均一性:一个簇只包含了一个类别的样本,则满足均一性
完整性:同类别的样本被归类到相同的簇中,则满足完整性
若使得聚类的簇一直减小,直到剩下一个簇,那么这个聚类的完整性是最好的,但是,均一性是最差的。
同理,若n个样本被分为了n个簇,那么这个聚类的均一性一定是最好的,但是完整性确是最差的.
这两个是相互影响的.若想均衡一下两个,那么就需要均一性和完整性的加权平均.
ARI:adjusted_rand_index
数据集S共有N个元素,两个聚类结果分别是
其实就是看,取出一个样本,看这个样本在X中属于哪个类别,再看这个样本在Y中属于哪个类别,计算相同的概率。也就是说如果X,Y聚类结果相同的话,那么这个样本在X,Y中属于的类别一定是相同的。
参考一个矩阵:
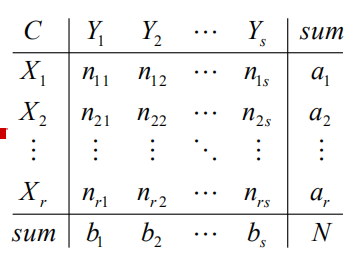
解释一下这个矩阵,第一行就是既是类别X1,又是Y1,Y2,YS的样本的数量,总共是a1,第一纵列就是既是类别Y1,又是X1,X2,XR的样本的数量,总共是b1,样本总数是N.
AMI:adjusted_mutual_info
同样的矩阵,我们将X,Y看成随机变量,然后我们计算随机变量之间的互信息,用这个互信息作为度量标准
正则化互信息:用互信息除以各自的熵的乘积的开方
ARI和AMI都必须提前知道原始的样本属于哪个标记.
轮廓系数:
计算样本i到同簇其他样本的平均距离ai.
ai越小,说明样本i越应该被聚类到该簇,将ai称为样本i的簇内不相似度.
簇C中所有样本的ai均值称为簇C的簇不相似度.
计算样本i到其他某簇Cj的所有样本的平均距离bij,称为样本i与簇Cj的不相似度。定义为样本i的簇间不相似度
bi越大,说明样本i越不属于其他簇.
