本文首发于:行者AI
锁在生活中用处很直接,比如给电瓶车加锁就是防止被偷。在编程世界里,「锁」就五花八门了,它们有着各自不同的开销和应用场景。在存在数据竞争的场景,如果选对了锁,能大大提高系统性能,否则会互相拖后腿,性能急剧降低。
加锁的目的就是保证共享资源在任意时间内,只有一个线程可以访问,以此避免数据共享导致错乱的问题。最底层就是两种锁:「互斥锁」和「自旋锁」,其他高级锁,如读写锁、悲观锁、乐观锁等都是基于它们实现的。
1. 互斥锁和自旋锁:谁更轻松高效?
想知道它们谁更高效,要先了解它们在做同一件事情的行为有何不同。假设有一个线程加锁成功,其他线程加锁自然会失败,失败线程的处理方式如下:
- 互斥锁加锁失败后,线程释放CPU,给其他线程;
- 自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
持有互斥锁的线程在看到锁已经有主了之后,就会礼貌的退出,等待之后锁释放时自己被系统唤醒;而自旋锁呢,它居然在反复的询问锁使用完了没有,这实在是... 我写个while循环反复争夺资源,那不就是自旋锁咯?不会吧,不会吧,不会真的有人用自旋锁吧?谁更轻松高效这不是一目了然吗?
其实吧,自旋锁也没那么不堪,使用场景还挺多,在很多场合比互斥锁更好用,我要在本文给自旋锁洗地。至于怎么洗,那需要详细说说它们各自的原理,工程方面的选择,还真就是这么神奇。
2. 互斥锁
互斥锁是一种「独占锁」,比如当线程 A 加锁成功后,此时互斥锁已经被线程 A 独占了,只要线程 A 没有释放手中的锁,线程 B 加锁就会失败,失败的线程B于是就会释放 CPU 让给其他线程,既然线程 B 释放掉了 CPU,自然线程 B 加锁的代码就会被阻塞。
对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。当加锁失败时,内核会将线程置为「睡眠」状态,等到锁被释放后,内核会在合适的时机唤醒线程,当这个线程成功获取到锁后,于是就可以继续执行。如下图:
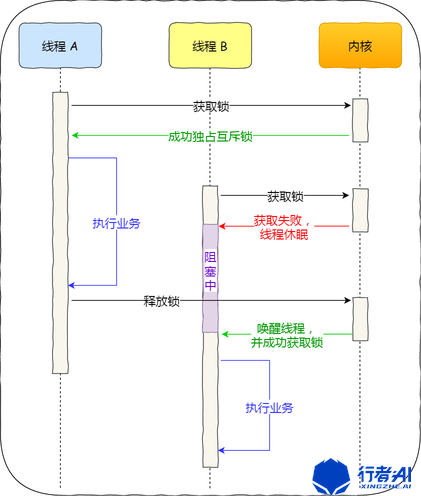
互斥锁加锁失败,就会从用户态陷入内核态,内核帮我们切换线程,这简化了互斥锁使用的难度,但也存在性能开销。
那这个开销成本是什么呢?会有两次线程上下文切换的成本:
- 当线程加锁失败时,内核会把线程的状态从「运行」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运行;
- 接着,当锁被释放时,之前「睡眠」状态的线程会变为「就绪」状态,然后内核会在合适的时间,把 CPU 切换给该线程运行。
线程的上下文切换的是什么?当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
上下文切换需要几十纳秒到几微秒之间,如果锁住的代码执行时间极短(常见情况),那花在两次上下文切换的时间就会远多于锁住代码的执行时长。而且,线程的私有数据已经在CPU的cache上都预热好了,这一出一进,数据可能就凉透了,之后反复的cache miss那可就真的酸爽。所以,锁住的代码执行只需要几纳秒的话,为啥不持有CPU继续自旋等待呢?
3. 互斥锁的原理
上面的互斥锁都基于一个假设: 这锁小明拿了,其他人都不可能再染指,除非小明不要了。咦! 这是咋做到的?
