进程
什么是进程
进程:正在进行的一个过程或者一个任务,执行任务的是cpu。
进程与程序的区别
程序仅仅是一堆代码而已,而进程指的是程序的运行过程。
比喻:食谱就是程序,而进程就是做这道菜的过程:阅读食谱、放料、等。
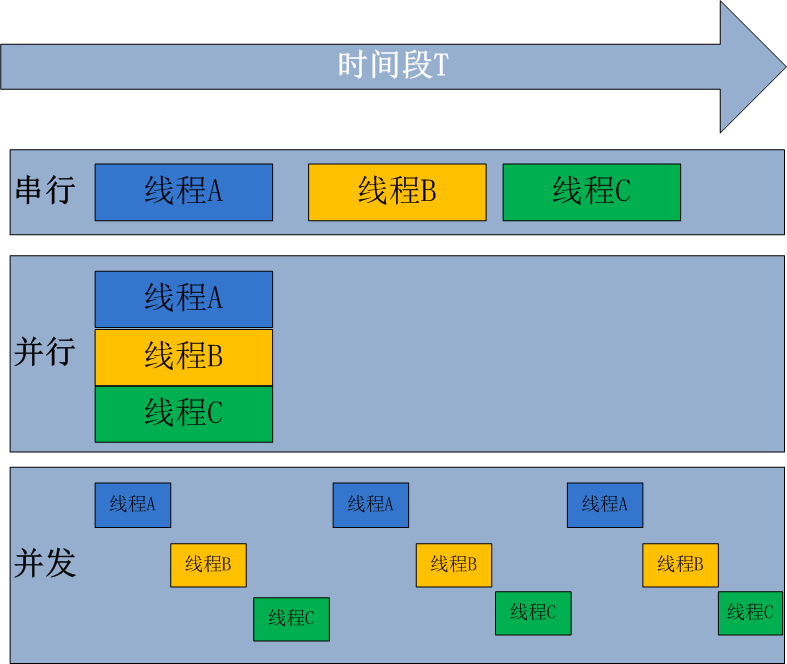
并发与并行
无论是并发还是并行,在用户看起来都是同时运行的。不管是进程还是线程,都只是一个任务而已,而真正执行任务的是cpu。cpu同一时刻只能执行一个任务。
- 并发(具备处理多个任务的能力):伪并行,看起来是同时。单个cpu + 多道技术就可以实现并发。
你是一个cpu,你同时谈了三个女朋友,每一个都可以是一个恋爱任务,你被这三个任务共享。 要玩出并发恋爱的效果,应该是你先跟女友1去看电影,看了一会说:不好,我要拉肚子,然后跑去跟第二个女友吃饭,吃了一会说:那啥,我 去趟洗手间,然后跑去跟女友3开了个房 - 并行(具备同时处理多个任务的能力):同时运行,只有具备多个cpu才能实现并行。
区别:一个是同一时间段、一个是同一时刻。
进程的状态
-
就绪:开始一个新的任务
-
运行:正在运行这个任务
-
挂起:这个任务遇到IO就阻塞。然后让出cpu,给其他任务去执行。
开启进程的两种方式
注意:windows中Process()一定要在if name == 'main'下
-
普通方式
def func1(title): print(title) if __name__ == '__main__': p1 = Process(target=func1, args=('子进程1',)) p2 = Process(target=func1, args=('子进程2',)) p3 = Process(target=func1, args=('子进程3',)) p1.start() p2.start() p3.start() print('主进程') -
类创建
from multiprocessing import Process class MyProcess(Process): def __init__(self, title): super(MyProcess, self).__init__() self.title = title def run(self): print(self.title) if __name__ == '__main__': p1 = MyProcess('子进程1') p2 = MyProcess('子进程2') p3 = MyProcess('子进程3') p1.start() p2.start() p3.start() print('主进程')
进程的相关方法和属性
-
p.start():启动进程,调用子进程的run()
-
p.terminate():强制终止进程p,谨慎使用
-
p.is_alive():判断进程是否存活,布尔值
-
p.join():感知一个子进程的结束,将异步改为同步
import time from multiprocessing import Process def func(arg1, arg2): print('*' * arg1) time.sleep(5) print('*' * arg2) if __name__ == '__main__': p = Process(target=func, args=(10, 20)) p.start() print('开启子进程') p.join() # 感知一个子进程的结束,将异步的程序改为同步 print('子进程都运行完了')疑问:必须明确,join是让谁等,是让主进程等子进程p.start()后。子进程就已经并发执行了。当有多个join时,四个join花费的时间也是耗费时间最长的那个子进程
-
p.daemon = True:默认false,设为true
import time from multiprocessing import Process def task(name): print('%s is piao ing' % name) time.sleep(3) print('%s is piao end' % name) if __name__ == '__main__': p = Process(target=task, args=('egon',)) p.daemon = True # 一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 p.start() time.sleep(1) # 子进程只执行一会 # time.sleep(5) # 子进程会执行完毕 print('主') # 只要终端打印出这一行内容,那么守护进程p也就跟着结束掉了代表p为守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
比喻:皇帝身边的老太监:皇帝驾崩,老太监跟着死。
-
p.name:进程的名称
-
p.pid:进程的pid
进程间的数据隔离问题
import os, time
from multiprocessing import Process
def func():
global n
n = 0
print('子--start:%s' % os.getpid(), n)
if __name__ == '__main__':
n = 100
print('主--start:%s' % os.getpid(), n)
p = Process(target=func, )
p.start()
time.sleep(3)
print('尽管使用了全局变量n, 但是不会修改n的值,依然是 % d' % n)
print('主--end:%s' % os.getpid(), n)
"""
主--start:15704 100
子--start:7076 0
尽管使用了全局变量n, 但是不会修改n的值,依然是 100
主--end:15704 100
"""
锁
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,
而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理。
