GBDT(Gradient Boosting Decision Tree)
GBDT是一个应用很广泛的算法,可以用来做分类、回归(可用于二分类问题,设定阈值,大于阈值为正例,反之为负例)。其是一个框架,里面可以套入很多不同的算法,GBDT中的基函数都是回归树,回归树结果是会得一个预测值,所以结果累加是有意义的。与传统的Boost的区别是,每一次的计算是为了减少上一次的残差(residual)。在Gradient Boost中,每个新的模型的简历是为了使得之前模型的残差往梯度方向减少,与传统Boost对正确、错误的样本进行加权不同。
一.算法
目标:
给定输入向量x和输出变量y组成的若干训练样本(x1,y1),(x2,y2),…,(xn,yn),目标是找到近似函数F(x),使得损失函数L(y,F(x))的损失值最小
损失函数:
1.平方损失函数:

2.绝对值损失函数:|y-F(x)|
残差:真实值与预测值得差值

伪残差:
真实值-预测值*shrinkage
最优函数:
![{displaystyle {hat {F}}={underset {F}{arg min }}\,mathbb {E} _{x,y}[L(y,F(x))]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/655597bea9c34023b858924a1cf23b177042291c)
F(x)是一族基函数fi(x)的加权和:

梯度提升方法寻找最优解F(x),使得损失函数在训练集上的期望最小。

以贪心的思路扩展得到Fm(x)

贪心法在每次选择最优基函数f时仍然困难,我们会转换成更好求解的近似值:
使用梯度下降的方法近似计算将样本带入基函数f得到f(x1),f(x2),...,f(xn),从而L退化为向量L(y1,f(x1)),L(y2,f(x2)),...,L(yn,f(xn))

上式中的权值γ为梯度下降的步长,使用线性搜索求最优步长

具体求解过程为:
输入:

1.初始化模型为常数:

2.循环m=1到M(迭代次数)
a.计算为残差:
![r_{im} = -left[frac{partial L(y_i, F(x_i))}{partial F(x_i)}
ight]_{F(x)=F_{m-1}(x)} quad mbox{for } i=1,ldots,n.](https://wikimedia.org/api/rest_v1/media/math/render/svg/724e7996c78440be2dce585a00e39ca9c561775b)
b.用训练集

c.计算步长:

d.更新模型:

3.输出模型:

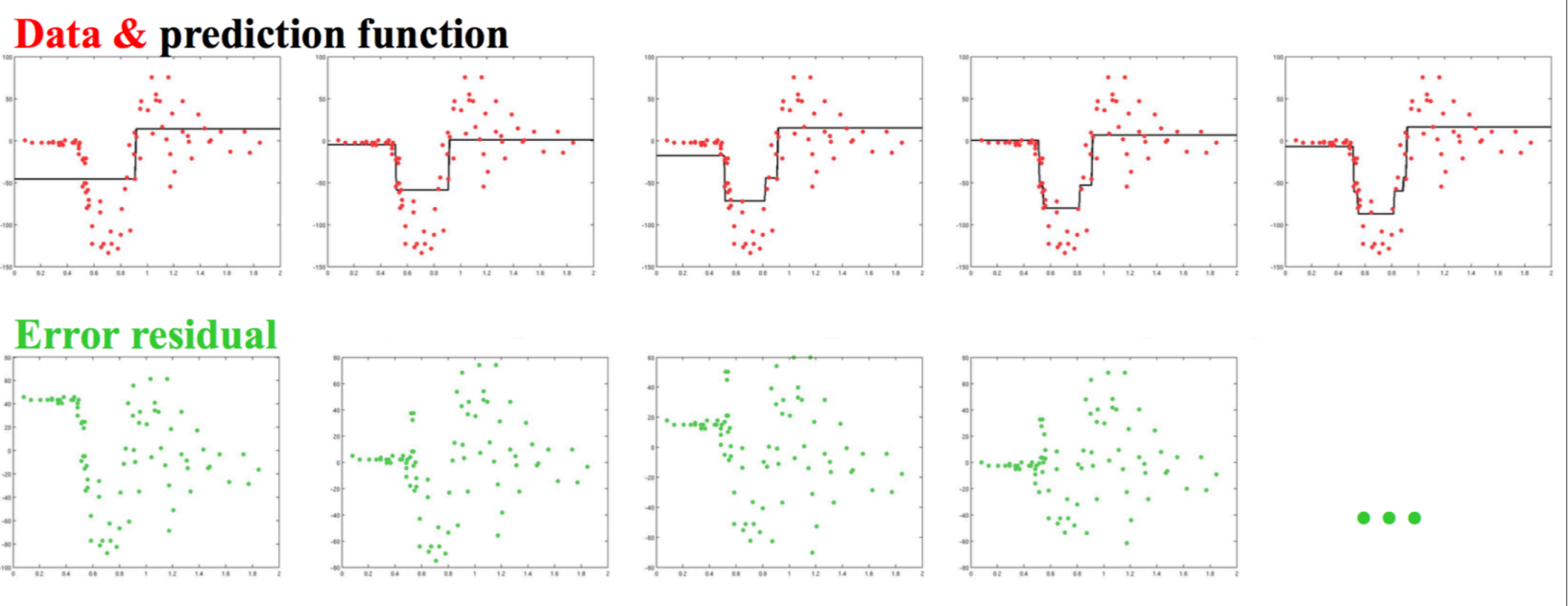
GBDT拟合图例:

二.正则化
对训练集拟合过高会降低模型的泛化能力,需要使用正则化技术来降低过拟合。
1.对复杂模型增加惩罚项,如:模型复杂度正比于叶结点数目或者叶结点预测值的平方和等
2.用于决策树剪枝
3.叶结点数目控制了树的层数,一般选择4≤J≤8。
4.叶结点包含的最少样本数目,防止出现过小的叶结点,降低预测方差
5.梯度提升迭代次数M:增加M可降低训练集的损失值,但有过拟合风险
Shrinkage(衰减):通过如下修改更新规则进行正则化(通过降低后面树的权重,降低模型复杂度,防止过拟合)

ν为学习率。
ν=1即为原始模型;推荐选择v<0.1的小学习率。过小的学习率会造成计算次数增多。
Shrinkage和梯度下降法中学习步长alpha的关系。shrinkage设小了只会让学习更慢,设大了就等于没设,它适用于所有增量迭代求解问题;而Gradient的步长设小了容易陷入局部最优点,设大了容易不收敛。它仅用于用梯度下降求解。这两者其实没太大关系。
随机梯度提升Stochastic gradient boosting:
每次迭代都对伪残差样本采用无放回的降采样,用部分样本训练基函数的参数。令训练样本数占所有伪残差样本的比例为f;f=1即为原始模型:推荐0.5≤f≤0.8.
较小的f能够增强随机性,防止过拟合,并且收敛的快。
降采样的额外好处是能够使用剩余样本做模型验证。
GBDT重拍序:
(GBDT预测值到输出概率[0,1]的sigmoid转换)
三.总结
1.函数估计本来被认为是在函数空间而非参数空间的数值优化问题,而阶段性的加性扩展和梯度下降手段将函数估计转换成参数估计。
2.损失函数是最小平方误差、绝对值误差等,则为回归问题;而误差函数换成多类别Logistic似然函数,则成为分类问题。
3.对目标函数分解成若干基函数的加权和,是常见的技术手段