这个算法有点难度,一般比较标准的描述网页上也有相关的描述,我在这里就简单的用十分通俗的语言给大家入个门
主要可以结合https://blog.csdn.net/zsfcg/article/details/20738027这一篇来理解
首先要理解一些基本概念,看图
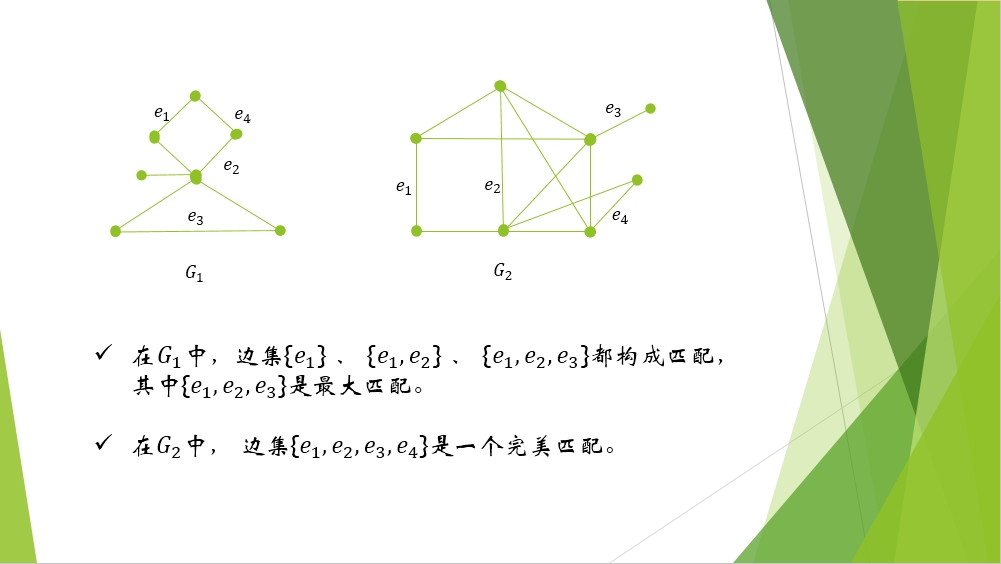
所谓匹配,就是不相邻的边的集合
最大匹配,就是这些集合中,边数最多的那个集合
如果某一个匹配中所有的边的两个端点包含了图上所有的点,就是完美匹配。
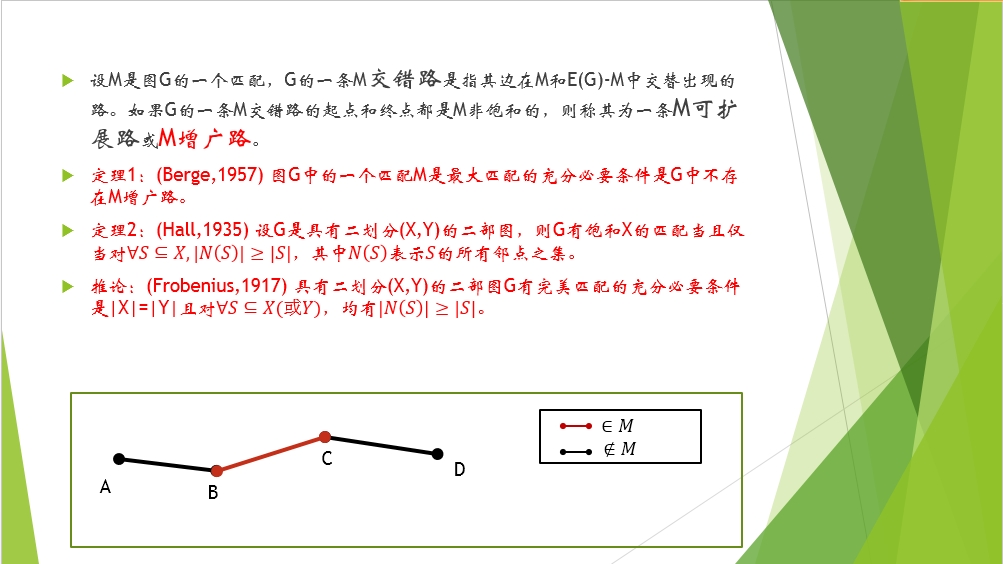
|N(S)|或者|X|或|Y|表示的是相应集合的元素的个数。
N(S)表示与S集合中的顶点相邻接的顶点,例如,A-B-C-D中,B的邻接点就是A和C。
A-B-C-D是一条增广路,红色线表示属于M匹配,黑色线表示不属于,图中,B,C两点是M饱和的,A,D两点是非M饱和的。
交替路故名思意就是交互替错的边,三条连续的边一个是匹配然后一个不是再下一个又是了
扩展路(增广路)可以理解为不是两个端点都在里面,所有的边里面有一些只有一个端点,也就是不饱和。
下面给出这个算法的步骤理解

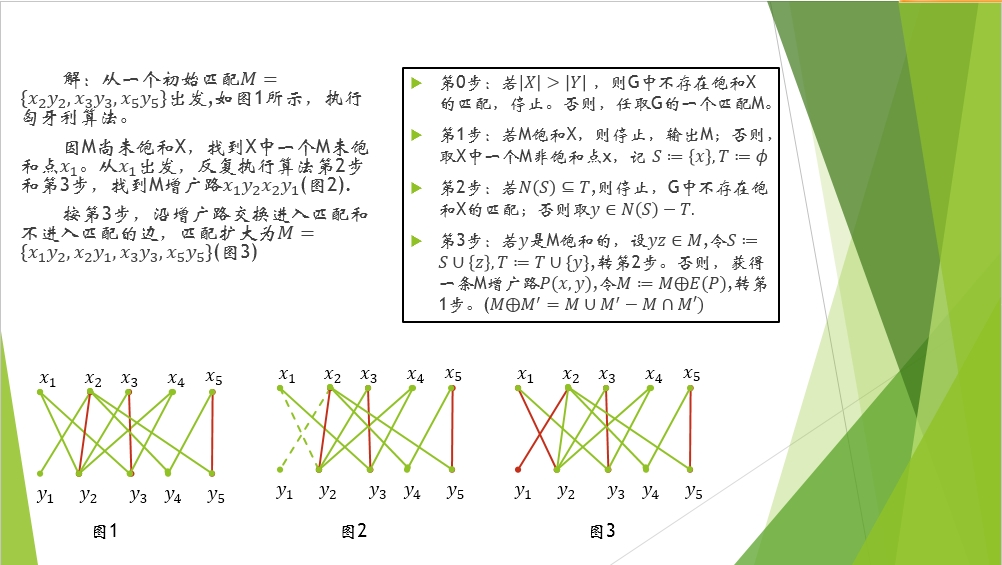
