【西天取经】(入门)windows10 安装spark3.0, .net core 创建 spark 程序
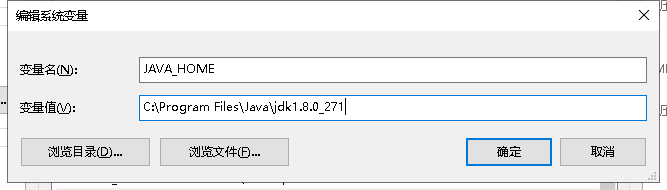
1、安装java8,配置环境变量
JDK:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
java -version

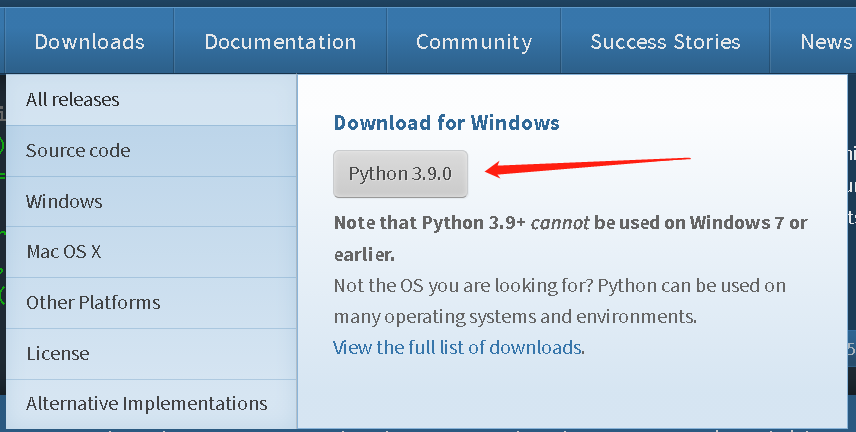
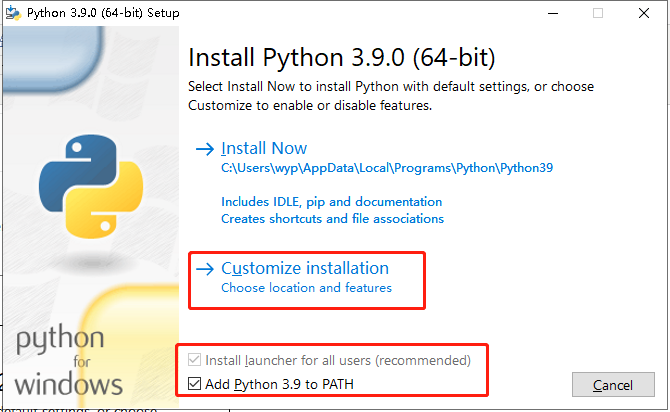
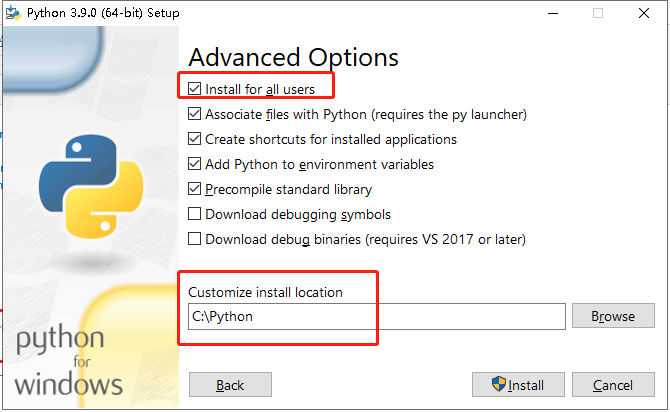
2、安装python,配置环境变量
3、安装Spark
下载: https://spark.apache.org/downloads.html
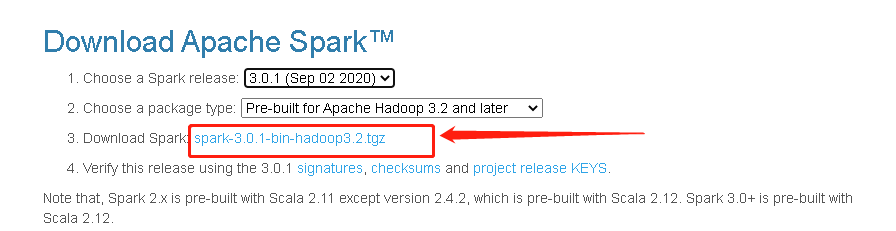
解压缩这个spark-3.0.1-bin-hadoop3.2.tgz文件到D:spark目录中

