一、训练加速
多GPU训练:
1.1 基于数据的并行
模型平均(Model Average)、同步随机梯度下降(SSGD)、异步随机梯度下降(ASGD)
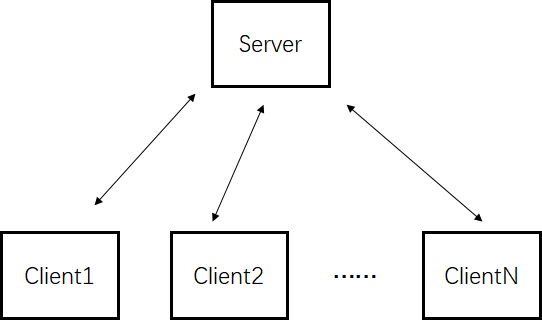
模型平均(Model Average)
每个Client训练平均的训练数据,每个batch更新一个模型,然后分别将模型发送给Server,Server将模型进行平均模型,然后发给各自的Client,然后再次进行训练,依此类推。
缺点:同步进行,每个Client的性能(采用不同的GPU)不一样,性能取决于性能最差的Client。
同步随机梯度下降(SSGD)
初始化模型W0,每个Client训练平均的训练数据,每个batch训练得到每个Client的梯度ΔW,然后分别将模型发送给Server,Server将梯度ΔW进行平均,然后通过初始参数、学习了和平均梯度得到迭代的参数W1,然后将新的迭代参数发给各自的Client,然后再次进行训练,依此类推。类似模型平均类似(模型平均计算参数在各自Client进行,而SSGD在Server端进行计算模型)
缺点:和模型平均类似,同步进行,每个Client的性能(采用不同的GPU)不一样,性能取决于性能最差的Client。
异步随机梯度下降(ASGD)
同SSGD,在Client端计算梯度,在Server端做梯度更新。不同于SSGD,ASGD是异步的。即每个Client计算梯度之后,直接通过Server中的参数计算迭代后的值。
基于模型的并行
将神经网络的模型进行分块,每个GPU只负责每块的模型训练。
二、推理加速
1.SVD分解
2.Hidden Node Prune
3.知识蒸馏(teacher student)
4.参数共享(LSTM的参数共享)
5.神经网络的量化
6.Binary Net
7.基于fft的循环矩阵加速
2.1 SVD分解
SVD可以做神经网络的加速,隐层节点的裁剪。