上面这个算法只是针对饱和X的,意思就是,如果X中的每个顶点都已匹配上,那么算法终止,而不必管Y中的顶点是否都有匹配。
圆圈里面一个加号的运算其实可以简单理解为增广路的取反,所谓取反就是把属于M匹配的边变成不属于M的边,把不属于M的边变为属于M的边,在那个A-B-C-D的增广路的图例中就是把A-B和C-D边变成红色而把B-C边变成黑色。这样做一个明显的作用就是匹配的边数增多了一条!
我的理解是,这个算法的最终目的就是输出一个匹配,而其中所有X的端点必须全部包含在里面,
1、首先的前提必须是X比Y的个数要少,
2、然后取一个匹配出来看是不是饱和,是饱和就直接输出,不是的话取一个不饱和的端点放到S中,定义一个T空集合
3、看S中的端点是不是都在T里面,是的话就停止,不是的话S集合中的顶点相邻接的顶点(也就是N(s))去掉T中的点,再从中选一个点y
4、接下来看这个y,看它是不是饱和的
如果是饱和就把它对应的那个饱和的端点z放到S中,把y放到T当中,跳到第三步这里检查;
如果不是饱和,那这个时候有一个点x和它组成了增广路xy,反向选择它两边的路(在上面的实例图中就相当于A-B和C-D边变成红色而把B-C边变成黑色,明显的作用就是增多了一条匹配的边数),然后跳转到第二步。
