本文首发于:行者AI
TTS是一种将文本文字转变成人类语言信号的一种技术。TTS技术优劣的评判标准是生成的语音信号是否正确、清晰、自然。传统的TTS技术包括拼接法和参数法,但是这两种方法生成的语音信号不自然。端到端的TTS技术能够获得相对比较自然的合成效果,但是同样会出现生成效果不稳定、文字重复或者遗漏等缺点。Expressive TTS是目前语音合成领域中比较活跃的方向,它和单纯TTS的区别是,它更关注合成声音的风格、情感、韵律等等。普通的端到端TTS技术很难精确控制合成结果的韵律、停顿、节奏。
DurIAN: Duration Informed Attention Network For Multimodal Synthesis是腾讯AI Lab于2019年发布的一篇论文。不同于普通的端到端语音合成模型,使用attention机制来控制合成结果的alignment,这篇论文的主要思路是抛弃attention结构,使用一个单独的模型来预测alignment,这样方便在实际使用该模型进行语音合成任务时,用户可以比较方便的输入韵律参数从而控制生成结果。
这里简单介绍下Attention以及Alignment的概念。
Attention机制在TTS框架中的作用是模仿人类发出声音时的机制,即将注意力关注于我们发声时对应的上下文。同样的,Attention模型中,当我们发出当前词语时,我们会寻找源语句中相对应的几个词语,并结合之前的已经发声的部分作出相应的发声,如下图所示,当我们发出“知”这个音时,只需将注意力放在源句中“知”的部分,当发出“力”字时,只需将注意力集中在"是力量“这几个字。
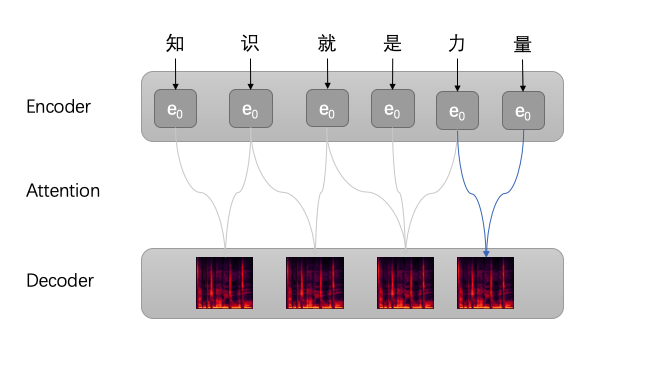
Alignment是对齐的意思,在训练TTS任务的时候,模型需要知道怎么将输入文本与输出频谱进行对齐,常见的方法包括使用Attention机制或者训练专门的模型来进行对齐。
笔者之前一段时间的工作内容是歌唱合成,而歌唱合成的主要目标是:生成节奏与音高满足条件的歌声。本文的主要内容是简单介绍DurIAN论文的核心观点,以及阅读上述论文之后对歌唱合成工作的一些启发。本文将从以下几个方面进行解读:
- 常见语音合成技术简介
- DurIAN基本概念
- DurIAN核心结构
- 对之后工作的启发
1. 常见语音合成技术简介
常见的语音合成技术包含:
- 基于波形拼接技术的语音合成
- 统计参数语音合成
- 端到端语音合成
基于波形拼接的语音合成技术是指在进行语音合成之前, 首先将相应的语音片段储存在计算机中,合成语音时根据特定 的准则选择相应的语音片段,并使用拼接算法将选择出的语音 片段在时域上进行拼接,合成最终的语音。
统计参数语音合成需要一个声码器来将语音信号转化为 代表语音特性的短时频域特征,然后使用统计模型来学习文本 输入与语音特征之间的关系。
端到端合成系统直接输入文本或者注音字符,系统直接输出音频波形。
与传统的语音合成技术相比,端到端语音合成技术有以下优势:
- 使用编码器替代人工设计的语义特征。
- 使用自回归模型减轻了参数式语音合成过度平滑的问题。
- 使用wavenet等声码器替代传统声码器。
- 引入了注意力集制。
常见的端到端语音合成模型由一个编码器,一个注意力模块,一个解码器组成,注意力模块负责将编码器的输出与解码器的输出做对齐。
如下图就是一个常见的Tacotron模型的结构图:
