论文网址:https://arxiv.org/abs/1801.07698
一、介绍
基于深度卷积神经网络(Deep Convolutional Neural Networks, DCNNs)的大尺度的人脸识别的主要任务就是设计合适的损失函数以增强模型的判别能力。中心损失(Centre loss)惩罚了深度特征图和相对应的类别中心的欧拉距离来获得类间紧密型。球面距离(SphereFace)假定最后的全连接层的线性转换矩阵可以被当作在角度空间的类中心,以倍增的方式来惩罚深度特征图和相对应的权重之间的角度。
人脸识别的目的就是获得小的类内距离和大的类间距离的特征图。
训练深度卷积神经网络用于人脸识别的论文的两大主线是:
训练多类别的分类器区分数据集中的不同的特征。例如使用softmax分类器以及可以直接嵌入学习的分类器,例如triplet损失。基于大尺度的训练数据和复杂的DCNN结构,基于softmax损失和基于triplet损失的可以在人脸识别领域获得极好的性能。然而,这两种损失也都有一些缺点。
对于softmax损失:
1)线性转换矩阵$Win mathbb{R}^{d imes n}$的大小会随着特征数量$n$的增加而线性增长。
2)对于有类别标签的分类问题,学习到的特征图有很好的区分性,但是对于无类别表的分类问题,不太具有判别能力。
对于triplet损失:
1)随着人脸triplets数目的增长,尤其是对于大尺度的数据集,会有组合式爆炸,导致了迭代步数的巨大的增长;
2)对于有效的模型训练,半困难样本挖掘是一个很困难的问题。

图1 通过ArcFace损失训练用于人脸识别的DCNN过程
本文提出了一种ArcFace的方法来进一步提高人脸识别模型的判断能力以及稳定 训练过程。如图1所示, 在特征和权重标准化之后,DCNN特征和最后全连接层的点积等于余弦距离。使用反余弦函数计算特性和权重之间的角度。然后,我们在目标角度上增加一个附加角距离,通过余弦函数再一次得到目标逻辑。然后,我们通过固定的特性标准化重新缩放所有的逻辑,接下来的步骤和softmax损失完全一样。该ArcFace方法有如下优点:
1)ArcFace通过借助在标准化超球面上的角度和弧对应关系,直接优化了测地线距离边缘。通过分析特性和权重之间的角度统计,我们可以直观地看出在512维空间上发生了什么。
2)有效的。ArcFace在10张人脸识别基准上取得了最先进的性能,包括在大尺度图像和视频数据上。
3)简单的。如算法1所示,ArcFace只需要几行代码,极其简单去实现在基于计算图的深度框架上,例如:MxNet、Pytorch以及Tensorflow。而且,ArcFace不需要为了有稳定的性能而去和其他损失函数结合起来使用。并且可以很简单地覆盖任何训练数据集。
4)高效的。ArcFace在训练过程中只增加了微不足道的计算复杂度。现有的GPU可以轻松地支持数百万的特征用于训练,而且并行策略的模型可以轻松的支持更多的特性。
二、方法
2.1 ArcFace
最常用的分类损失函数softmax损失函数可以表示如下:
$ L_{1}=-frac{1}{N}sum_{i=1}^{N}logfrac{e^{W_{y_{i}}^{T}}x_{i}+b_{y_{j}}}{sum_{j=1}^{n}e^{W_{j}^{T}x_{i}+b}} $
其中,$x_{i}in mathbb{R}^{d}$表示第$i$个样本的深度特性,该特性属于第$y_{j}$个类别。本文的嵌入特性的维度$d$设置为512。$W_{j}in mathbb{R}^{d}$表示权重矩阵$Win mathbb{R}^{d imes n}$第$j$列,$b_{j}in mathbb{R}^{d}$是偏置项。批量大小和类别数目分别为$N$和$n$。传统的softmax损失被广泛深度人脸识别。然而softmax损失不能明确优化嵌入特性来加强类内样本更高的相似性和类间样本的差异性。导致了在大的类内的差异(例如:姿态差异和年龄差异)和大尺度测试场景下的深度人脸识别的鸿沟。