所以总结一下的话,可以理解为它不断创造条件得到一个包含所有X端点的匹配,如果一开始没有找到,就先从图中找一个没有饱和的点,把它的另一个点加进来,然后看还有没有饱和的可能性),没有就把那条路的相邻的边加进来(就相当于这个边删掉,取它)
网页里面这个ppt的例子很直观,理解完上面的以后再看这个就很简单了
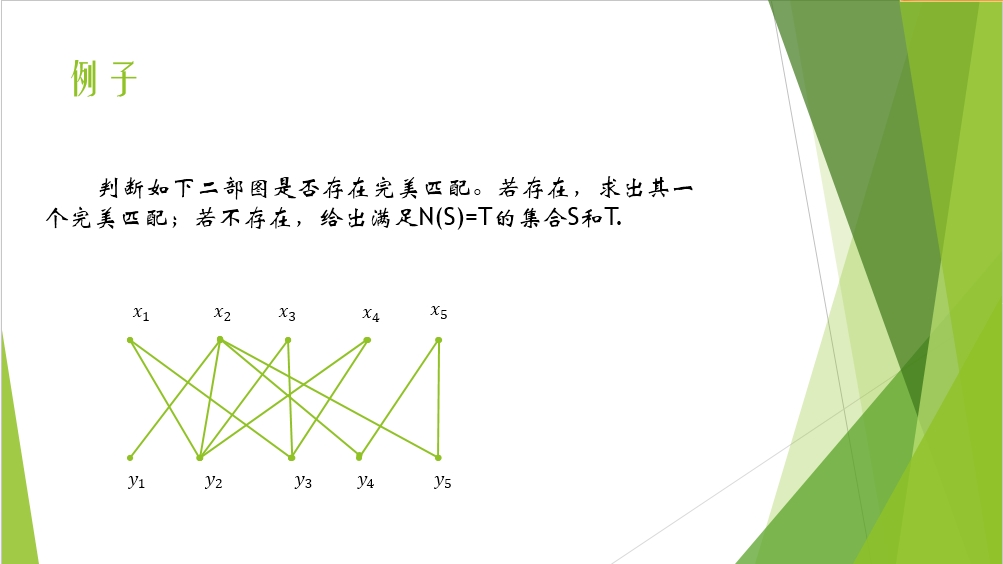
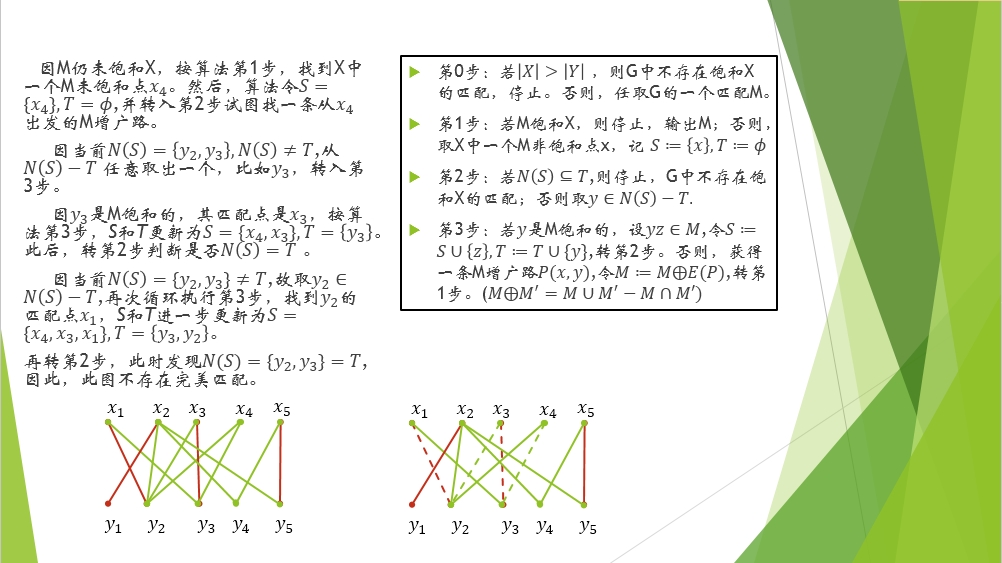
再次提一下N(S)表示与S集合中的顶点相邻接的顶点,而T其实是存放的计算过程中饱和的点
抽象的说,是我们在X这边保存了已经访问过的点S,在Y这边类似有T,从u点开始S和T都不断增大,每次只增大1,增大
的规则是u的邻接点y如果已经匹配z,就把y加到T,z加到S,下一步的操作,是换个u, 再将T中没有访问过的点再次考查
一遍。如果y没有匹配,那正好,根据你的访问规则,这个时候u和y肯定可以配对的,这样就可以增加配对了。
我们的工作是为了让配对的个数越来越多,直到最后不能再配对。不能配对的判定就是Hall定理,S的邻接点刚好是T。
以上就是匈牙利算法的基本步骤和计算过程了
下面来看看求二部图最大匹配的匈牙利算法,就是不管X还是Y,我们求得是含匹配边最多的匹配