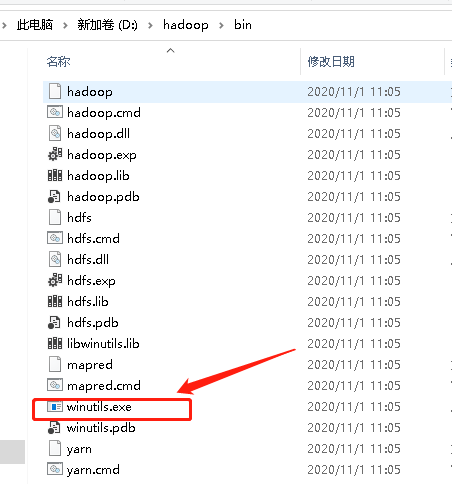
添加Hadoop,windows使用 winutils.exe 这个文件
克隆: https://github.com/steveloughran/winutils 代码仓库到本地,
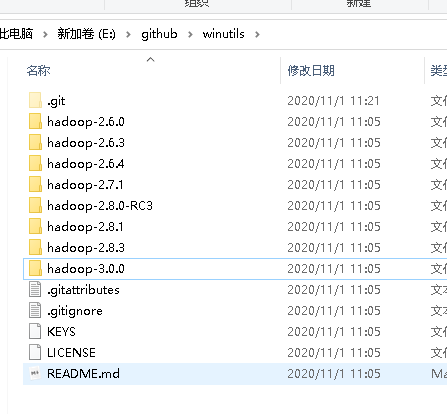
复制hadoop-3.0.0里面的bin目录到D:hadoop目录
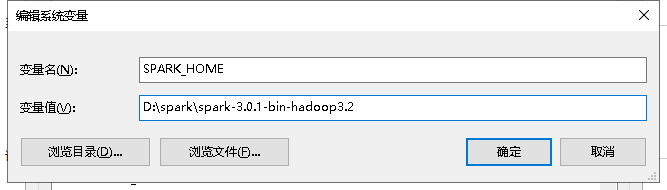
4、配置环境变量
- 配置Spark环境变量:
- 配置Hadoop环境变量:

