消息可靠性
保证数据并发安全性,保证数据最终一致性的方式:
1、分布式锁
优点:强一致性
缺点:不适合高并发
2、消息队列
优点:异步、高并发
缺点:有延时、弱一致性,必须能确保该业务操作肯定能够成功完成,不可能失败。
生产者发消息给MQ,MQ持久化成功后返回ACK,
MQ把消息给消费者,消费者消费成功后返回ACK。
MQ做高可用,MQ限流
我们可以从以下几方面来保证消息的可靠性:
1、客户端代码中的异常捕获,包括生产者和消费者
2、AMQP/RabbitMQ的事务机制
3、发送确认机制
4、消息持久化机制
5、Broker高可用机制(镜像队列)
6、消费者确认机制
7、消费端限流
8、消息幂等性
异常捕获机制
先处理业务逻辑,业务逻辑处理完,在try-catch块里处理发送消息,如果有发送异常,重试或者延迟发送,或者回滚。
boolean result = doBiz();
if(result){
try{
sendMsg();
}catch(Exception e){
//retrySend()
//delaySend()
rollbackBiz();
}
}
另外,也可以通过spring.
AMQP/RabbitMQ事务机制
解决的问题:没有捕获到异常,并不能代表消息一定投递成功
事务提交机制,事务提交成功后都没有异常,就说明投递成功来。但是,这种方式在性能方面开销比较大,一般也不推荐使用。
try{
//将channel设置为事务模式
channel.txSelect();
//发布消息到交换器,routingKey为空
channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes("UTF-8"));
//提交事务,只有消息成功被Broker接收了才能提交成功
channel.txCommit();
}catch(Exception e) {
//事务回滚
channel.txRollback();
}
发送端确认机制
上面提到了用事务机制,解决
生产者将信 道设置成confirm(确认)模式,一旦信道进入confirm 模式,所有在该信道上⾯面发布的消息都会被指派 一个唯一的ID(从1 开始),一旦消息被投递到所有匹配的队列之后(如果消息和队列是持久化的,那么 确认消息会在消息持久化后发出),RabbitMQ 就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一 ID),这样生产者就知道消息已经正确送达了。
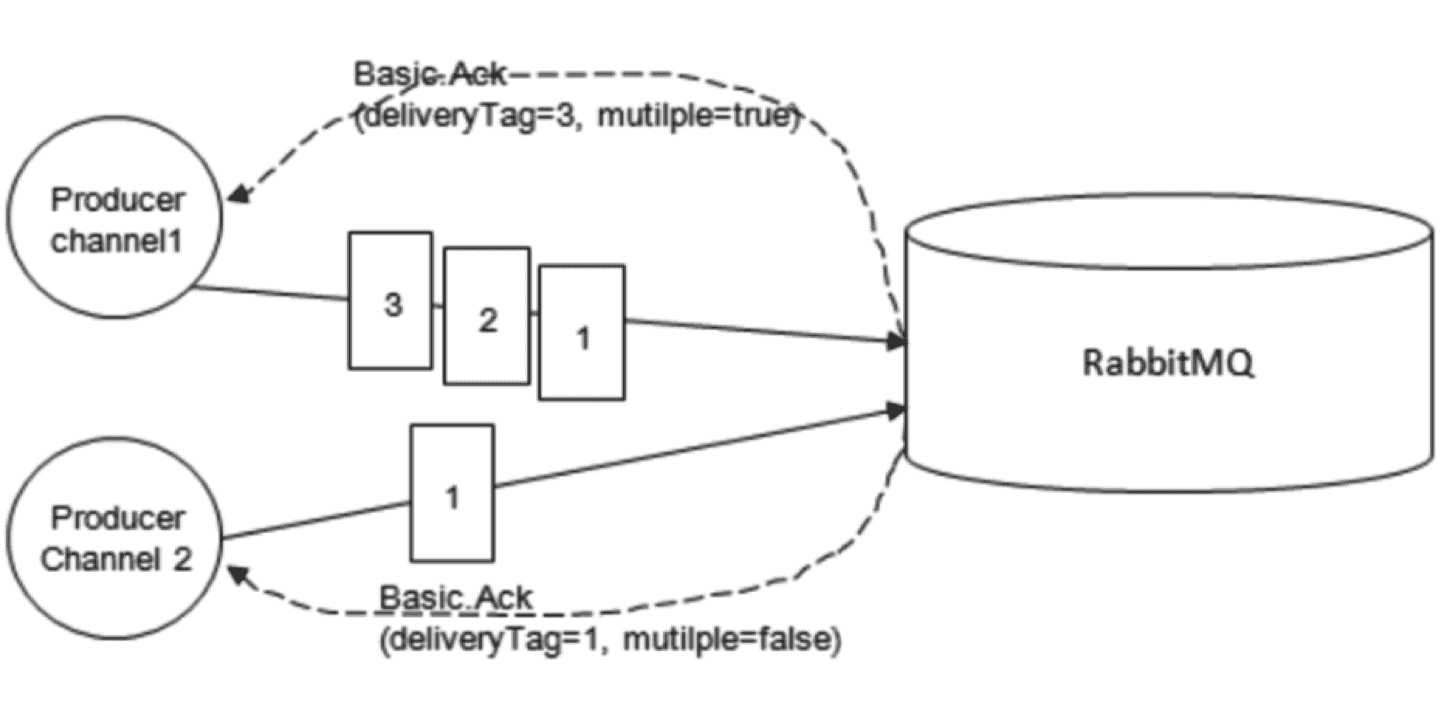
RabbitMQ 回传给生产者的确认消息中的deliveryTag 字段包含了确认消息的序号,另外,通过设 置channel.basicAck方法中的multiple参数,表示到这个序号之前的所有消息是否都已经得到了处理 了。生产者投递消息后并不需要一直阻塞着,可以继续投递下一条消息并通过回调方式处理ACK响应。如果 RabbitMQ 因为自身内部错误导致消息丢失等异常情况发生,就会响应一条nack(Basic.Nack) 命令,生产者应用程序同样可以在回调方法中处理理该 nack 命令。
发送端确认机制实战
安装RabbitMQ
# 安装依赖
yum install -y socat
# 下载和安装erlang
wget https://github.com/rabbitmq/erlang-rpm/releases/download/v23.0.2/erlang-23.0.2-1.el7.x86_ 64.rpm
rpm -ivh erlang-23.0.2-1.el7.x86_64.rpm
# 下载和安装rabbitmq
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.5/rabbitmq-server-3. 8.5-1.el7.noarch.rpm
rpm -ivh rabbitmq-server-3.8.4-1.el7.noarch.rpm
# 启用RabbitMQ的管理插件
rabbitmq-plugins enable rabbitmq_management
# 开启RabbitMQ
systemctl start rabbitmq-server
# rabbitmq-server -detached后台启动
# 添加用户
rabbitmqctl add_user root 123456
# 给用户添加权限,给root用户在虚拟主机"/"上的配置、写、读的权限
rabbitmqctl set_permissions root -p / ".*" ".*" ".*"
# 给用户设置标签
rabbitmqctl set_user_tags root administrator
打开浏览器,访问IP:15672,使用刚才创建的用户登录
如果访问不了,检查防火墙配置,把防火墙关掉
引入依赖
<dependencies>
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
