本文首发于:行者AI
音乐是一门艺术,是一种通用语言。笔者把音乐定义为不同频率音调的集合。旋律生成是一个在最少人为干预下创作一首旋律的过程。
与基于规则的旋律生成算法不同,基于深度学习的旋律生成算法,可以从旋律数据集中自动的学习如何生成旋律。
本文将从下面几个方面介绍基于深度学习的旋律生成算法:
-
当前主流旋律生成算法的一些缺陷
-
能够解决上述缺陷的旋律生成算法介绍
1. 旋律生成算法的一些缺陷
旋律生成算法需要解决以下几点缺陷:
- 可控制
旋律生成算法不是随意让深度学习模型生成音符,而是需要解决在一定的限制条件下,生成可控制的旋律。
- 结构性
这里的结构性指旋律的方向性以及旋律的结构特征。现有旋律生成算法生成的旋律缺乏旋律曲线的方向性,同时缺乏主歌、副歌、桥段等音乐曲式结构特征。
- 多样性
生成的旋律与现有的训练数据之间可能相似性可能较高,存在抄袭的风险。
- 交互性
现有的旋律生成算法通常是简单的直接生成旋律,但是通常的旋律作品需要作者进行反复的试听、打磨。现有的旋律生成方案缺少这样的交互机制。
2. 能够解决上述缺陷的旋律生成算法介绍
现有的旋律生成算法可以部分解决上述缺陷,下面分别介绍几种现有的旋律生成算法。
2.1 可控制性
旋律生成算法的可控制性指的是,在模型生成旋律的同时,会根据额外的输入,生成的与之相指定的旋律结果。可供选择的输入包括:旋律曲线、和声进行、音乐流派、位置相关特征点(例如每一小节的某个音符与输入相同)等信息维度。
Anticipation-RNN [1]
《Anticipation-RNN Bach melody generation》是一个使用RNN网络的、部分可控的旋律生成算法。其主要思想是在一些关键位置输入音符的控制信息,从而达到生成部分可控旋律的目的。
该算法的主要结构如下图:
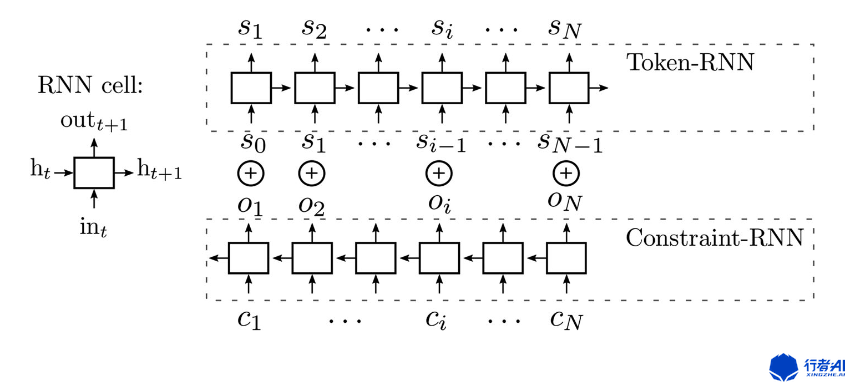
该算法由两条RNN模型组成:Token-RNN以及Constraint-RNN。其中(c_{i})表示与位置相关的限制,(o_{i})表示Constraint-RNN的输出。(o_{i})与(s_{i-1}) 同时输入Token-RNN,输出当前位置的音符信息(s_{i})。