同一终端打印
-
未加锁
# 并发运行,效率高,但竞争同一打印终端,带来了打印错乱 from multiprocessing import Process import os, time def work(): print('%s is running' % os.getpid()) time.sleep(2) print('%s is done' % os.getpid()) if __name__ == '__main__': for i in range(3): p = Process(target=work) p.start() """ 13924 is running 13576 is running 10080 is running 13924 is done 13576 is done 10080 is done """ -
加锁
# 由并发变成了串行,牺牲了运行效率,但避免了竞争
from multiprocessing import Process, Lock
import os, time
def work(lock):
lock.acquire()
print('%s is running' % os.getpid())
time.sleep(2)
print('%s is done' % os.getpid())
lock.release()
if __name__ == '__main__':
lock = Lock()
for i in range(3):
p = Process(target=work, args=(lock,))
p.start()
"""
3964 is running
3964 is done
14000 is running
14000 is done
11592 is running
11592 is done
"""
模拟抢票
#! /usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ = "ziya"
# Date: 2018-09-07
import json, time
from multiprocessing import Process
from multiprocessing import Lock
def show(i):
with open('ticket') as f:
ticket = json.load(f).get('ticket')
print('余票为:%s' % ticket)
def buy(i, lock):
# 自动加锁和解锁
with lock:
with open('ticket') as f:
ticket = json.load(f).get('ticket')
time.sleep(0.1)
if ticket:
ticket -= 1
print('%s买到了票' % i)
else:
print('%s凉凉' % i)
time.sleep(0.1)
with open('ticket', 'w') as f:
json.dump({"ticket": ticket, }, f)
if __name__ == '__main__':
for i in range(10):
p = Process(target=show, args=(i,))
p.start()
lock = Lock()
for i in range(10):
p = Process(target=buy, args=(i, lock))
p.start()
总结:加锁能保证多个进程修改同一个数据时,同一时间只能有一个任务可以进行修改,虽然牺牲了效率,但保证了数据安全。
缺点
- 效率低
- 需要手动进行加锁处理
所以我们需要更好的方式来解决此问题:队列和管道。都是将数据存放于内存中。
队列queue(推荐使用)
def produce(q):
q.put('hello')
def consume(q):
print(q.get())
if __name__ == '__main__':
q = Queue()
p = Process(target=produce,args=(q,))
p.start()
c = Process(target=consume,args=(q,))
c.start()
"""
q = Queue() # 省略则无大小限制,存放的不是数据大小。而且最大项数,但是也受限于内存大小。
q.put():放,满了会阻塞
q.get():拿:空了会阻塞
q.get_nowait():当队列为空时,不会等待。直接跑出异常,可以捕捉。
q.full():判断是否满了
q.empty():判断是否空了
"""
生产者消费者模型
为什么要有这个模型
- 平衡生产者和消费者之间的速度差
- 程序之间解耦
JoinableQueue实现生产者消费者模型
from multiprocessing import Process, JoinableQueue
import time,random,os
def consumer(q):
while True:
res=q.get()
time.sleep(random.randint(1,3))
print('�33[45m%s 吃 %s�33[0m' %(os.getpid(),res))
q.task_done() # 向q.join()发送一次信号,证明一个数据已经被取走了
def producer(name,q):
for i in range(10):
time.sleep(random.randint(1,3))
res='%s%s' %(name,i)
q.put(res)
print('�33[44m%s 生产了 %s�33[0m' %(os.getpid(),res))
q.join() # 阻塞。感知一个队列中的数据,全部被执行完毕
if __name__ == '__main__':
q=JoinableQueue()
#生产者们:即厨师们
p1=Process(target=producer,args=('包子',q))
p2=Process(target=producer,args=('骨头',q))