同步发送消息
public class PublisherConfirmProducer {
public static void main(String[] args) throws Exception {
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setUri("amqp://root:123456@10.211.55.11:5672/%2f");
Connection connection = connectionFactory.newConnection();
Channel channel = connection.createChannel();
//设置信道为发送方确认模式
AMQP.Confirm.SelectOk selectOk = channel.confirmSelect();
channel.queueDeclare("queue.pc", true, false, false, null);
channel.exchangeDeclare("ex.pc", "direct",true, false, null);
channel.queueBind("queue.pc", "ex.pc", "key.pc");
//发送消息
channel.basicPublish("ex.pc", "key.pc", null, "hello world".getBytes());
try{
//同步的方式等待
channel.waitForConfirmsOrDie(5_000);
System.out.println("发送的消息已经得到确认");
}catch (IOException ex) {
System.out.println("消息被拒绝");
}catch (InterruptedException ex) {
System.out.println("发送消息的通道不是PublisherConfirms通道");
}catch (TimeoutException ex) {
System.out.println("等待消息确认超时");
}
channel.close();
connection.close();
}
}
waitForConfirm方法有个重载的,可以自定义timeout超时时间,超时后会抛 TimeoutException。类似的有几个waitForConfirmsOrDie方法,Broker端在返回nack(Basic.Nack)之 后该方法会抛出java.io.IOException。需要根据异常类型来做区别处理理, TimeoutException超时是 属于第三状态(无法确定成功还是失败),而返回Basic.Nack抛出IOException这种是明确的失败。上 面的代码主要只是演示confirm机制,实际上还是同步阻塞模式的,性能并不不是太好。
实际上,我们也可以通过“批处理”的方式来改善整体的性能(即批量量发送消息后仅调用一次 waitForConfirms方法)。正常情况下这种批量处理的方式效率会高很多,但是如果发生了超时或者 nack(失败)后那就需要批量量重发消息或者通知上游业务批量回滚(因为我们只知道这个批次中有消 息没投递成功,而并不知道具体是那条消息投递失败了,所以很难针对性处理),如此看来,批量重发 消息肯定会造成部分消息重复。
另外,我们可以通过异步回调的方式来处理Broker的响应。 addConfirmListener 方法可以添加ConfirmListener 这个回调接口,这个 ConfirmListener 接口包含 两个方法:handleAck 和handleNack,分别用来处理 RabbitMQ 回传的 Basic.Ack 和 Basic.Nack。
更高效的批处理形式
public class PublisherConfirmsProducer2 {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUri("amqp://root:123456@10.211.55.11:5672/%2f");
final Connection connection = factory.newConnection();
final Channel channel = connection.createChannel();
// 向RabbitMQ服务器发送AMQP命令,将当前通道标记为发送方确认通道
final AMQP.Confirm.SelectOk selectOk = channel.confirmSelect();
channel.queueDeclare("queue.pc", true, false, false, null);
channel.exchangeDeclare("ex.pc", "direct", true, false, null);
channel.queueBind("queue.pc", "ex.pc", "key.pc");