为了简单,我们固定设置偏移值$b_{j}$为0。然后我们转换逻辑为$W_{j}^{T}x_{i}=left | W_{j} ight |left | x_{j} ight |cos heta _{j}$,$ heta _{j}$为权重$W_{j}$和特征$x_{i}$之间的角度。通过L2正则化我们固定权重$left | W_{j} ight |$为1。我们同时将嵌入特征$left | x_{i} ight |$正则化并将其重缩放至$s$。特征和权重的正则化是的预测只依赖于它们之间的角度。因此学习到的嵌入特征分布在以$s$为半径的超球面上。
$ L_{2}=-frac{1}{N}sum_{i=1}^{N}logfrac{e^{scos heta y_{i}}}{e^{scos heta y_{i}}+sum_{j=1,j eq y_{j}}^{n}e^{scos heta _{j}}} $
因为嵌入特征分布在超球面的每个特征中心,我们增加一个角度边界常量$m$在$x_{i}$和$W_{y_{j}}$来增强类内紧密度和类间差异。因为角度边界等于在一个归一化的超球面的测地距离,因此我们将其命名为ArcFace。
$L_{3}=-frac{1}{N}sum_{i=1}^{N}logfrac{e^{s(cos( heta y_{i}+m))}}{e^{s(cos( heta y_{i}+m))+sum_{j=1,j eq y_{i}}^{n}e^{scos heta _{j}}}}$
我们从包含8个不同特征的足够样本(大约1500张图片或者类别)中选择图片来训练而且特性嵌入网络。分别使用softmax和ArcFace损失,如图3所示。sotfmax粗略地分散了嵌入特性,但是在决策边界上产生了模糊。而ArcFace损失可以在最近邻的类别上明显地强化更加明显地边界。
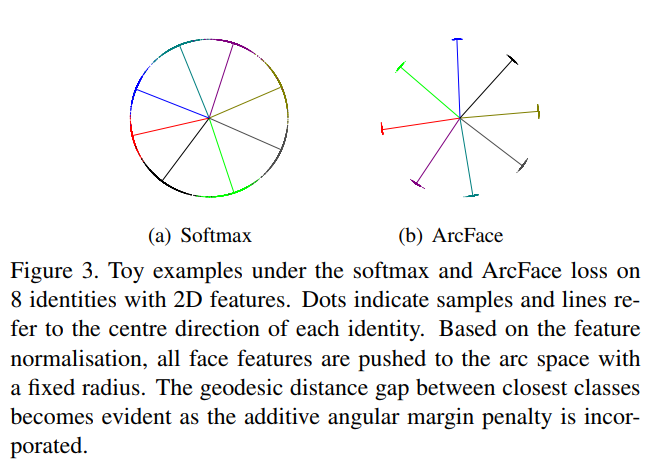
图2 softmax损失和arcface损失比较
由图1及arcface损失函数公式可以看出,其本质就是在预测正确的时候,增加角度的惩罚项,使得向量W和X之间的角度$ heta $变大成$ heta +m$,从而增加在损失函数中增加角度的贡献量,使得在损失优化过程中,角度收敛得更小(W和X的角度变小,减小了类内距离,增大了类间距离)。
如图3所示,W1和W2分别为两个类别对应两个中心线(也就是两个类),最后它们的类间距是比较大的。其中中心线W1和W2是一个可学习的参数。
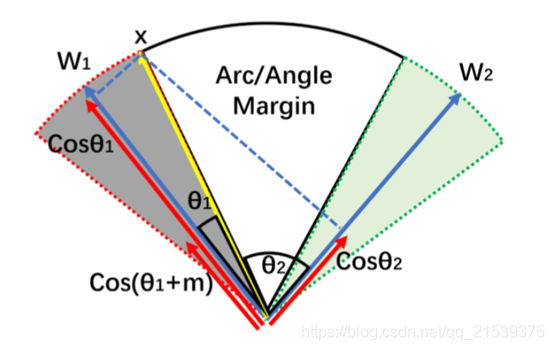
图3 arcface边界
ArcFace loss的代码实现:
其实,ArcFace损失公式是由softmax损失推导出来的,因此,首先,softmax的理解如下图:
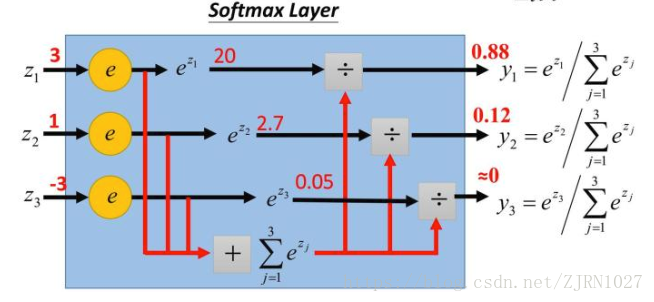
将输出的每一个类别使用softmax得到一个概率。其中:
$z_{j}$为w和x的乘积$W_{j}^{T}x_{i}$。
softmax损失可以如下方式得到:
1)计算每个类别的$W_{j}^{T}x_{i}$
2)使用自然数e求$z_{j}$的指数,得到每个类别的概率
3)计算交叉熵损失cross_entroy loss;
由上面的推导可以得出ArcFace损失,使用角度计算,即$W_{j}^{T}x_{i}=left | W_{j} ight |left | x_{i} ight |cos( heta )=s(cos( heta))$形式:
分到类别时为$s(cos( heta y_{i}+m))$;
没有分到类别时为$s(cos( heta y_{i}))$;