p3=Process(target=producer,args=('泔水',q))
#消费者们:即吃货们
c1=Process(target=consumer,args=(q,))
c2=Process(target=consumer,args=(q,))
c1.daemon=True
c2.daemon=True
#开始
p_l=[p1,p2,p3,c1,c2]
for p in p_l:
p.start()
p1.join()
p2.join()
p3.join()
print('主')
#主进程等--->p1,p2,p3等---->c1,c2
#p1,p2,p3结束了,证明c1,c2肯定全都收完了p1,p2,p3发到队列的数据
#因而c1,c2也没有存在的价值了,应该随着主进程的结束而结束,所以设置成守护进程
进程池
为什么有进程池的概念
不可能开启无限进程,一般有几个核就开几个。否则开启过多进程会造成系统调度变慢、效率反而会下降所以创建一个属于子进程的池子,对进程数加以控制
from multiprocessing import Pool
p = Pool(5) # 默认使用os.cpu_count(),一旦创建,至始至终就这5个进程交替,不会开启其他进程
p.close() # 关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成
p.join() # 等待所有工作进程退出。此方法只能在close()或teminate()之后调用
方法
- p.map(func, range(100)):自带join
- p.apply_async(func, args, kwargs) :异步调用,p.close()、p.join()
- p.apply(func, ):同步调用,直到本次任务拿到返回值,或者结束
返回值
- p.apply():同步的,直接取得结果,就是func的返回值
- p.apply_async(func,args,kwargs):异步的,需要p.get()
回调函数
回调函数:可以为每个进程或线程绑定一个函数,该函数在进程或线程的任务执行完毕后自动触发
并接收任务的返回值当作参数。
- p.apply_async(get, args=(url,), callback=func)func是主进程执行的
多进程实现socket服务端的并发
服务端
import socket
from multiprocessing import Process
ip_port = ('127.0.0.1', 8001)
buffsize = 1024
def pro(conn):
while True:
try:
data = '>>>: 你好'
print('准备给客户端发送消息', data)
conn.send(data.encode('utf-8'))
msg = conn.recv(buffsize).decode('utf-8')
print('收到客户端的消息', msg)
except Exception as e:
break
conn.close()
if __name__ == '__main__':
server = socket.socket()
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(ip_port)
server.listen(5)
while True:
conn, addr = server.accept()
print(conn, addr)
p = Process(target=pro, args=(conn,))
p.start()
server.close()
客户端
import socket
ip_port = ('127.0.0.1', 8001)
buffsize = 1024
client = socket.socket()
client.connect(ip_port)
while 1:
data = client.recv(buffsize).decode('utf-8')
print('收到服务器发来的消息', data)
msg = input('>>>:')
if not msg: continue
print('准备给服务器发送消息', msg)
client.send(msg.encode('utf-8'))
client.close()
问题
每来一个客户端,都在服务端开启一个进程,如果并发来一个万个客户端,要开启一万个进程吗,你自己尝试着在你自己的机器上开启一万个,10万个进程试一试。
解决方法:进程池
进程池实现socket服务端并发
服务端
from socket import *
from multiprocessing import Pool
import os
def talk(conn,client_addr):
print('进程pid: %s' %os.getpid())
while True:
try:
msg=conn.recv(1024)
if not msg:break
conn.send(msg.upper())
except Exception:
break
if __name__ == '__main__':
server=socket(AF_INET,SOCK_STREAM)
server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server.bind(('127.0.0.1',8080))
server.listen(5)
p=Pool()
while True:
conn,client_addr=server.accept()
p.apply_async(talk,args=(conn,client_addr))
# p.apply(talk,args=(conn,client_addr)) # 同步的话,则同一时间只有一个客户端能访问
客户端
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
msg=client.recv(1024)
print(msg.decode('utf-8'))