String message = "hello-";
// 批处理的大小
int batchSize = 10;
// 用于对需要等待确认消息的计数
int outstrandingConfirms = 0;
for (int i = 0; i < 103; i++) {
channel.basicPublish("ex.pc", "key.pc", null, (message + i).getBytes());
outstrandingConfirms++;
if (outstrandingConfirms == batchSize) {
// 此时已经有一个批次的消息需要同步等待broker的确认消息
// 同步等待
channel.waitForConfirmsOrDie(5_000);
System.out.println("消息已经被确认了");
outstrandingConfirms = 0;
}
}
if (outstrandingConfirms > 0) {
channel.waitForConfirmsOrDie(5_000);
System.out.println("剩余消息已经被确认了");
}
channel.close();
connection.close();
}
}
回调形式的发送端确认机制实现
public class PublisherConfirmsProducer3 {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUri("amqp://root:123456@10.211.55.11:5672/%2f");
final Connection connection = factory.newConnection();
final Channel channel = connection.createChannel();
// 向RabbitMQ服务器发送AMQP命令,将当前通道标记为发送方确认通道
final AMQP.Confirm.SelectOk selectOk = channel.confirmSelect();
channel.queueDeclare("queue.pc", true, false, false, null);
channel.exchangeDeclare("ex.pc", "direct", true, false, null);
channel.queueBind("queue.pc", "ex.pc", "key.pc");
//取出前面确认的几条记录,清空他们,保留未确认的
ConcurrentNavigableMap<Long, String> outstandingConfirms = new ConcurrentSkipListMap<>();
ConfirmCallback clearOutstandingConfirms = (deliveryTag, multiple) -> {
if (multiple) {
System.out.println("编号小于等于 " + deliveryTag + " 的消息都已经被确认了");
final ConcurrentNavigableMap<Long, String> headMap
= outstandingConfirms.headMap(deliveryTag, true);
// 清空outstandingConfirms中已经被确认的消息信息
headMap.clear();
} else {
// 移除已经被确认的消息
outstandingConfirms.remove(deliveryTag);
System.out.println("编号为:" + deliveryTag + " 的消息被确认");
}
};
// 设置channel的监听器,处理确认的消息和不确认的消息
channel.addConfirmListener(clearOutstandingConfirms, (deliveryTag, multiple) -> {
if (multiple) {
// todo 将没有确认的消息记录到一个集合中
// outstandingConfirms
// 此处省略实现
System.out.println("消息编号小于等于:" + deliveryTag + " 的消息 不确认");
} else {
System.out.println("编号为:" + deliveryTag + " 的消息不确认");
}
});
String message = "hello-";
for (int i = 0; i < 1000; i++) {
// 获取下一条即将发送的消息的消息ID
final long nextPublishSeqNo = channel.getNextPublishSeqNo();
channel.basicPublish("ex.pc", "key.pc", null, (message + i).getBytes());