- PATH变量增加Java,Spark,Hadoop环境变量


- 设置Spark本地主机名的环境变量:SPARK_LOCAL_HOSTNAME = localhost

查看Spark是否安装成功(参考微软官方的URL)
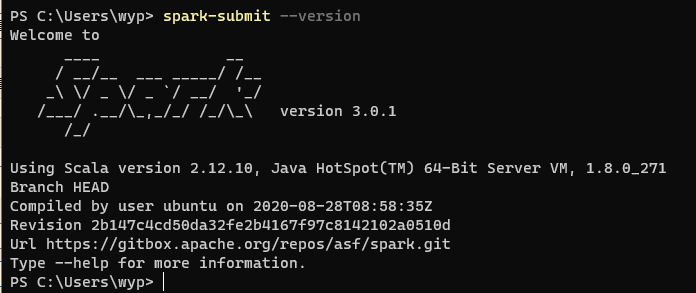
spark-submit --version
5、 运行Spark
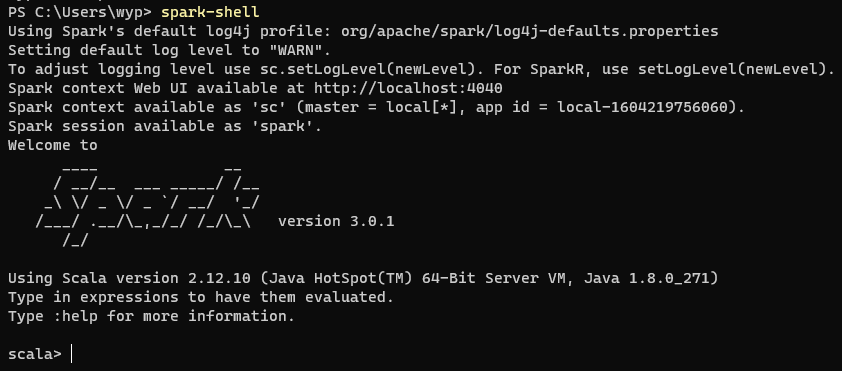
spark-shell
创建word.txt文件:
写入文件内容:
Hello Scala
Hello Spark
Hello Scala
执行命令:
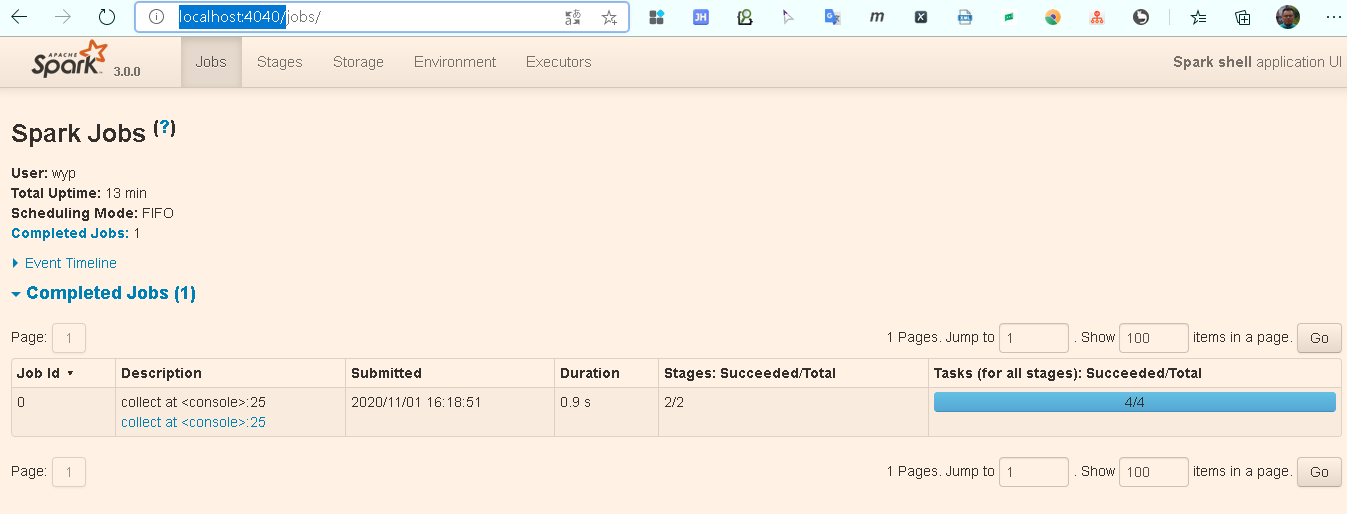
scala> sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

