https://baike.baidu.com/item/MapReduce/133425?fr=aladdin
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
HDFS:Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
体系结构:HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。
特点:
硬件故障、数据访问、大数据集
https://baike.baidu.com/item/hdfs/4836121?fr=aladdin
Hadoop的Shuffle阶段
感谢https://baijiahao.baidu.com/s?id=1651534592726568151&wfr=spider&for=pc
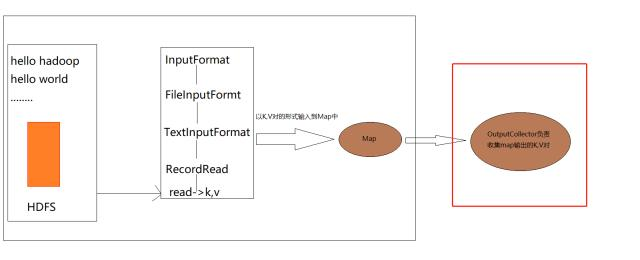
在进入Map之前,首先会将数据从HDFS中读取,进行处理,按照字节偏移量这种之前说的形式处理为K,V对的形式,进入Map阶段。
其中InputFormat可以认为是一种类的继承关系,最终通过调用read方法,生成K,V对,输入到Map中,此时Map接收到的数据就是这个K,V对

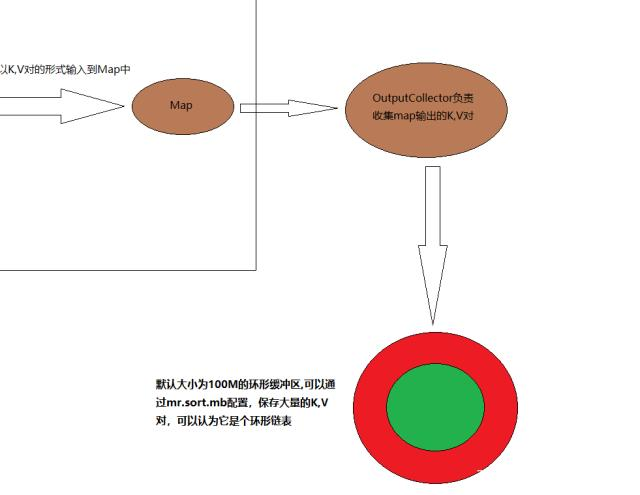
然后数据被OutputCollector收集到(OutputCollector负责收集map输出的K,V对)
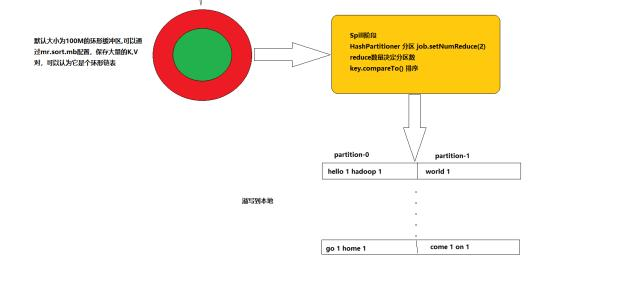
然后进入一个环形缓存区,默认大小为100M的环形缓冲区,通过mr.sort.mb配置,保存大量的K,V对,可以认为它是个环形链表
然后进入Spill阶段
当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘(溢写到本地),在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序
把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件

然后数据进入Reduce阶段(最终图黄色是Reduce)

认为所有的spark操作是在内存中操作的,其实不是的,只能说大量的操作是在内存里的,如果spark也要发生Spill阶段,spark也是没有办法的,也是要落地的。
大数据的操作在内存里面就可以搞定了
1)内存有限,尽可能多的数据放到内存里面去做,但是内存放不下了,就把一部分数据放到磁盘
spark要比maoreuce快是因为 不仅仅是因为在内存里面操作,spark架构也比较好,其实spark的数据都在磁盘也比mapreduce快