1 hystrix是什么
在分布式系统中,每个服务都可能会调用很多其他服务,被调用的那些服务就是依赖服务,有的时候某些依赖服务出现故障也是很正常的。
Hystrix 可以让我们在分布式系统中对服务间的调用进行控制,加入一些调用延迟或者依赖故障的容错机制。
Hystrix 通过将依赖服务进行资源隔离,进而阻止某个依赖服务出现故障时在整个系统所有的依赖服务调用中进行蔓延;同时Hystrix 还提供故障时的 fallback 降级机制。
总而言之,Hystrix 通过这些方法帮助我们提升分布式系统的可用性和稳定性。
2 hystrix可以干什么
阻止任何一个依赖服务耗尽所有的资源,比如 tomcat 中的所有线程资源。
避免请求排队和积压,采用限流和 fail fast 来控制故障。
提供 fallback 降级机制来应对故障。
使用资源隔离技术,比如 bulkhead(舱壁隔离技术)、swimlane(泳道技术)、circuit breaker(断路技术)来限制任何一个依赖服务的故障的影响。
通过近实时的统计/监控/报警功能,来提高故障发现的速度。
通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度。
保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况
3 怎么使用hystrix
3.1、构建一个HystrixCommand或者HystrixObservableCommand
一个HystrixCommand或一个HystrixObservableCommand对象,代表了对某个依赖服务发起的一次请求或者调用
构造的时候,可以在构造函数中传入任何需要的参数
HystrixCommand主要用于仅仅会返回一个结果的调用
HystrixObservableCommand主要用于可能会返回多条结果的调用
HystrixCommand command = new HystrixCommand(arg1, arg2);
HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
3.2、调用command的执行方法
执行Command就可以发起一次对依赖服务的调用
要执行Command,需要在4个方法中选择其中的一个:execute(),queue(),observe(),toObservable()
其中execute()和queue()仅仅对HystrixCommand适用
execute():调用后直接block住,属于同步调用,直到依赖服务返回单条结果,或者抛出异常
queue():返回一个Future,属于异步调用,后面可以通过Future获取单条结果
observe():订阅一个Observable对象,Observable代表的是依赖服务返回的结果,获取到一个那个代表结果的Observable对象的拷贝对象
toObservable():返回一个Observable对象,如果我们订阅这个对象,就会执行command并且获取返回结果
K value = command.execute();
Future<K> fValue = command.queue();
Observable<K> ohValue = command.observe();
Observable<K> ocValue = command.toObservable();
execute()实际上会调用queue().get().queue(),接着会调用toObservable().toBlocking().toFuture()
也就是说,无论是哪种执行command的方式,最终都是依赖toObservable()去执行的
3.3、检查是否开启缓存
从这一步开始,进入我们的底层的运行原理啦,了解hysrix的一些更加高级的功能和特性
如果这个command开启了请求缓存,request cache,而且这个调用的结果在缓存中存在,那么直接从缓存中返回结果
3.4、检查是否开启了短路器
检查这个command对应的依赖服务是否开启了短路器
如果断路器被打开了,那么hystrix就不会执行这个command,而是直接去执行fallback降级机制
3.5、检查线程池/队列/semaphore是否已经满了
如果command对应的线程池/队列/semaphore已经满了,那么也不会执行command,而是直接去调用fallback降级机制
3.6、执行command
调用HystrixObservableCommand.construct()或HystrixCommand.run()来实际执行这个command
HystrixCommand.run()是返回一个单条结果,或者抛出一个异常
HystrixObservableCommand.construct()是返回一个Observable对象,可以获取多条结果
如果HystrixCommand.run()或HystrixObservableCommand.construct()的执行,超过了timeout时长的话,那么command所在的线程就会抛出一个TimeoutException
如果timeout了,也会去执行fallback降级机制,而且就不会管run()或construct()返回的值了
这里要注意的一点是,我们是不可能终止掉一个调用严重延迟的依赖服务的线程的,只能说给你抛出来一个TimeoutException,但是还是可能会因为严重延迟的调用线程占满整个线程池的
即使这个时候新来的流量都被限流了。。。
如果没有timeout的话,那么就会拿到一些调用依赖服务获取到的结果,然后hystrix会做一些logging记录和metric统计
3.7、短路健康检查
Hystrix会将每一个依赖服务的调用成功,失败,拒绝,超时,等事件,都会发送给circuit breaker断路器
短路器就会对调用成功/失败/拒绝/超时等事件的次数进行统计
短路器会根据这些统计次数来决定,是否要进行短路,如果打开了短路器,那么在一段时间内就会直接短路,然后如果在之后第一次检查发现调用成功了,就关闭断路器
3.8、调用fallback降级机制
在以下几种情况中,hystrix会调用fallback降级机制:run()或construct()抛出一个异常,短路器打开,线程池/队列/semaphore满了,command执行超时了
一般在降级机制中,都建议给出一些默认的返回值,比如静态的一些代码逻辑,或者从内存中的缓存中提取一些数据,尽量在这里不要再进行网络请求了
即使在降级中,一定要进行网络调用,也应该将那个调用放在一个HystrixCommand中,进行隔离
在HystrixCommand中,上线getFallback()方法,可以提供降级机制
在HystirxObservableCommand中,实现一个resumeWithFallback()方法,返回一个Observable对象,可以提供降级结果
如果fallback返回了结果,那么hystrix就会返回这个结果
对于HystrixCommand,会返回一个Observable对象,其中会发返回对应的结果
对于HystrixObservableCommand,会返回一个原始的Observable对象
如果没有实现fallback,或者是fallback抛出了异常,Hystrix会返回一个Observable,但是不会返回任何数据
不同的command执行方式,其fallback为空或者异常时的返回结果不同
对于execute(),直接抛出异常
对于queue(),返回一个Future,调用get()时抛出异常
对于observe(),返回一个Observable对象,但是调用subscribe()方法订阅它时,理解抛出调用者的onError方法
对于toObservable(),返回一个Observable对象,但是调用subscribe()方法订阅它时,理解抛出调用者的onError方法
3.9、不同的执行方式
execute(),获取一个Future.get(),然后拿到单个结果
queue(),返回一个Future
observer(),立即订阅Observable,然后启动8大执行步骤,返回一个拷贝的Observable,订阅时理解回调给你结果
toObservable(),返回一个原始的Observable,必须手动订阅才会去执行8大步骤
4 总结:
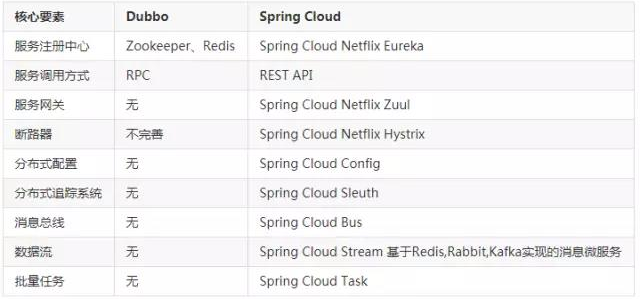
由上图对微服务技术进行了分析,可以知道dubbo服务并不是很好的做到这个,在很早的时候电商开发的时候就是采用这个进行解决的,对服务进行控制.但是相对于springcloud中使用起来更简单,