Constraint-RNN的输入包括C(控制当前位置的音符)以及NC(不控制当前位置的音符)。该算法可以让用户使用C控制特定时间节点的音符,不需要控制的音符位置用NC表示。
例如用户想要控制特定位置(例如每个小节的第一个音符)的音符,那么就可以将Constraint-RNN模型的对应位置的输入音符的具体信息(例如音高,时长,力度等),其他位置输入NC符号表示不对音符进行控制,从而控制生成的旋律。
Unit selection and concatenation melody generation [2]
使用unit selection做旋律生成的基本思想是从一个用户提供的高质量的旋律库中提取旋律(通常以小节为单位),然后将挑选出的旋律连接起来形成旋律。
该算法的主要结构如下图:
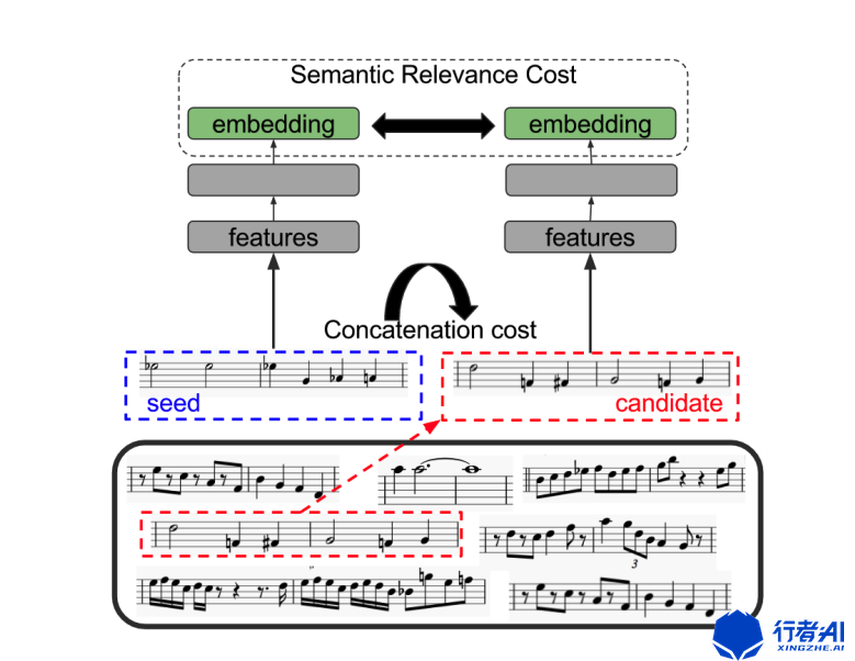
该算法当中包含一个自编码器(提取旋律的隐变量)以及两个LSTM模型(用来评估两条旋律是否能被连接到一起)。该模型首先确定第一个种子旋律(通常是音乐的第一小节旋律),然后以种子旋律为基础,依次从旋律库中调选最合适的旋律组合成最终的旋律。评价旋律是否合适的标准有两个:一个是当前旋律与下一条旋律的隐变量是否符合,另一个是当前旋律的最后一个音符与下一条旋律的首个音符连接到一起是否合适。这两个标准分别由两个不同的LSTM模型负责。
2.2 结构性
旋律生成算法面临的另一项挑战是:大多数旋律生成算法的结果缺乏结构性。也就是说,模型生成的旋律可能听起来像是训练数据集里的旋律,但是这些旋律缺乏一些段落层次感(例如流行音乐的主歌、副歌等不同部分)。
MusicVAE multivoice generation [3]
《MusicVAE multivoice generation》是能够解决结构性问题的一种旋律生成算法,其结构如下图所示:
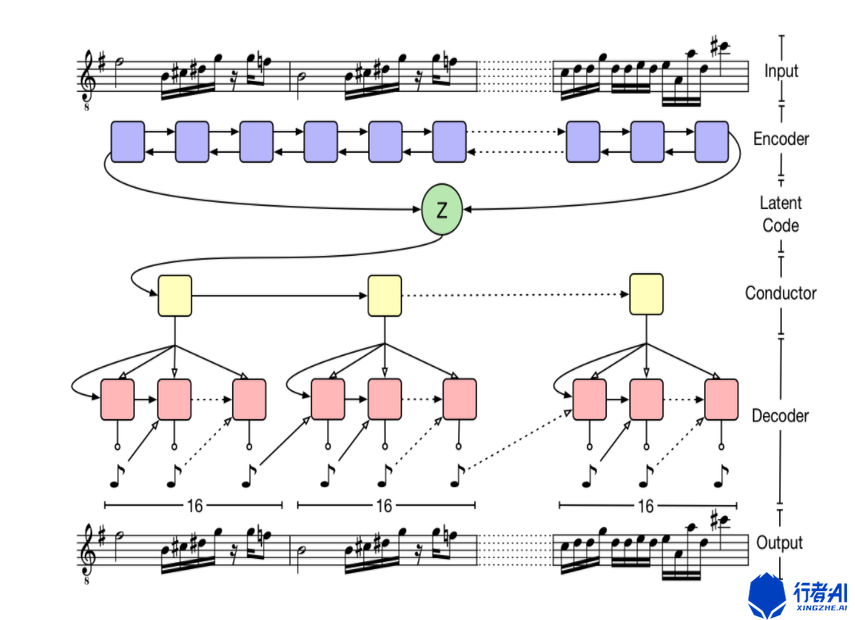
MusicVAE采用了分级生成的方式来控制生成的结果的结构性。与常规的旋律生成算法不同,该模型在使用encoder提取旋律的latent code之后,添加了一层Conductor层。这一层的每一个节点表示一个小节,每个节点下面分别连接了一个RNN模型用来生成对应小节的旋律。
