OO第三单元作业总结
1. JML语言
理论基础、应用工具链情况
(1)jml表达式
使用JML的话,我们就能够描述一个方法的预期的功能而不管他如何实现,让我们最开始能尽量从面向对象的角度进行编程,最先去关注整体的设计,再去关注具体方法的实现。
JML引入了大量用于描述行为的结构,比如有模型域、量词、断言可视范围、预处理、后处理、条件继承以及正常行为(与异常行为相对)规范等等。
相关语法主要有
1.requires 前置条件
2.assignable 可以修改的成员的属性
3.ensure 后置条件
4. esult 方法执行后的结果
5.old 在方法执行的取值
6.max 最大值
7.min 最小值
8. um_of 总数量
9.constraint 状态变化约束
10.invariant,定义了一个方法的不变的属性
......
(2)jml应用工具链
我们最主要使用的是openjml,其功能如下

下面我就openjml的使用进行一个简单的演示。
public class Sub {
//@ requires a > 0;
//@ requires b > 0;
//@ ensures
esult == a-b;
public static int sub(int a, int b){
return a-b;
}
public static void main(String args[]){
System.out.println(sub(2,3));
}
}
(1)java -jar openjml.jar -check Sub.java
我们可以看到,没有报错信息。
我们尝试去掉@ ensures
esult == a-b;的分号,可以看到报错结果如下
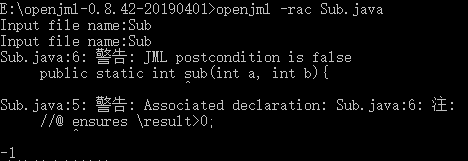
(2)openjml -rac Sub.java
现在,我们尝试增加一个后置条件@ensures esult>0;
由于2-3<0;明显不符合result>0的要求。
在运行中,我们可以看到如下报错
当然,对于jml的验证工具不止于此,jmlunit也是一个非常好用的工具。
下面就让我们一起来看看JMLUnit的使用。
2. JMLUnit测试
我用jmlunitng对第一部分的Sub进行了简单的测试,首先,我进行编译生成的目录树如下图
再用Sub_JML_Test进行测试,测试结果如下:
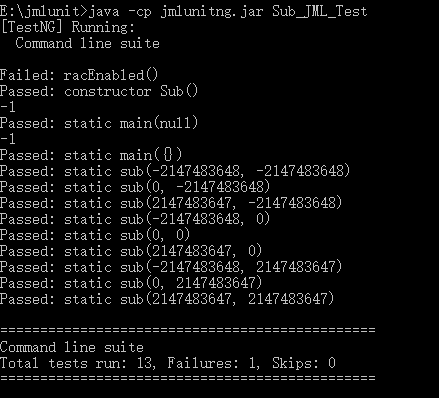
我们可以看出,该测试对各种边界条件都进行了很好的测试。
我们再加上加法指令,效果如图

在此,就暂时不对更复杂的情况进行举例了。
3.架构设计
(1)第一次作业
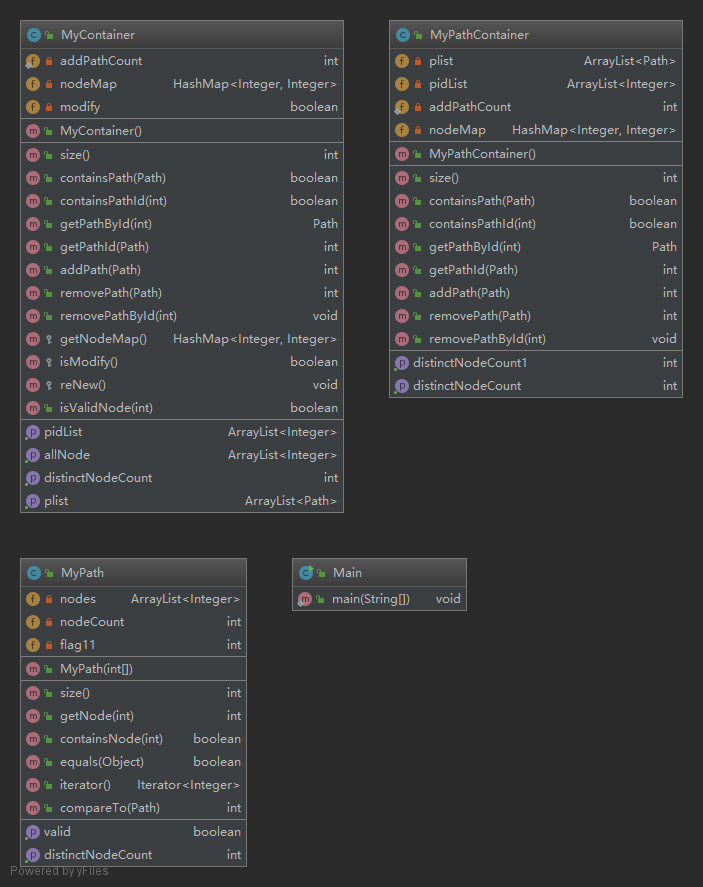
要求我们完成MyPath,继承Path接口,因为实现的过程非常简单,我主要使用了Arraylist对path和pathid进行存储因此就不过多赘述了。在第一次作业中,我也使用了缓存,对于查找类的指令,在第一次查找之后,可以把结果存储。
(2)第二次作业
第二次作业最关键的部分是shortest Path的实现。我的做法是采用Ffloyed进行图的构建,在每次有对图进行修改,如加入路径,删除路径时,重新进行图的构建。此做法复杂度是o(n3).但是之后我进行反思,觉得对于稀疏图来说,dijsktra更具有一定优势,对于单源最短路径,复杂度为o(eloge).
我的设计是让MyGraph直接继承MyPath类来实现Graph接口,然后再去实现containsNode, containsEdge, getShortesetPathLength......对于遍历得到的路径,我们用二维数组将它存储起来,下次查询时利用该结果。
而最短路径的查询,我将它放到了isConnected方法中,这样既能直接判断是否连通,也能构建好最短路径。
由于此次不太复杂,所需遍历次数根据指导书给的要求只需要250*250*20次遍历,显然不会超时。