System.out.println("编号为:" + nextPublishSeqNo + " 的消息已经发送成功,尚未确认");
outstandingConfirms.put(nextPublishSeqNo, (message + i));
}
// 等待消息被确认
Thread.sleep(10000);
channel.close();
connection.close();
}
}
SpringBoot案例
todo
持久化存储机制
持久化是提高RabbitMQ可靠性的基础,否则当RabbitMQ遇到异常时(如:重启、断电、停机 等)数据将会丢失。主要从以下几个方面来保障消息的持久性:
-
Exchange的持久化。通过定义时设置durable 参数为ture来保证Exchange相关的元数据不不丢失。
-
Queue的持久化。也是通过定义时设置durable 参数为ture来保证Queue相关的元数据不丢失。
-
消息的持久化。通过将消息的投递模式 (BasicProperties 中的 deliveryMode 属性)设置为 2 即可实现消息的持久化,保证消息自身不丢失。
持久化机制实战
public class Producer {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUri("amqp://root:123456@10.211.55.11:5672/%2f");
final Connection connection = factory.newConnection();
final Channel channel = connection.createChannel();
// durable:true表示是持久化消息队列
channel.queueDeclare("queue.persistent", true, false, false, null);
// 持久化的交换器
channel.exchangeDeclare("ex.persistent", "direct", true, false, null);
channel.queueBind("queue.persistent", "ex.persistent", "key.persistent");
final AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 表示是持久化消息
.build();
channel.basicPublish("ex.persistent",
"key.persistent",
properties, // 设置消息的属性,此时消息是持久化消息
"hello world".getBytes());
channel.close();
connection.close();
}
}
RabbitMQ中的持久化消息都需要写入磁盘(当系统内存不不足时,非持久化的消息也会被刷盘处 理理),这些处理理动作都是在“持久层”中完成的。持久层是一个逻辑上的概念,实际包含两个部分:
-
队列索引(rabbit_queue_index),rabbit_queue_index 负责维护Queue中消息的信息,包括 消息的存储位置、是否已交给消费者、是否已被消费及Ack确认等,每个Queue都有与之对应 的rabbit_queue_index。
-
消息存储(rabbit_msg_store),rabbit_msg_store 以键值对的形式存储消息,它被所有队列共享,在每个节点中有且只有一个。
下图中, HOSTNAME/msg_stores/vhosts/$VHostId 这个路路径下包含 queues、msg_store_persistent、 msg_store_transient 这 3 个目录,这是实际存储消息的位置。其中queues目录中保存着 rabbit_queue_index相关的数据,而msg_store_persistent保存着持久化消息数据, msg_store_transient保存着⾮非持久化相关的数据。
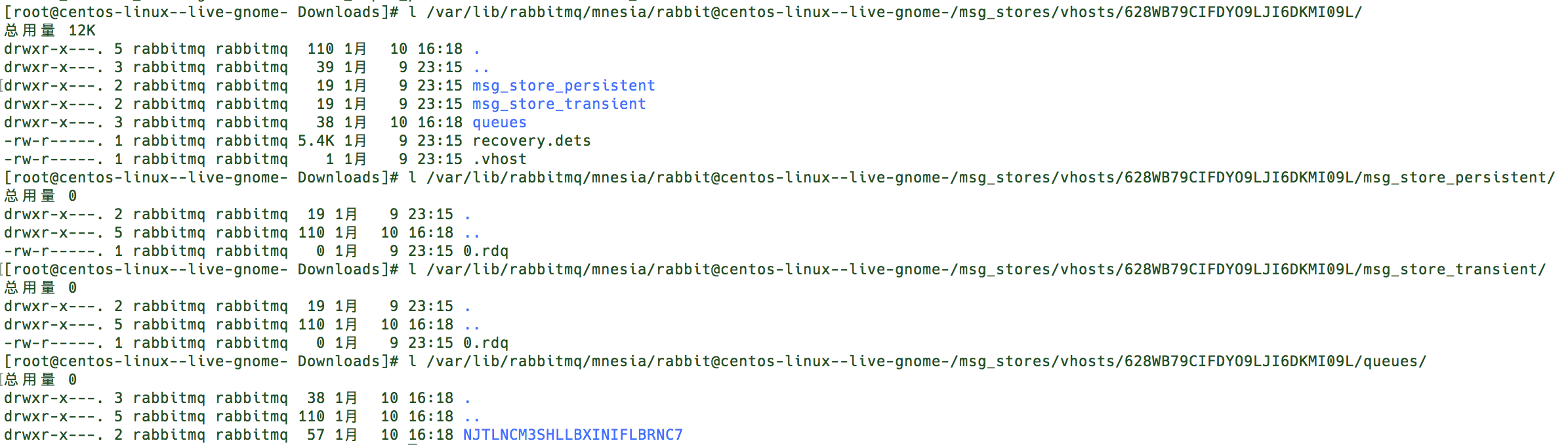
另外,RabbitMQ通过配置queue_index_embed_msgs_below可以根据消息大小决定存储位置, 默认queue_index_embed_msgs_below是4096字节(包含消息体、属性及headers),小于该值的消息存在rabbit_queue_index中。
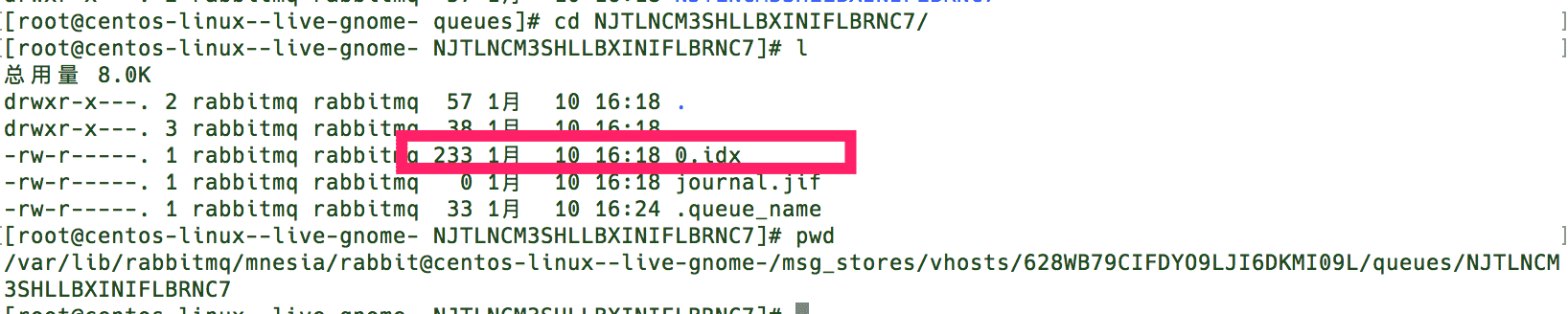
可以看到我们的消息,因为小于4096字节,所以直接存储在索引文件中了。
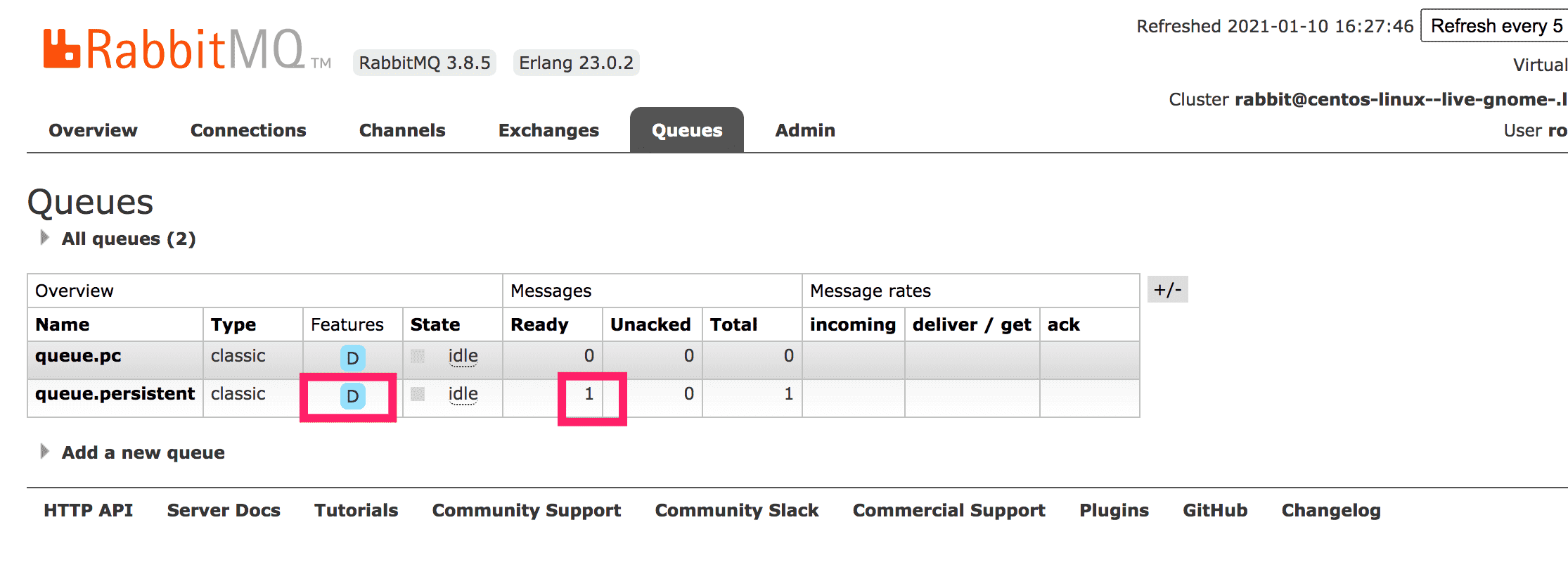
重启后观察交换器、队列、消息是否恢复了
rabbitmqctl stop
rabbitmq-server -detached
Consumer ACK
如何保证消息被消费者成功消费?