当使用MusicVAE生成旋律数据时,该模型可以保证由模型输入的旋律和模型输出的旋律具有相同的段落特性。
2.3 多样性
多样性是指旋律生成算法生成的旋律与现有的旋律之间是否存在过度相似性,以避免一些版权问题。
MidiNet [4]
MidiNet是一个基于生成对抗网络的旋律生成算法。该算法由Generator CNN,Discriminator CNN以及Conditioner CNN三个部分组成,具体结构如下图所示:
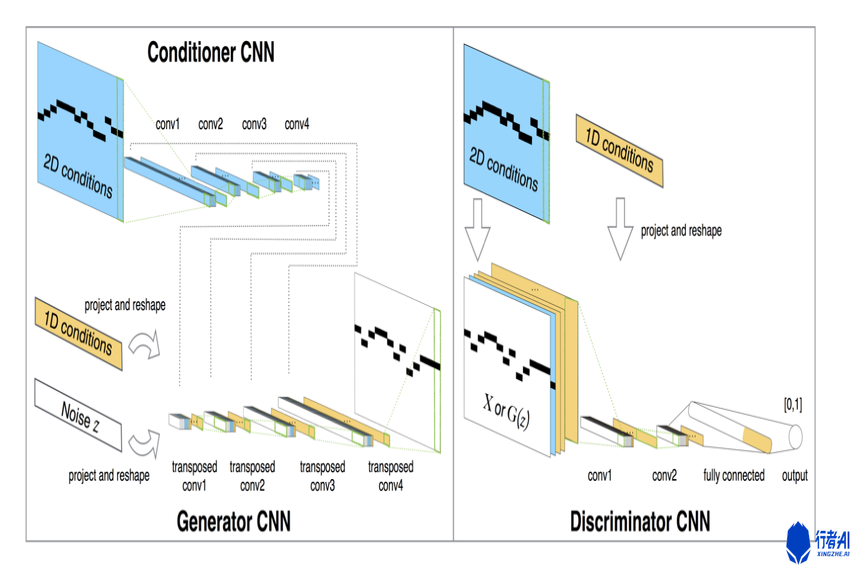
其中Conditioner CNN的输入是之前小节的旋律信息(包括音符序列或者和声进行),输出是处理过后对应的高维度向量,这些向量可以作为Generator CNN的额外控制输入。
为了达到旋律生成的多样性,用户可以在使用Generator CNN生成旋律时,给不同的CNN层添加Conditioner CNN对应层的输出,如果用户需要对旋律添加更多的限制,那么可以给Generator CNN中更对的层添加Conditioner CNN对应的输出,反之亦然。这样可以达到用户控制生成旋律的多样性的效果。
2.4 交互性
在大多数现有的旋律生成算法当中,旋律生成是自动完成的,很少有模型包含与用户交互的生成方式,这就导致,旋律生成模型不支持修改或者是重新生成部分已生成结果,旋律生成模型只能重新生成整段旋律。但是作曲家作曲时的工作流程是靠反复的修改,然后才能得到最终的作品。可以这么说,现有的大多数旋律生成算法对于音乐工作者的帮助是极少的。
DeepBach chorale generation [5]
《DeepBach chorale generation》是支持局部旋律生成的一种旋律生成算法,具体架构如下图所示:
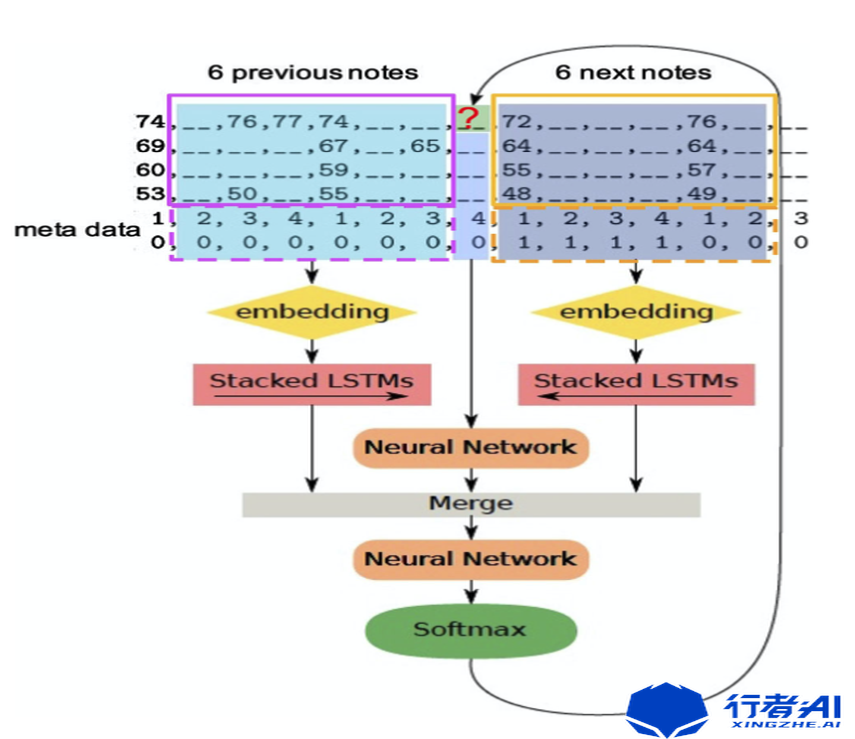
该方案的主要原理是训练时考虑旋律的正向与逆向两个方向的旋律数据,因此DeepBach使用了两个LSTM网络,其中一个网络提取待预测时间点之前的信息,另一个网络提取待预测时间点之后的信息,模型的输出是当前时间点的旋律。也就是说,该算法支持旋律的补全,用户可以在生成完整段旋律之后,重新生成不满意的旋律部分,从而达到算法与用户的可交互性。
参考文献
[1] Hadjeres G, Nielsen F (2017) Interactive music generation with positional constraints using anticipation-RNN. arXiv:1709.06404v1
[2] Bretan M, Weinberg G, Heck L (2016) A unit selection methodology for music generation using deep neural networks. arXiv:1612.03789v1
[3] Roberts A, Engel J, Raffel C, Hawthorne C, Eck D (2018) A hierarchical latent vector model for learning long-term structure in music. In: Proceedings of the 35th international conference on machine learning (ICML 2018). ACM, Montre ́al
[4] Yang LC, Chou SY, Yang YH (2017) MidiNet: a convolutional generative adversarial network for symbolic-domain music gen- eration. In: Proceedings of the 18th international society for music information retrieval conference (ISMIR 2017). Suzhou, China
[5] Hadjeres G, Pachet F, Nielsen F (2017) DeepBach: a steerable model for bach chorales generation. arXiv:1612.01010v2
PS:更多技术干货,快关注【公众号 | xingzhe_ai】,与行者一起讨论吧!