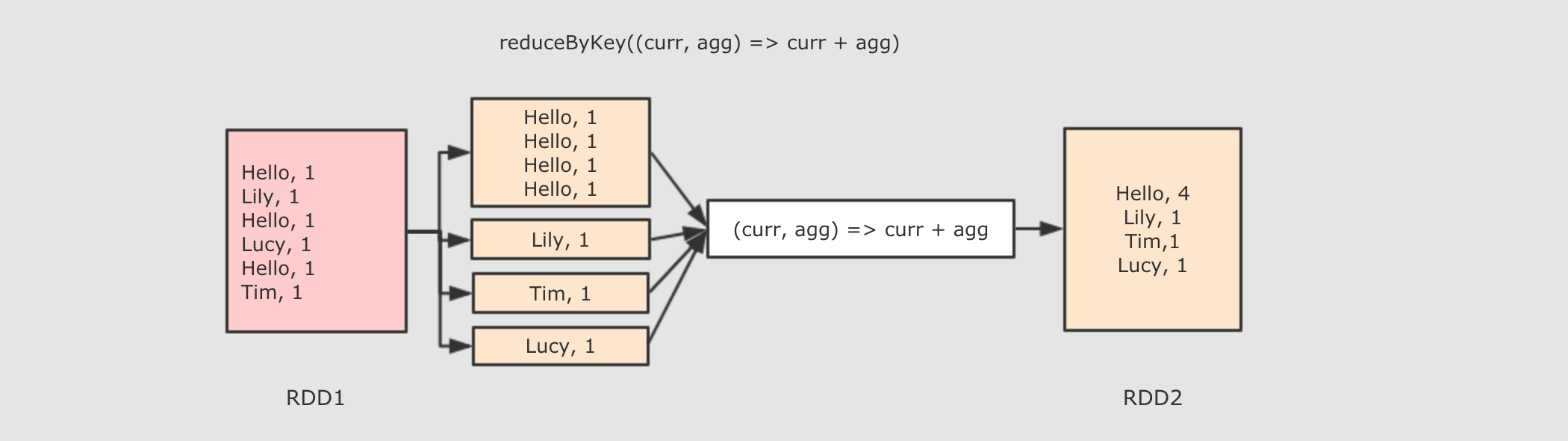
ReduceByKey算子
@Test
def reduceByKey():Unit={
val rdd1 = sc.parallelize(Seq("Hello ll","Hello lili","Hello XX"))
val rdd2 = rdd1.flatMap(item => item.split(" ") )
.map(item => (item,1))
.reduceByKey((curr,agg) => curr+agg)
val rdd3 = rdd2.collect()
rdd3.foreach(item => println(item))
sc.stop()
}

-
作用
首先按照 Key 分组, 接下来把整组的 Value 计算出一个聚合值, 这个操作非常类似于 MapReduce 中的 Reduce
调用
def reduceByKey(func: (V, V) ⇒ V): RDD[(K, V)]
-
参数
func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果
-
注意点
- ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple2
- ReduceByKey 是一个需要 Shuffled 的操作
- 和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少