前面我们讲了生产者发送确认机制和消息的持久化存储机制,然而这依然无法完全保证整个过程的可靠性,因为如果消息被消费过程中业务处理失败了但是消息却已经出列了(被标记为已消费了,前面都是默认的自动确认),我们又没有任何重试,那结果跟消息丢失没什么分别。
RabbitMQ在消费端会有Ack机制,即消费端消费消息后需要发送Ack确认报文给Broker端,告知自己是否已消费完成,否则可能会一直重发消息直到消息过期(AUTO模式)。
这也是我们之前一直在讲的“最终一致性”、“可恢复性” 的基础。
一般而言,我们有如下处理手段:
-
采用NONE模式,消费的过程中自行捕获异常,引发异常后直接记录日志并落到异常恢复表, 再通过后台定时任务扫描异常恢复表尝试做重试动作。如果业务不自行处理则有丢失数据的风险
-
采用AUTO(自动Ack)模式,不主动捕获异常,当消费过程中出现异常时会将消息放回 Queue中,然后消息会被重新分配到其他消费者节点(如果没有则还是选择当前节点)重新被消费,默认会一直重发消息并直到消费完成返回Ack或者一直到过期
-
采用MANUAL(手动Ack)模式,消费者自行控制流程并手动调用channel相关的方法返回 Ack
SpringBoot方式消费端ACK实战
/**
* NONE模式,则只要收到消息后就立即确认(消息出列,标记已消费),有丢失数据的风险
* AUTO模式,看情况确认,如果此时消费者抛出异常则消息会返回到队列中
* MANUAL模式,需要显式的调用当前channel的basicAck方法
* @param channel
* @param deliveryTag
* @param message */
@RabbitListener(queues = "lagou.topic.queue", ackMode = "AUTO")
public void handleMessageTopic(Channel channel,
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag,
@Payload byte[] message) {
System.out.println("RabbitListener消费消息,消息内容:" + new String((message)));
try {
// 手动ack,deliveryTag表示消息的唯一标志,multiple表示是否是批量确认
channel.basicAck(deliveryTag, false);
// 手动nack,告诉broker消费者处理失败,最后一个参数表示是否需要将消息重新入列
channel.basicNack(deliveryTag, false, true);
// 手动拒绝消息。第二个参数表示是否重新入列
channel.basicReject(deliveryTag, true);
} catch (IOException e) {
e.printStackTrace();
}
}
basicNack和basicReject的区别
basicNack可以用于拒收多条消息
basicReject用于拒收一条消息
原生API形式消费端ACK实战
<dependencies>
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.9.0</version>
</dependency>
</dependencies>
public class MyConsumer {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUri("amqp://root:123456@10.211.55.11:5672/%2f");
final Connection connection = factory.newConnection();