先考虑单核场景:能不能硬件做一种加锁的原子操作呢?能! “test and set”指令就是做这个事情的,因为自己是一条硬件指令,最小执行单位,绝对不可能被打断。有了”test and set"原子指令,单核环境下,锁的实现问题得到了圆满的解决。
那么多核环境呢?简单嘛,还是“test and set”不就得了,这是一条指令,原子的,不会有问题的。真的吗?单独一条指令能够保证该指令在单个核上执行过程中不会被中断,但是两个核同时执行这个指令呢?再想想,硬件执行时还是得从内存中读取lock,判断并设置状态到内存,貌似这个过程也不是那么原子嘛,这可真是套娃啊。那多个核执行怎么办呢?首先我们得明白这个地方的关键点,关键点是两个核会并行操作内存而且从操作内存这个调度来看“test and set”不是原子的,需要先读内存然后再写内存,如果我们保证这个内存操作不能并行,那就回归单核场景了呀!刚好,硬件提供了锁内存总线的机制,我们在锁内存总线的状态下执行test and set操作,就能保证同时只有一个核来test and set,从而避免了多核下发生的问题。
在x86 平台上,CPU提供了在指令执行期间对总线加锁 的手段。CPU芯片上有一条引线#HLOCK pin,如果汇编语言的程序中在一条指令前面加上前缀"LOCK" ,经过汇编以后的机器代码就使CPU在执行这条指令的时候把#HLOCK pin的电位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的CPU就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中的原子性。
能够和 LOCK 指令前缀一起使用的指令如下所示:
BT, BTS, BTR, BTC (mem, reg/imm)
XCHG, XADD (reg, mem / mem, reg)
ADD, OR, ADC, SBB (mem, reg/imm)
AND, SUB, XOR (mem, reg/imm)
NOT, NEG, INC, DEC (mem)
4. 自旋锁
自旋锁是最比较简单的一种锁,一直自旋,利用 CPU 周期,直到锁可用。需要注意,在单核 CPU 上,需要抢占式的调度器(即通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
自旋锁开销少,在多核系统下一般不会主动产生线程切换,适合异步、协程等在用户态切换请求的编程方式,但如果被锁住的代码执行时间过长,自旋的线程会长时间占用 CPU 资源,所以自旋的时间和被锁住的代码执行的时间是成「正比」的关系,我们需要清楚的知道这一点。
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对。这里的忙等待,可以用「while」循环实现,但最好不要这么干!!CPU提供了「PAUSE」指令来实现忙等待。
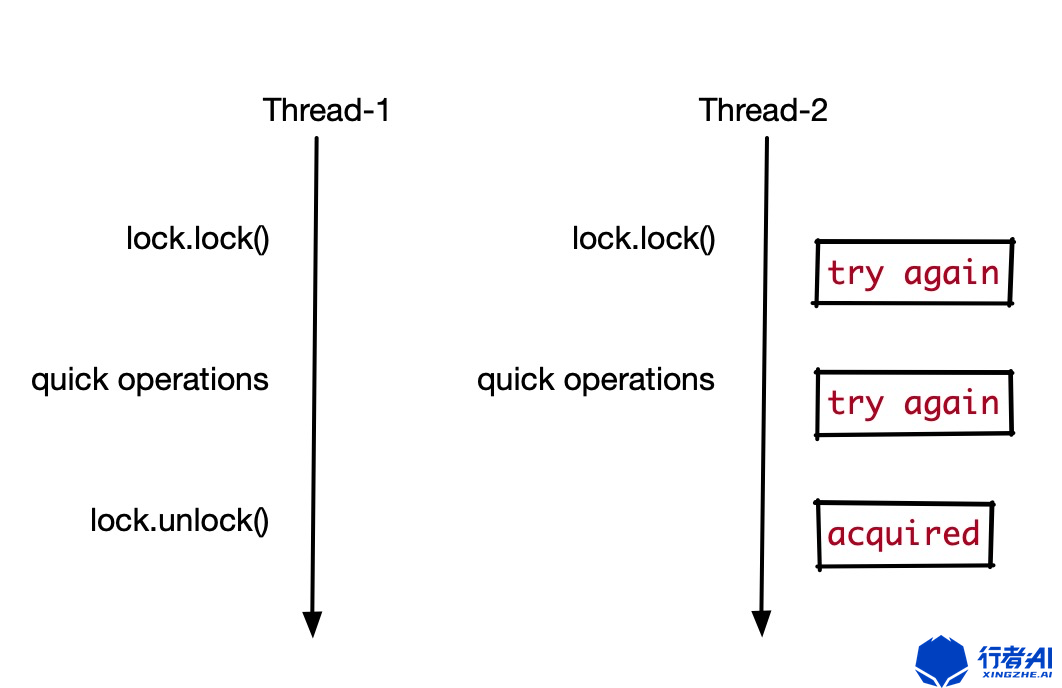
5. 自旋锁原理
自旋锁不就是不停的while循环去获取锁,还需要讲原理?等等,去获取锁状态的时候怎么保证数据原子性?难道又用互斥锁?如果真套一层互斥锁,那我就给自旋锁洗不了地了。显然在这里不能这么套娃!