浏览器:http://localhost:4040/
至此:Spark本地windows的环境就配好了。
接下来就该net core程序闪亮登场了。
Install .NET for Apache Spark(参考微软官方的URL)
下载:https://github.com/dotnet/spark/releases/tag/v1.0.0
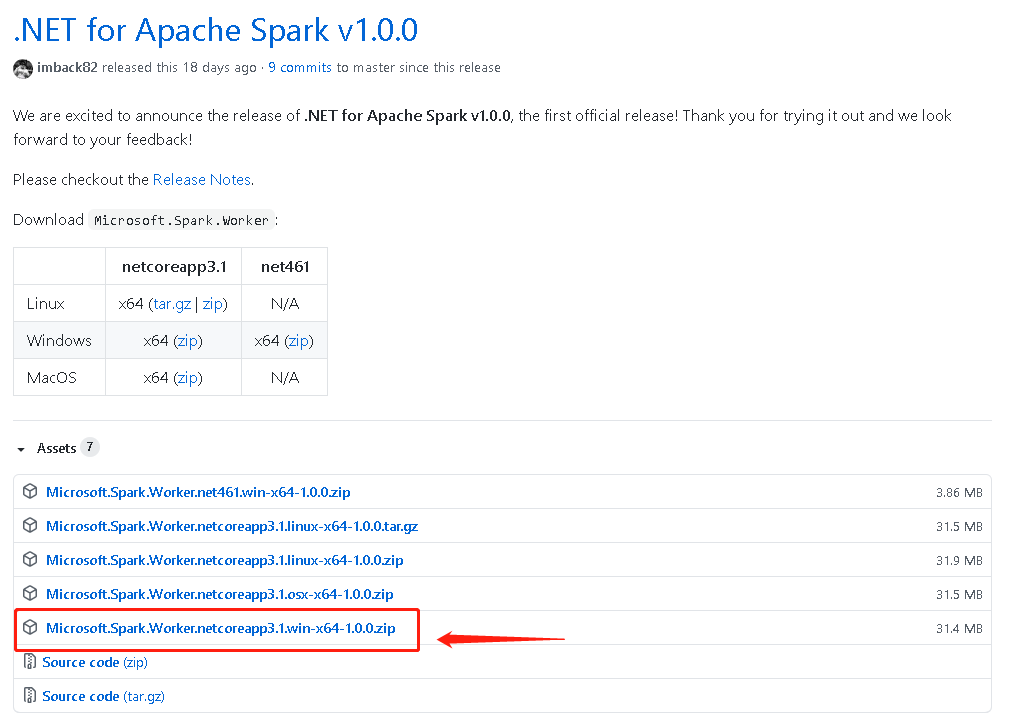
解压Microsoft.Spark.Worker.netcoreapp3.1.win-x64-1.0.0.zip到D:spark目录里,设置环境变量
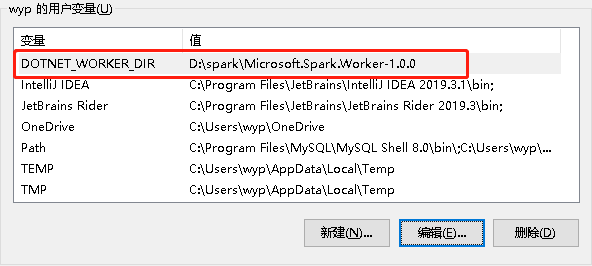
Visual Studio 2019创建“HelloSpark” Console的项目

HelloSpark.csproj文件内容:
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="1.0.0" /> </ItemGroup> <ItemGroup> <None Update="input.txt"> <CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory> </None> <None Update="people.json"> <CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory> </None> </ItemGroup> </Project>
people.json文件内容:
{"name": "Michael" }
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
input.txt文件内容:
Hello World This .NET app uses .NET for Apache Spark This .NET app counts words with Apache Spark
Program.cs:
using Microsoft.Spark.Sql; namespace HelloSpark { class Program { static void Main(string[] args) { var spark = SparkSession.Builder().AppName("word_count_sample").GetOrCreate(); DataFrame peopleFrame = spark.Read().Json("people.json"); peopleFrame.Show(); DataFrame dataFrame = spark.Read().Text("input.txt"); DataFrame words = dataFrame .Select(Functions.Split(Functions.Col("value"), " ").Alias("words")) .Select(Functions.Explode(Functions.Col("words")) .Alias("word")) .GroupBy("word") .Count() .OrderBy(Functions.Col("count").Desc()); words.Show(); spark.Stop(); } } }
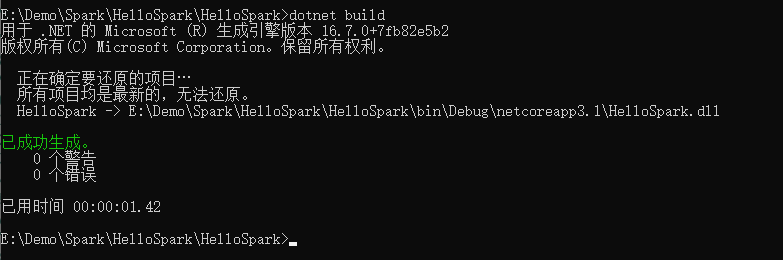
编译:
dotnet build
运行net core的Spark程序的代码有点复杂:
%SPARK_HOME%inspark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner --master local binDebug
etcoreapp3.1microsoft-spark-3-0_2.12-1.0.0.jar dotnet binDebug
etcoreapp3.1HelloSpark.dll


运行结果:


Spark框架不仅有JVM系的位置,就在18天前也有了.net的一席之地!
以上内容仅作为.net for spark入门程序,由于本人刚接触Spark,水平有限只能给大家做到搭环境写个demo这一步了,希望.net for spark 在不远的将来能够给.net技术栈贡献更多的大数据项目。