final Channel channel = connection.createChannel();
channel.queueDeclare("queue.ca", false, false, false, null);
// 拉消息的模式
// final GetResponse getResponse = channel.basicGet("queue.ca", false);
// channel.basicReject(getResponse.getEnvelope().getDeliveryTag(), true);
// 推消息模式
// autoAck:false表示手动确认消息
channel.basicConsume("queue.ca", false, "myConsumer", new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body) throws IOException {
System.out.println(new String(body));
// 确认消息
// channel.basicAck(envelope.getDeliveryTag(), false);
// 第一个参数是消息的标签,第二个参数表示不确认多个消息还是一个消息
// 第三个参数表示不确认的消息是否需要重新入列,然后重发
// 可以用于拒收多条消息
// channel.basicNack(envelope.getDeliveryTag(), false, true);
// 用于拒收一条消息
// 对于不确认的消息,是否重新入列,然后重发
// channel.basicReject(envelope.getDeliveryTag(), true);
channel.basicReject(envelope.getDeliveryTag(), false);
}
});
//
// channel.close();
// connection.close();
}
}
public class MyProducer {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUri("amqp://root:123456@10.211.55.11:5672/%2f");
final Connection connection = factory.newConnection();
final Channel channel = connection.createChannel();
channel.queueDeclare("queue.ca", false, false, false, null);
channel.exchangeDeclare("ex.ca", "direct", false, false, null);
channel.queueBind("queue.ca", "ex.ca", "key.ca");
for (int i = 0; i < 5; i++) {
channel.basicPublish("ex.ca", "key.ca", null, ("hello-" + i).getBytes());
}
channel.close();
connection.close();
}
}
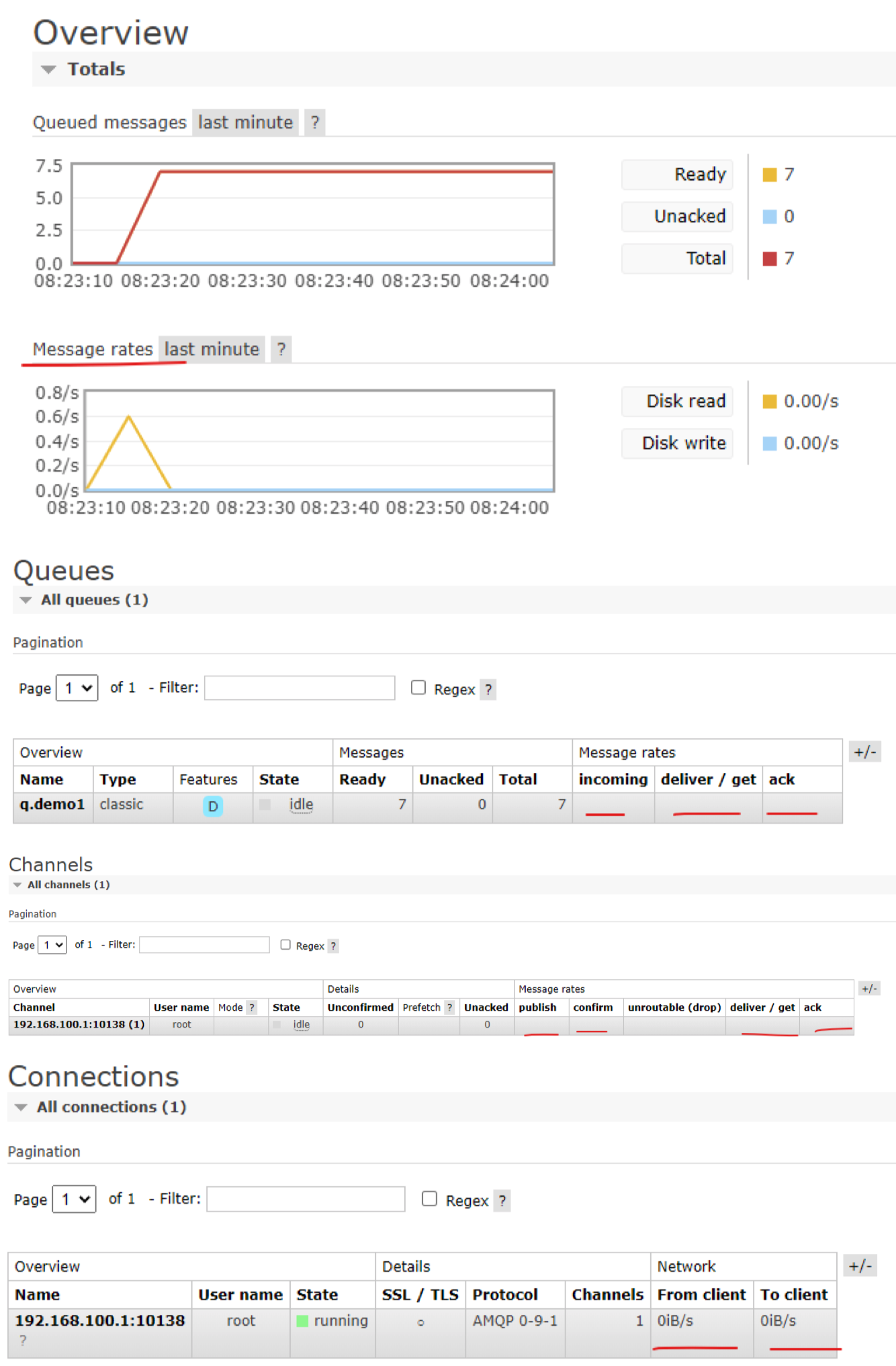
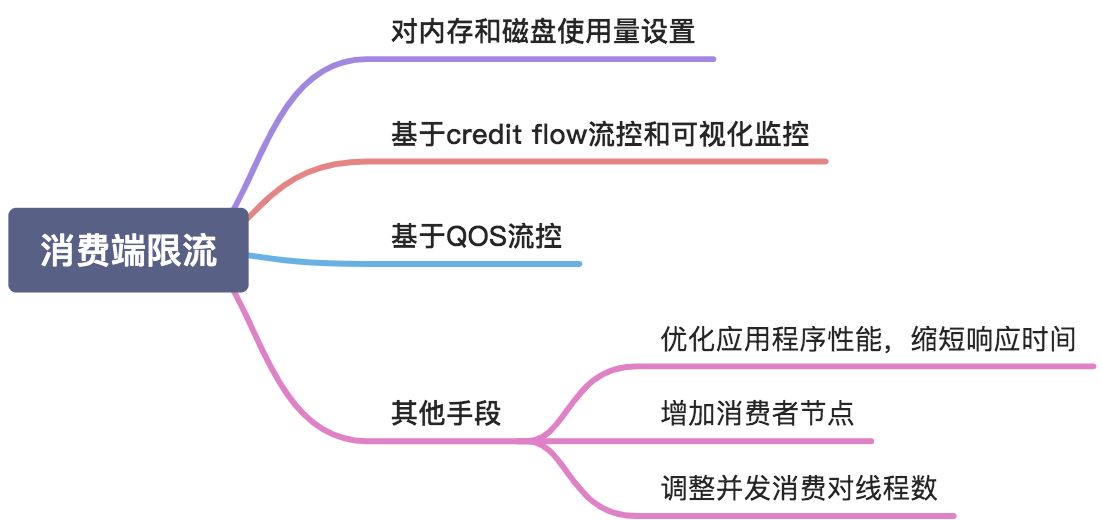
消费端限流
对大量并发写,进行写缓冲,写限流
当消息投递速度远快于消费速度时,随着时间积累就会出现“消息积压”。消息中间件本身是具备一 定的缓冲能力的,但这个能力是有容量限制的,如果长期运行并没有任何处理,最终会导致Broker崩 溃,而分布式系统的故障往往会发生上下游传递,连锁反应那就会很悲剧...
