贝叶斯公式:
$P(Y|X)=frac{P(X|Y)P(Y)}{P(X)}$
由以下的联合概率公式推导:
P(Y,X) = P(Y|X)P(X)=P(X|Y)P(Y)
P(Y)是先验概率,P(Y|X)是后验概率,P(Y,X)是联合概率。
机器学习中的贝叶斯:
X理解成“具有某特征”,把Y理解成“类别标签”,“属于某类”的标签(1,-1),贝叶斯公式就变形为:
$P(“属于某类”|“具有某特征”)=frac{P(“具有某特征”|“属于某类”)P(“属于某类”)}{P(“具有某特征”)}$
二分类问题的最终目的就是要判断P(“属于某类”|“具有某特征”)大于0.5,贝叶斯方法把计算“具有某特征的条件下属于某类”的概率转换成需要计算“属于某类的条件下具有某特征”的概率.
条件独立假设:
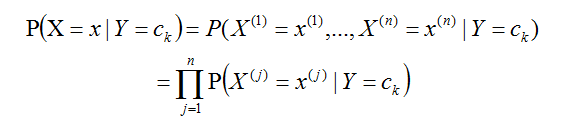
朴素贝叶斯:
1.朴素贝叶斯(naive Bayes)法是是基于贝叶斯定理 和 特征条件独立假设的分类方法,将贝叶斯定理变为朴素.
比如在垃圾邮件判别中:
对句子(“我”,“司”,“可”,“办理”,“正规发票”)进行垃圾邮件判定:
由:
$P((“我”,“司”,“可”,“办理”,“正规发票”)|S)$
转变为:
$P(“我”|S)P(“司”|S)P(“可”|S)P(“办理”|S)P(“正规发票”|S)$
朴素贝叶斯中语句中词语的顺序对结果的判别是没有影响的, 称为词袋模型(bag of words)
2.处理重复词语的三种方式
a.多项式模型:重复词出现几次算几次
$P(x_{i}|y_{k}) = frac{N_{y_{k}x_{i}}+alpha}{N_{y_{k}}+alpha n}$
b.伯努利模型:重复词只算一次
如果特征值$x_{i}$值为1,那么
$P(x_{i}|y_{k}) = P(x_{i}=1|y_{k})$
如果特征值$x_{i}$值为0,那么
$P(x_{i}|y_{k}) = 1-P(x_{i}=1|y_{k})$
c.混合模型:在计算句子概率时,不考虑重复词语出现的次数,但是在统计计算词语的概率P(“词语”|S)时,却考虑重复词语的出现次数.
三种模型的关系:

3.平滑技术
原因:当数据集太小时, 为出现的词的后验概率为0.平滑技术都是给未出现在训练集中的词语一个估计的概率,而相应地调低其他已经出现的词语的概率。
拉普拉斯平滑:分子和分母都加1.
 变为:
变为:![]()
a.伯努利模型:
$P(“正规发票”|S)=frac{出现“正规发票”的垃圾邮件的封数+1}{每封垃圾邮件中所有词出现次数(出现了只计算一次)的总和+2}$
b.多项式模型
$P(“发票”|S)=frac{每封垃圾邮件中出现“发票”的次数的总和+1}{每封垃圾邮件中所有词出现次数(计算重复次数)的总和+被统计的词表的词语数量}$
sklearn中调用朴素贝叶斯:
from sklearn import datasets
iris = datasets.load_iris()
iris.data[:10]
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import BaseDiscreteNB
from sklearn.naive_bayes import MultinomialNB
gnb = GaussianNB()
gnb_pred = gnb.fit(iris.data, iris.target).predict(iris.data)
gnb_right_num = (iris.target == gnb_pred).sum()
mnb = MultinomialNB()
mnb_pred = gnb.fit(iris.data, iris.target).predict(iris.data)
mnb_right_num = (iris.target == mnb_pred).sum()
print("Total testing num :%d , GaussianNB bayes accuracy :%f" %(iris.data.shape[0], float(gnb_right_num)/iris.data.shape[0]))
#Total testing num :150 , GaussianNB bayes accuracy :0.960000
print("Total testing num :%d , MultinomialNB bayes accuracy :%f" %(iris.data.shape[0], float(mnb_right_num)/iris.data.shape[0]))
#Total testing num :150 , MultinomialNB bayes accuracy :0.960000