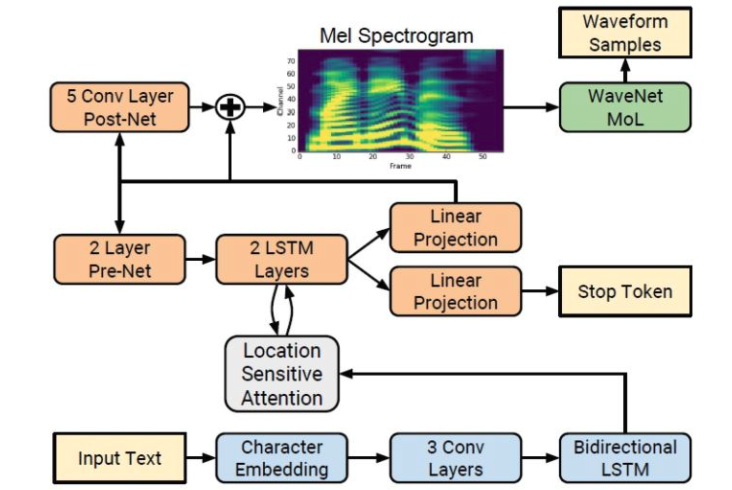
但是这样的attention模块可能会遇到一个问题,如果attention模块得不到较好的训练,或者训练数据不是很多的情况下,attention模块的输出矩阵可能就会使得,解码器在解码的时候出现重复或者遗漏的情况。
2. DurIAN基本概念
DurIAN模型是一种多模态的合成框架,它可以合成非常自然的语音,同时它还能合成说话人的面部表情。
DurIAN模型结合了传统参数式语音合成技术以及端到端语音合成技术,从而该模型有自然性以及鲁棒性的优势。
DurIAN模型的核心思想是:使用类似参数式语音合成技术的对齐模块,替换了端到端模型中的注意力模块,从而解决上述问题。
DurIAN模型的主要贡献有:
- 使用对齐模块替换注意力模块。
- 使用skip encoder架构同时编码音素序列以及中文韵律信息。
- 支持细粒度的不同style的语音合成任务。
- 使用并行waveRNN模型替换源waveRNN模型,提升了合成速度。
3. DurIAN核心结构
DurIAN模型图如下图所示:
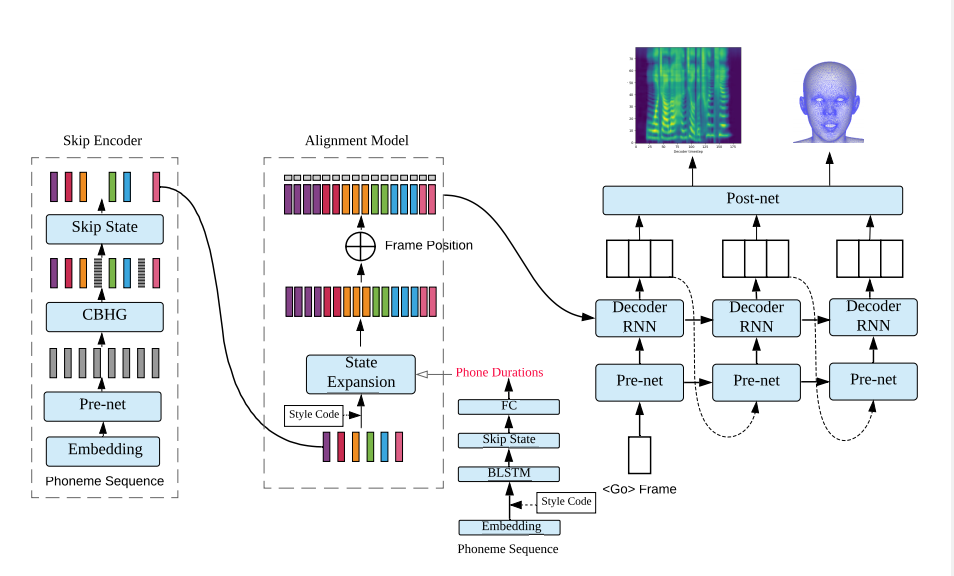
DurIAN架构的输入是文本序列,输出是梅尔频谱图。DurIAN的架构如上图所示,其中包括:
- 编码器,对文本信息以及韵律信息进行编码。对应的是上图左侧部分,其输入是音素序列以及停顿等控制音素,输出是编码好的序列。
- 时长预测模型,该模型负责预测每个音素的发音长度。这个模型对应上图中间部分,该模型的输入是音素序列,输出是每个音素的发声时长。
- 对齐模型,该模型的作用是将输入的文本序列以及输出的梅尔频谱图进行对齐。这个模型对应的是上图的中间部分。
- 自回归解码器网络生成模型的中间输出。这部分对应上图右侧的解码器,输出向量是Post-net的输入向量。
- Post-net用来将中间输出转换成目标输出(适配不同的声码器,或者将输出转换成人脸模型数据等)
编码器的输入是文本韵律符号序列(X_{1:N}),输出是隐状态序列(h_{1:N'}),
其中(N)是包括输入文本和韵律的序列的长度,(N^{'})是不包含韵律信息的输入文本的长度。
时长预测模型的作用是预测每个音素的发声时长,输入是音素序列以及对应时长,输出是每个音速实际发声的时长帧数信息。
对齐模型负责将(encoder)输出的隐变量按照时长预测模型输出的帧数信息进行扩充,获得与梅尔频谱帧数一致的序列信息,
其中T表示输出的梅尔频谱的帧数。此处帧数扩充的方法是简单的将隐向量根据时长预测模型的输出复制。
处理过后的向量将被输送到解码器中进行自回归的方式解码,
解码器的输出最后经过post-net网络得到最终输出
整个网络的loss:
4. 对之后工作的启发
这篇论文的优势在于DurIAN模型实现了一个能够同时控制韵律以及发音时长的TTS系统。
之前一段时间,行者团队对歌唱合成进行了研究,歌唱合成也可以认为是一个需要同时控制发声时刻以及发声时长的TTS系统(同时要考虑音高曲线)。之前的思路是使用类似WaveNet的模型进行语音合成,并不是端到端的合成,最后的合成效果并不如人意。歌唱合成任务与这个任务有很多相似的地方,可以进行借鉴,从而提升合成效果。
PS:更多技术干货,快关注【公众号 | xingzhe_ai】,与行者一起讨论吧!