目录
1. 冒泡排序(最好是O(n), 最坏O(n2))
原理:拿自己与上面一个比较,如果上面一个比自己小就将自己和上面一个调换位置,依次再与上面一个比较,第一轮结束后最上面那个一定是最大的数


1 def bubble_sort(li): 2 for i in range(len(li)-1): 3 for j in range(len(li)-i-1): 4 if li[j] > li[j+1]: 5 li[j],li[j+1]=li[j+1],li[j] 6 7 li = [1,5,2,6,3,7,4,8,9,0] 8 bubble_sort(li) 9 print(li) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
2. 选择排序
原理:
1、先假定第一个是最小的,依次与其他数比,如果其他数中有比第一个数小就假定这个更小的最小
2、再比,第一轮就可以找到最小的那个放到0号位置,然后在假定1号位置数最小与剩下比较,再找到第二小的数放到第1号位置
import random def select_sort(li): for i in range(len(li) - 1): min_loc = i #开始先假设0号位置的值最小 for j in range(i+1, len(li)): #循环无序区,依次比较,小于min_loc就暂定他的下标最小 if li[j] < li[min_loc]: #所以内层for循环每执行一次就选出一个小值 min_loc = j li[i], li[min_loc] = li[min_loc],li[i] li = [1,5,2,6,3,7,4,8,9,0] select_sort(li) print(li) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
3. 插入排序
原理:
1、列表被分为有序区和无序区两个部分,最初有序区只有一个元素
2、每次从无序区选择一个元素,插入到有序区的位置,直到无序区变空
import random def insert_sort(li): for i in range(1, len(li)): tmp = li[i] #tmp是无序区取出的一个数 j = i - 1 #li[j]是有序区最大的那个数 while j >= 0 and li[j] > tmp: # li[j]是有序区最大的数,tmp是无序区取出的一个数,tmp从有序区最大的那个数开始比 # 小就调换位置,直到找到有序区中值不大于tmp的结束 li[j+1]=li[j] #将有序区最右边的数向右移一个位置 j = j - 1 li[j + 1] = tmp #将tmp放到以前有序区最大数的位置,再依次与前一个数比较 data = list(range(100)) random.shuffle(data) #将有序列表打乱 insert_sort(data) print(data)
4. 快排 快速排序中最简单的(递归调用)
注:倒序,和 列表中有大量重复元素时,时间复杂度很大,, 快排代码实现(类似于二叉树 递归调用)----右手左手一个慢动作,右手左手一个慢动作重播
def quick(list): if len(list) < 2: return list tmp = list[0] # 临时变量 可以取随机值 left = [x for x in list[1:] if x <= tmp] # 左列表 right = [x for x in list[1:] if x > tmp] # 右列表 return quick(left) + [tmp] + quick(right) li = [4,3,7,5,8,2] print quick(li) # [2, 3, 4, 5, 7, 8] #### 对[4,3,7,5,8,2]排序 ''' [3, 2] + [4] + [7, 5, 8] # tmp = [4] [2] + [3] + [4] + [7, 5, 8] # tmp = [3] 此时对[3, 2]这个列表进行排序 [2] + [3] + [4] + [5] + [7] + [8] # tmp = [7] 此时对[7, 5, 8]这个列表进行排序 '''
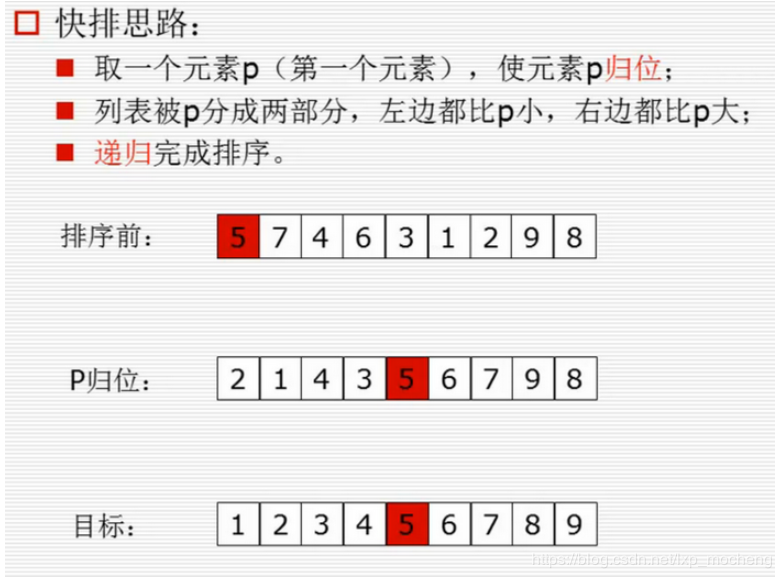
思路原理:
从排序前--------> 到P归位 经历过程(前面都比5小后面都比5大)
1、 首先从右向左比较,取出列表第一个元素5(第一个位置就空出来)与列表最后一个元素8比较,8>5不换位置
2、 用5与-2位置的9比,5<9不换位置
3、 5与-3位置的2比较,2<5,将-3位置的5放到1号位置,那么-3号位置空出来了,然后从左往右比较
4、 5与2号位置的7比,5<7,将7放到-3号位置,2号位置空出来了,在从右往左比
5、 -4号位置的1小于5将1放到空出的2号位置,-4位置空出来了,再从右向左比