下面我将从多个角度介绍QoS与限流,防止上面的悲剧发生。
对内存和磁盘使用量设置阈值
- RabbitMQ 可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被阻塞(block),直 到对应项指标恢复正常。全局上可以防止超大流量、消息积压等导致的Broker被压垮。当内 存受限或磁盘可用空间受限的时候,服务器都会暂时阻止连接,服务器将暂停从发布消息的已 连接客户端的套接字读取数据。连接心跳监视也将被禁用。所有网络连接将在rabbitmqctl和 管理插件中显示为“已阻止”,这意味着它们尚未尝试发布,因此可以继续或被阻止,这意味着 它们已发布,现在已暂停。兼容的客户端被阻止时将收到通知。
在/etc/rabbitmq/rabbitmq.conf中配置磁盘可用空间大小:

基于credit flow 的流控机制
- RabbitMQ 还默认提供了一种基于credit flow 的流控机制,面向每一个连接进行流控。当单 个队列达到最大流速时,或者多个队列达到总流速时,都会触发流控。触发单个链接的流控可 能是因为connection、channel、queue的某一个过程处于flow状态,这些状态都可以从监控 平台看到。
QoS保证机制
- RabbitMQ中有一种QoS保证机制,可以限制Channel上接收到的未被Ack的消息数量,如果 超过这个数量限制
RabbitMQ将不会再往消费端推送消息。这是一种流控手段,可以防止大量 消息瞬时从Broker送达消费端造成消费端巨大压力(甚至压垮消费端)。比较值得注意的是 QoS机制仅对于消费端推模式有效,对拉模式无效。而且不支持NONE Ack模式。执行 channel.basicConsume 方法之前通过 channel.basicQoS 方法可以设置该数量。消息的发 送是异步的,消息的确认也是异步的。在消费者消费慢的时候,可以设置Qos的 prefetchCount,它表示broker在向消费者发送消息的时候,一旦发送了prefetchCount个消 息而没有一个消息确认的时候,就停止发送。消费者确认一个,broker就发送一个,确认两个就发送两个。换句话说,消费者确认多少,broker就发送多少,消费者等待处理的个数永 远限制在prefetchCount个。
如果对于每个消息都发送确认,增加了网络流量,此时可以批量确认消息。如果设置了 multiple为true,消费者在确认的时候,比如说id是8的消息确认了,则在8之前的所有消息都 确认了。
public class MyConsumer {
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUri("amqp://root:123456@10.211.55.11:5672/%2f");
final Connection connection = factory.newConnection();
final Channel channel = connection.createChannel();
channel.queueDeclare("queue.qos", false, false, false, null);
// 使用basic做限流,仅对消息推送模式生效。
// 表示Qos是10个消息,最多有10个消息等待确认
channel.basicQos(10);
// 表示最多10个消息等待确认。如果global设置为true,则表示只要是使用当前的channel的Consumer,该设置都生效
// false表示仅限于当前Consumer
channel.basicQos(10, false);
// 第一个参数表示未确认消息的大小,Rabbit没有实现,不用管。一般用上面两个
channel.basicQos(1000, 10, true);
channel.basicConsume("queue.qos", false, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body) throws IOException {
// some code going on
// 可以批量确认消息,减少每个消息都发送确认带来的网络流量负载。
channel.basicAck(envelope.getDeliveryTag(), true);
}
});
channel.close();
connection.close();
}
}
以上是客户端通过QOS限流方式
其他限流手段
生产者往往是希望自己产生的消息能快速投递出去,而当消息投递太快且超过了下游的消费速度时 就容易出现消息积压/堆积,所以,从上游来讲我们应该在生产端应用程序中也可以加入限流、应急开关等控制手段,避免超过Broker端的极限承载能力或者压垮下游消费者。
上游加入限流、应急开关
再看看下游,我们期望下游消费端能尽快消费完消息,而且还要防止瞬时大量消息压垮消费端(推模式),我们期望消费端处理速度是最快、最稳定而且还相对均匀(比较理想化)。
提升下游应用的吞吐量和缩短消费过程的耗时,优化主要以下几种方式:
-
优化应用程序的性能,缩短响应时间(需要时间)
-
增加消费者节点实例(成本增加,而且底层数据库操作这些也可能是瓶颈)
-
调整并发消费的线程数(线程数并非越大越好,需要大量压测调优至合理值)
下游三种优化手段
小结
消息可靠性保证的层级
前面对可靠性传输消息回顾:
- 消息传输保障
- 各种限流、应急手段
- 业务层面的一些容错、补偿、异常重试等手段
消息可靠传输一般是业务系统接入消息中间件时首要考虑的问题,一般消息中间件的消息传输保障 分为三个层级:
- At most once:最多一次。消息可能会丢失,但绝不会重复传输
- At least once:最少一次。消息绝不会丢失,但可能会重复传输
- Exactly once:恰好一次。每条消息肯定会被传输一次且仅传输一次
