由于公司业务需要,需要实时同步pgsql数据,我们选择使用flink-cdc方式进行
架构图:
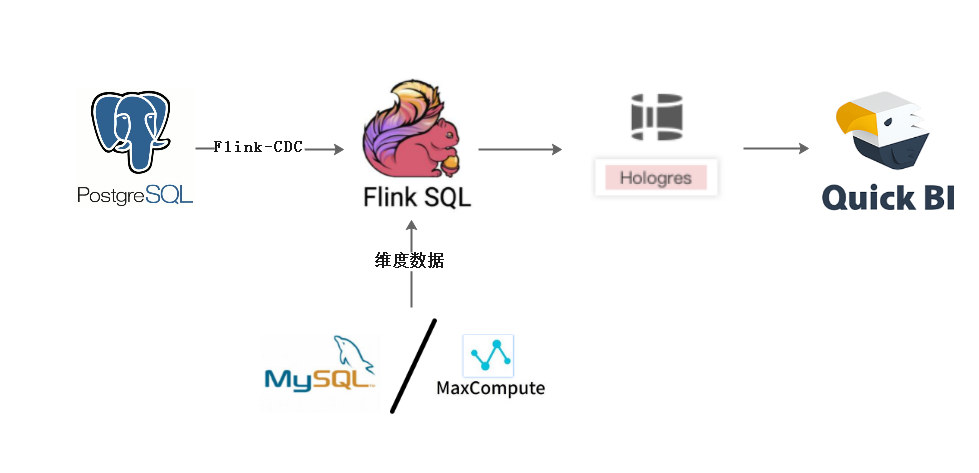
前提步骤:
1,更改配置文件postgresql.conf
# 更改wal日志方式为logical
wal_level = logical # minimal, replica, or logical
# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots
max_replication_slots = 20 # max number of replication slots
# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders = 20 # max number of walsender processes
# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s)
wal_sender_timeout = 180s # in milliseconds; 0 disable
wal_level是必须更改的,其它参数选着性更改,如果同步表数量超过10张建议修改为合适的值
更改配置文件postgresql.conf完成,需要重启pg服务生效,所以一般是在业务低峰期更改
2,新建用户并且给用户复制流权限
-- pg新建用户
CREATE USER user WITH PASSWORD 'pwd';
-- 给用户复制流权限
ALTER ROLE user replication;
-- 给用户登录数据库权限
grant CONNECT ON DATABASE test to user;
-- 把当前库public下所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO user;
3,发布表
-- 设置发布为true update pg_publication set puballtables=true where pubname is not null; -- 把所有表进行发布 CREATE PUBLICATION dbz_publication FOR ALL TABLES; -- 查询哪些表已经发布 select * from pg_publication_tables;
4,更改表的复制标识包含更新和删除的值
-- 更改复制标识包含更新和删除之前值
ALTER TABLE test0425 REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功)
select relreplident from pg_class where relname='test0425';
OK,到这一步,设置已经完全可以啦,上面步骤都是必须的
常用的pgsql命令(备忘)
-- pg新建用户 CREATE USER ODPS_ETL WITH PASSWORD 'odpsETL@2021'; -- 给用户复制流权限 ALTER ROLE ODPS_ETL replication; -- 给用户数据库权限 grant CONNECT ON DATABASE test to ODPS_ETL; -- 设置发布开关 update pg_publication set puballtables=true where pubname is not null; -- 把所有表进行发布 CREATE PUBLICATION dbz_publication FOR ALL TABLES; -- 查询哪些表已经发布 select * from pg_publication_tables; -- 给表查询权限 grant select on TABLE aa to ODPS_ETL; -- 给用户读写权限 grant select,insert,update,delete ON ALL TABLES IN SCHEMA public to bd_test; -- 把当前库所有表查询权限赋给用户 GRANT SELECT ON ALL TABLES IN SCHEMA public TO ODPS_ETL; -- 把当前库以后新建的表查询权限赋给用户 alter default privileges in schema public grant select on tables to ODPS_ETL; -- 更改复制标识包含更新和删除之前值 ALTER TABLE test0425 REPLICA IDENTITY FULL; -- 查看复制标识 select relreplident from pg_class where relname='test0425'; -- 查看solt使用情况 SELECT * FROM pg_replication_slots; -- 删除solt SELECT pg_drop_replication_slot('zd_org_goods_solt'); -- 查询用户当前连接数 select usename, count(*) from pg_stat_activity group by usename order by count(*) desc; -- 设置用户最大连接数 alter role odps_etl connection limit 200;
5,下面开始上代码:,
maven依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.11</artifactId> <version>1.13.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>1.13.0</version> </dependency> <dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>flink-connector-postgres-cdc</artifactId> <version>1.1.0</version> </dependency>
java代码