因此,ArcFace可以通过以下步骤计算得到:
1)首先需要先计算一个数组,数组中的每一项通过得到上面的计算;
如:如果有5个class,计算得到的类别时1,则该数组为$[s(cos( heta y_{1})), s(cos( heta y_{2}+m)), s(cos( heta y_{3})), s(cos( heta y_{4})), s(cos( heta y_{5}))]$
2)使用自然数e求指数,得到每个类别的概率;
3)计算交叉熵损失cross_entroy loss;
其中,2)、3)可以通过
tf.nn.sparse_softmax_cross_entropy函数计算得到。
因此,ArcFace代码如下:
def arcface_loss(inputs, labels, s, m): with tf.name_scope("arcface_loss"): weight = tf.get_variable("loss_wight", [inputs.get_shape().as_list()[-1], config.class_num], initializer=tf.contrib.layers.xavier_initializer(), regularizer=slim.l2_regularizer(config.model_params["weight_decay"])) inputs = tf.nn.l2_normalize(inputs, axis=1) weight = tf.nn.l2_normalize(weight, axis=0) sin_m = math.sin(m) cos_m = math.cos(m) mm = sin_m * m threshold = math.cos(math.pi - m) cos_theta = tf.matmul(inputs, weight,name="cos_theta") sin_theta = tf.sqrt(tf.subtract(1., tf.square(cos_theta))) cos_theta_m = s * tf.subtract(tf.multiply(cos_theta, cos_m), tf.multiply(sin_theta, sin_m)) keep_val = s * (cos_theta - mm) cond_v = cos_theta - threshold cond = tf.cast(tf.nn.relu(cond_v), dtype=tf.bool) cos_theta_m_keep = tf.where(cond, cos_theta_m, keep_val) # 计算分类类别的one hot标记数组。如:类别为1,总的有5个class,则得出[0, 1, 0, 0, 0] mask = tf.one_hot(labels, config.class_num) # 计算没有分类类别的one hot标记数组。如:类别为1,总的有5个class,则得出[1, 0, 1, 1, 1] inv_mask = tf.subtract(1., mask) # 计算分类的数组。如:类别为1,总的有5个class,则得出[cos(theta1), cos(theta2+m), cos(theta3), cos(theta4), cos(theta5)] # arcface_loss函数只输出上面的数组,实际最终的损失,还需要使用tf.nn.sparse_softmax_cross_entropy计算得到 output = tf.add(tf.multiply(mask, cos_theta_m_keep), tf.multiply(inv_mask, s * cos_theta), name="arcface_loss") return output