RabbitMQ 支持其中的“最多一次”和“最少一次”。
其中“最少一次”投递实现需要考虑以下这个几个方面的内容:
- 消息生产者需要开启事务机制或者publisher confirm 机制,以确保消息可以可靠地传输到 RabbitMQ 中。
- 消息生产者需要配合使用 mandatory 参数或者备份交换器来确保消息能够从交换器路由到队列中,进而能够保存下来而不会被丢弃。
- 消息和队列都需要进行持久化处理,以确保RabbitMQ 服务器在遇到异常情况时不会造成消息 丢失。
- 消费者在消费消息的同时需要将autoAck 设置为false,然后通过手动确认的方式去确认已经 正确消费的消息,以避免在消费端引起不必要的消息丢失。
“最多一次”的方式就无须考虑以上那些方面,生产者随意发送,消费者随意消费,不过这样很难确保消息不会丢失。(估计有不少公司的业务系统都是这样的,想想都觉得可怕)
由于最多一次会丢消息,所以一般不使用
“恰好一次”是RabbitMQ 目前无法保障的。
考虑这样一种情况,消费者在消费完一条消息之后向RabbitMQ 发送确认Basic.Ack 命令,此时由 于网络断开或者其他原因造成RabbitMQ 并没有收到这个确认命令,那么RabbitMQ 不会将此条消息标 记删除。在重新建立连接之后,消费者还是会消费到这一条消息,这就造成了重复消费。
再考虑一种情况,生产者在使用publisher confirm机制的时候,发送完一条消息等待RabbitMQ返 回确认通知,此时网络断开,生产者捕获到异常情况,为了确保消息可靠性选择重新发送,这样 RabbitMQ 中就有两条同样的消息,在消费的时候消费者就会重复消费。
消息幂等性处理
刚刚我们讲到,追求高性能就无法保证消息的顺序,而追求可靠性那么就可能产生重复消息,从而 导致重复消费...真是应证了那句老话:做架构就是权衡取舍。
RabbitMQ层面有实现“去重机制”来保证“恰好一次”吗?答案是并没有。而且这个在目前主流的消息 中间件都没有实现。
借用淘宝沈洵的一句话:最好的解决办法就是不去解决。当为了在基础的分布式中间件中实现某种 相对不太通用的功能,需要牺牲到性能、可靠性、扩展性时,并且会额外增加很多复杂度,最简单的办 法就是交给业务自己去处理。事实证明,很多业务场景下是可以容忍重复消息的。例如:操作日志收 集,而对一些金融类的业务则要求比较严苛。
一般解决重复消息的办法是,在消费端让我们消费消息的操作具备幂等性。
幂等性问题并不是消息系统独有,而是(分布式)系统中普遍存在的问题。例如:RPC框架调用超 后会重试,HTTP请求会重复发起(用户手抖多点了几下按钮) 幂等(Idempotence)是一个数学上的概念,它是这样定义的:
如果一个函数f(x) 满足:f(f(x)) = f(x),则函数f(x) 满足幂等性。这个概念被拓展到计算机领域,被
用来描述一个操作、方法或者服务。
一个幂等操作的特点是,其任意多次执行所产生的影响均与一次执行的影响相同。一个幂等的方 法,使用同样的参数,对它进行多次调用和一次调用,对系统产生的影响是一样的。
对于幂等的方法,不用担心重复执行会对系统造成任何改变。
举个简单的例子(在不考虑并发问题的情况下):
select * from xx where id=1
delete from xx where id=1
这两条sql语句就是天然幂等的,它本身的重复执行并不会引起什么改变。而update就要看情况 的,
update xxx set amount = 100 where id =1
这条语句执行1次和100次都是一样的结果(最终余额都还是100),所以它是满足幂等性的。而它就不满足幂等性的。
update xxx set amount = amount + 100 where id =1
如何做到幂等
业界对于幂等性的一些常见做法:
-
借助数据库唯一索引,重复插入直接报错,事务回滚。还是举经典的转账的例子,为了保证不 重复扣款或者重复加钱,我们这边维护一张“资金变动流水表”,里面至少需要交易单号、变动 账户、变动金额等3个字段。我们选择交易单号和变动账户做联合唯一索引(单号是上游生成 的可保证唯一性),这样如果同一笔交易发生重复请求时就会直接报索引冲突,事务直接回 滚。现实中,数据库唯一索引的方式通常做为兜底保证;
-
前置检查机制。这个很容易理解,并且有几种实现办法。还是引用上面转账的例子,当我在执 行更改账户余额这个动作之前,我得先检查下资金变动流水表(或者Tair中)中是否已经存在 这笔交易相关的记录了, select * from xxx where accountNumber=xxx and orderId=yyy ,如果已经存在,那么直接返回,否则执行正常的更新余额的动作。为了防止 并发问题,我们通常需要借助“排他锁”来完成。在支付宝有一条铁律叫:一锁、二判、三操 作。当然,我们也可以使用乐观锁或CAS机制,乐观锁一般会使用扩展一个版本号字段做判断 条件
-
唯一Id机制,比较通用的方式。对于每条消息我们都可以生成唯一Id,消费前判断Tair中是否存在(MsgId做Tair排他锁的key),消费成功后将状态写入Tair中,这样就可以防止重复消费了。
对于接口请求类的幂等性保证要相对更复杂,我们通常要求上游请求时传递一个类GUID的请求号 (或TOKEN),如果我们发现已经存在了并且上一次请求处理结果是成功状态的(有时候上游的重试请 求是正常诉求,我们不能将上一次异常/失败的处理结果返回或者直接提示“请求异常”,如果这样重试就 变得没意义了)则不继续往下执行,直接返回“重复请求”的提示和上次的处理结果(上游通常是由于请 求超时等未知情况才发起重试的,所以直接返回上次请求的处理结果就好了)。如果请求ID都不存在或 者上次处理结果是失败/异常的,那就继续处理流程,并最终记录最终的处理结果。这个请求序号由上 游自己生成,上游通用需要根据请求参数、时间间隔等因子来生成请求ID。同样也需要利用这个请求ID 做分布式锁的KEY实现排他。