6、 这样第一次循环就实现了5放到列表中间,前面的都比5大,后面的都比5小
快排与冒泡时间复杂度对比
|
最好情况 |
一般情况 |
最坏情况 |
|
|
快排 |
O(nlogn) |
O(nlogn) |
O(n^2) |
|
冒泡 |
O(n) |
O(n^2) |
O(n^2) |
快排最坏时间复杂度为何为O(n2)
1. 每次划分只能将序列分为一个元素与其他元素两部分,这时的快速排序退化为冒泡排序
2. 如果用数画出来,得到的将会是一棵单斜树,也就是说所有所有的节点只有左(右)节点的树;平均时间复杂度O(n*logn)
5. 堆排
def sift(data, low, high): ''' 构造堆 堆定义:堆中某节点的值总是不大于或不小于父节点的值 :param data: 传入的待排序的列表 :param low: 需要进行排序的那个小堆的根对应的号 :param high: 需要进行排序那个小堆最大的那个号 :return: ''' i = low #i最开始创建堆时是最后一个有孩子的父亲对应根的号 j = 2 * i+ 1 #j子堆左孩子对应的号 tmp = data[i] #tmp是子堆中原本根的值(拿出最高领导) while j <= high: #只要没到子堆的最后(每次向下找一层) #孩子在堆里 # if j < high and data[j] < data[j + 1]: if j + 1 <= high and data[j] < data[j + 1]: #如果有右孩纸,且比左孩子大 j += 1 if tmp < data[j]: #如果孩子还比子堆原有根的值tmp大,就将孩子放到子堆的根 data[i] = data[j] #孩子成为子堆的根 i = j #孩子成为新父亲(向下再找一层) j = 2 * i + 1 #新孩子 (此时如果j<=high证明还有孩,继续找) else: break #如果能干就跳出循环就会流出一个空位 data[i] = tmp #最高领导放到父亲位置 def heap_sort(data): '''调整堆''' n = len(data) # n//2-1 就是最后一个有孩子的父亲那个子堆根的位置 for i in range(n // 2 - 1, -1, -1): #开始位置,结束位置, 步长 这个for循环构建堆 # for循环输出的是: (n // 2 - 1 ) ~ 0 之间的数 sift(data, i , n-1) # i是子堆的根,n-1是堆中最后一个元素 data = [20,50,20,60,70,10,80,30,40] heap_sort(data) print data # [80, 70, 20, 60, 50, 10, 20, 30, 40]
6. 归排(递归调用)
原理图:
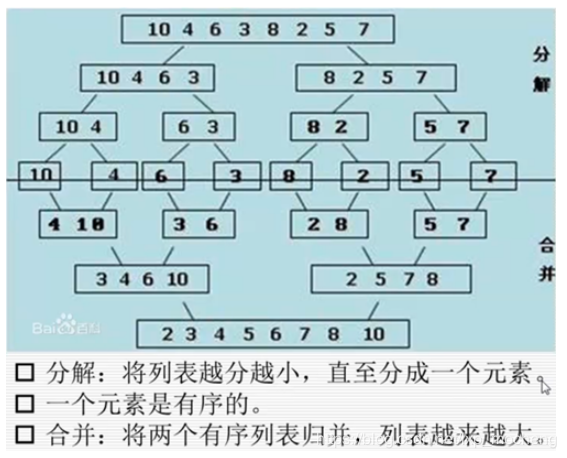
#! /usr/bin/env python # -*- coding: utf-8 -*- def merge(li, low, mid, high): ''' :param li: 带排序列表 :param low: 列表中第一个元素下标,一般是:0 :param mid: 列表中间位置下标 :param high: 列表最后位置下标 :return: ''' i = low j = mid + 1 ltmp = [] while i <= mid and j <= high: if li[i] < li[j]: ltmp.append(li[i]) i += 1 else: ltmp.append(li[j]) j += 1 while i <= mid: ltmp.append(li[i]) i += 1 while j <= high: ltmp.append(li[j]) j += 1 li[low:high+1] = ltmp def mergesort(li, low, high): if low < high: mid = (low + high) // 2 #获取列表中间的索引下标 mergesort(li, low, mid) #先分解 mergesort(li, mid+1, high) merge(li, low, mid, high) #然后合并 data = [10,4,6,3,8,2,5,7] mergesort(data, 0 , len(data) -1) print(data) # [2, 4, 6, 8, 10, 12, 14, 16, 18] 归并排序
快速排序,堆排序, 归并排序 比较
1、三种排序算法时间复杂度都是( O(nlogn) )
2、 一般情况下,就运行时间而言:
快速排序 < 归并排序 < 堆排序
3、三种排序算法的缺点
1、快速排序: 极端情况下排序效率低( O(n2) )
2、归并排序: 需要额外内存开销(需要新建一个列表放排序的元素)
3、堆排序: 在快的排序算法中相对较慢,堆排序最稳定