反复尝试加锁的时候,包含两个步骤:
- 第一步,查看锁的状态,如果锁是空闲的,则执行第二步;
- 第二步,将锁设置为当前线程持有;
这个过程叫做「Compare And Swap」,简称「CAS」,它把上述两个步骤合并成一条硬件级指令,在「用户态」完成加锁和解锁操作,不会主动产生线程上下文切换,所以相比互斥锁来说,会快一些,开销也小一些。
上面说,不推荐while循环获取锁,Intel CPU提供的「PAUSE」指令,「PAUSE」指令是什么?那它如何解决无脑while循环占用CPU且低效率的问题呢?
其实自旋锁不会主动释放CPU,所以不可能解决占用CPU的问题,但能让这个过程更省电,抢占锁效率更高。
「PAUSE」指令通过让CPU休息一定的时钟周期,在此休息期间,耗电几乎停滞。休息的时钟周期,不同版本CPU不一样,大概在几十到上百时钟周期之间。以5Ghz主频运行的CPU为例,一个时钟周期就是0.2纳秒。
休息的时钟周期不是越大越好。比如Intel新一代的Skylake架构中,初期「PAUSE」指令的休息周期高达140个时钟周期。这直接导致MySQL在理论上性能更好的CPU上,数据库性能跑出了比前几年CPU更糟糕的成绩,挤出的牙膏吸回去了!在随后的步进中降低了「PAUSE」的时钟周期到上一代的10个时钟周期,数据库展现的性能才恢复了牙膏厂该有的水准(每代性能提升一丢丢)。
另一个优点跟流水线有关系,频繁的检测会让流水线上充满了读操作。另外一个线程往流水线上丢入一个锁变量写操作的时候,必须对流水线进行重排,因为CPU必须保证所有读操作读到正确的值。流水线重排十分耗时,影响lock()的性能。设想一下,当一个获得锁的工作线程W从临界区退出,在调用unlock释放锁的时候,有若干个等待线程S都在自旋检测锁是否可用,此时W线程会产生一个store指令,若干个S线程会产生很多load指令,在store之后的load指令要等待store在流水线上执行完毕才能执行,由于处理器是乱序执行,在没有store指令之前,处理器对多个没有依赖的load是可以随机乱序执行的,当有了store指令之后,需要reorder重新排序执行,此时会严重影响处理器性能,按照intel的说法,会带来25倍的性能损失。Pause指令的作用就是减少并行load的数量,从而减少reorder时所耗时间。
6. 总结
互斥锁和自旋锁没有优略之分,工程中使用哪种锁,主要还是看使用场景(洗地操作)。
一般情况使用互斥锁。如果我们明确知道被锁住的代码的执行时间很短(这样的场景最普遍,就算不普遍也要改代码让这种场景普遍),那我们应该选择开销比较小的自旋锁,因为自旋锁加锁失败时,并不会主动产生线程切换,而是一直忙等待,直到获取到锁,那么如果被锁住的代码执行时间很短,那这个忙等待的时间相对应也很短。
不管使用的哪种锁,我们的加锁的代码范围应该尽可能的小,也就是加锁的粒度要小,这样执行速度会比较快。
PS:更多技术干货,快关注【公众号 | xingzhe_ai】,与行者一起讨论吧!