package flinkTest.connect; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.TableResult; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; public class PgsqlToMysqlTest { public static void main(String[] args) { //设置flink表环境变量 EnvironmentSettings fsSettings = EnvironmentSettings.newInstance() .useBlinkPlanner() .inStreamingMode() .build(); //获取flink流环境变量 StreamExecutionEnvironment exeEnv = StreamExecutionEnvironment.getExecutionEnvironment(); exeEnv.setParallelism(1); //表执行环境 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(exeEnv, fsSettings); //拼接souceDLL String sourceDDL = "CREATE TABLE pgsql_source ( " + " id int, " + " name STRING, " + " py_code STRING, " + " seq_no int, " + " description STRING " + ") WITH ( " + " 'connector' = 'postgres-cdc', " + " 'hostname' = '***', " + " 'port' = '5432', " + " 'username' = 'bd_test', " + " 'password' = '***', " + " 'database-name' = 'bd_test', " + " 'schema-name' = 'public', " + " 'debezium.snapshot.mode' = 'never', " + " 'decoding.plugin.name' = 'pgoutput', " + " 'debezium.slot.name' = 'test', " + " 'table-name' = 'test' " + ")"; String sinkDDL = "CREATE TABLE mysql_sink ( " + " id int, " + " name STRING, " + " py_code STRING, " + " seq_no int, " + " description STRING, " + " PRIMARY KEY (id) NOT ENFORCED " + ") WITH ( " + " 'connector' = 'jdbc', " + " 'url' = 'jdbc:mysql://ip:3306/test_db?rewriteBatchedStatements=true&useUnicode=true&characterEncoding=UTF-8', " + " 'username' = 'bd_test', " + " 'password' = '***', " + " 'table-name' = 'test' " + ")"; String transformSQL = "INSERT INTO mysql_sink " + "SELECT id,name,py_code,seq_no,description " + "FROM pgsql_source"; //执行source表ddl tableEnv.executeSql(sourceDDL); //执行sink表ddl tableEnv.executeSql(sinkDDL); //执行逻辑sql语句 TableResult tableResult = tableEnv.executeSql(transformSQL); //控制塔输出 // tableResult.print(); } }
表机构奉上:
-- pgsql表结构 CREATE TABLE "public"."test" ( "id" int4 NOT NULL, "name" varchar(50) COLLATE "pg_catalog"."default" NOT NULL, "py_code" varchar(50) COLLATE "pg_catalog"."default", "seq_no" int4 NOT NULL, "description" varchar(200) COLLATE "pg_catalog"."default", CONSTRAINT "pk_zd_business_type" PRIMARY KEY ("id") ) ; -- mysql表结构 CREATE TABLE `test` ( `id` int(11) NOT NULL DEFAULT '0' COMMENT 'ID', `name` varchar(50) DEFAULT NULL COMMENT '名称', `py_code` varchar(50) DEFAULT NULL COMMENT '助记码', `seq_no` int(11) DEFAULT NULL COMMENT '排序', `description` varchar(200) DEFAULT NULL COMMENT '备注', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
6,下面就可以进行操作原表,然后增删改操作
WITH参数
| 参数 | 说明 | 是否必填 | 数据类型 | 备注 |
|---|---|---|---|---|
| connector | 源表类型 | 是 | STRING | 固定值为postgres-cdc。 |
| hostname | Postgres数据库的IP地址或者Hostname。 | 是 | STRING | 无 |
| username | Postgres数据库服务的用户名。 | 是 | STRING | 无 |
| password | Postgres数据库服务的密码 | 是 | STRING | 无 |
| database-name | 数据库名称 | 是 | STRING | 数据库名称支持正则表达式以读取多个数据库的数据。 |
| schema-name | Postgres Schema名称 | 是 | STRING | Schema名称支持正则表达式以读取多个Schema的数据。 |
| table-name | Postgres表名 | 是 | STRING | 表名支持正则表达式去读取多个表的数据。 |
| port | Postgres数据库服务的端口号 | 否 | INTEGER | 默认值为5432。 |
| decoding.plugin.name | Postgres Logical Decoding插件名称 | 否 | STRING | 根据Postgres服务上安装的插件确定。支持的插件列表如下:
说明 如果您使用的是阿里云RDS PostgreSQL,你需要开启逻辑解码(wal2json)功能,详情请参见逻辑解码(wal2json)。
|
| debezium.* | Debezium属性参数 | 否 | STRING | 更细粒度控制Debezium客户端的行为。例如'debezium.snapshot.mode' = 'never',详情请参见配置属性。
说明 建议每个表都设置
debezium.slot.name参数,以避免出现PSQLException: ERROR: replication slot "debezium" is active for PID 974报错。 |
类型映射