(3)第三次作业
对于第三次作业的计算,我使用的dijsktra,我们可以观察到,无论是求最低票价,最少换乘,最高满意度,路径的计算,我们都可以用相同的方法,只是权值不同。因此我设计了一个calculator类,用于路径权值的计算(如下图)


我还设计了一个静态方法Algrithom类,专门用于dijsktra算法,每次调用时传入calculator和相关的一些变量,进行计算。这样,代码的利用率会变高。
第三次作业的大致框架还是基于前两次作业,甚至,大部分基础的东西都没有进行改动。这次作业的难点是判断换乘。我最初的想法有很大漏洞,导致强测直接只过了2个点,但现在回想,其实在不追求一定最小的情况下,性能其实是不错的,但可能会在一些换乘点判断错误。我最初的想法是,对于每一条遍历生成的path记录一个路径上第一个点的fromPath和最后一个点的toPath。比如对于对于遍历中找到的最优解temppath1:[1,2,3,4],其中1在path1上,4在path2上,我们对此记录下(1,2),当遇到新的符合的边时(假设这儿为[4,9,14])其中4在path4上,14在path3上。显而易见,这儿就需要经过换乘,因此加上换乘代价。我将这个方法交到第二次作业的测评机上去跑,并且使每次path的遍历都去判断换乘。在简单的情况下,性能差异不大,但在复杂的情况下,大概用时是上次的1.5倍左右。(非常可惜这个方法只能求得局部最优解),在设计使我也没能思考到在算(1,4)的路径时我就已经把frompath和topath的id固定了,可能下一条路径从另外一条路径经过3后,接下来的点是不需要换乘的,但在这儿就固定了1-3只能是走这条最短路径。
在看到强测爆炸之后,我又看到了拆点法,即每条路径上的点看做是不同的点。这样就相当于是一个单纯的dijsktra问题。在计算完成时,我们再通过遍历结果,对相同的点进行合并。我的重构即采用这种方法,我使用了HashMap对点的原始id和虚拟id进行对应。但是经过尝试,该算法速度太慢,比如在多个点重合的情况下,需要遍历的边数极具增加,但是,该方法的正确性是能够得到保证的。
我在评论区看到一个方法也觉得挺好--分层floyed(https://course.buaaoo.top/assignment/75/discussion/216)。还有一种能减小复杂度的方法就是,对于换乘建立的虚点,让他们只与同站虚点相连,不与实点相连,这样也能减少边的条数,对于dijsktra非常有利。
4.bug以及修复情况
在第一二次作业中均没有bug,第三次由于算法的问题导致只过了两个点。
错误原因为:利用了前面算出的局部最优解,而当时没考虑到这只是一个局部最优解(关于这部分,上文已经有比较详细的描述)
而在互测中,我发现常见的bug类型有:
- 超时。第三次作业尤其明显。
- null pointer,多出现remove之后
- 计算错误。这一般是算法出现的纰漏。
- 边界情况产生的错误。比如一个图里没有东西,但执行指令时并没有判断null的请况,导致出现错误。
5. 心得体会
这次作业一二次作业都很简单,非常易于设计,只要读懂jml,不出重大问题,几乎全部通过。
但对我们的设计模式进行了很大的考验。
首先,是算法,拥有一个正确、快速、稳定、可维护的算法至关重要。
其次,我们的整体架构,如类的确定,继承和重写,也对结果和设计难度有很大影响。
在整个作业中,jml实现了整体的架构,我们也可以尝试在以后的作业中,先去面向对象,把整体的类和架构实现,再去面向过程,细致的去考虑高效的实现算法。