一般的,我们会这样取顶点标号的值:l(y)全部赋值为0,而l(x)取得是和顶点x相邻接的所有的点之间的权重的最大值。下面有个例子用的就是这个方法。
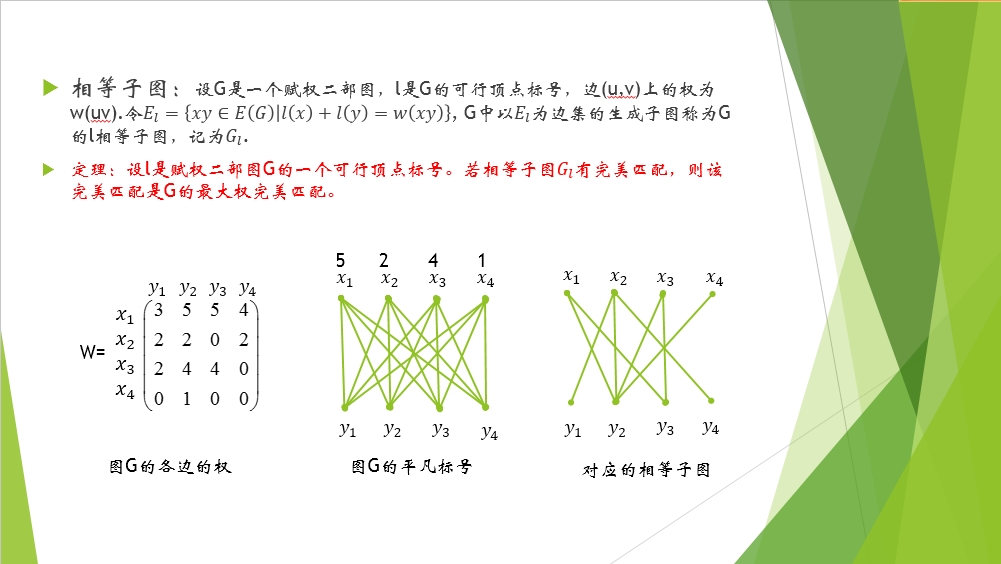
“图G的平凡标号”那个图上X集中的各顶点上的数字5,2,4,1就是顶点标号,Y集中的顶点标号全为0。
这里仔细看一下的话5241就是所有的和这个端点相连的路中权重最大的值,然后把这些权重对应的路都找出来,就是相等子图咯
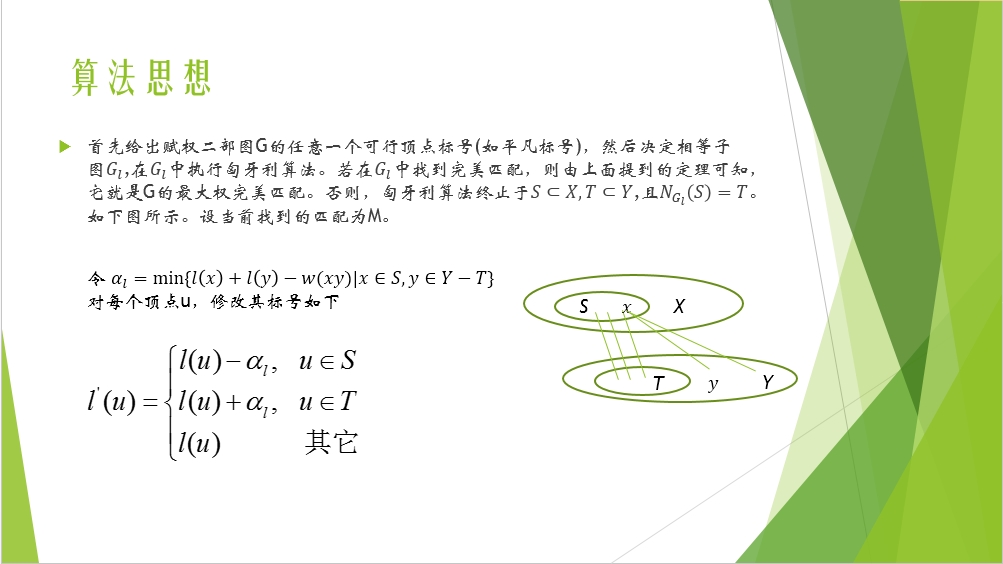
上面这个修改标号的过程是KM算法区别于匈牙利算法的地方。修改的目的是在目前找到的M匹配的基础上增加可行顶点,从而得到增广路。

这是我在写这篇翻阅的一些网站,特此感谢
http://www.bubuko.com/infodetail-2136960.html
https://blog.csdn.net/zsfcg/article/details/20738027
https://www.cnblogs.com/kuangbin/archive/2012/08/19/2646535.html(matlab的实现)
python代码实现的官网:https://pypi.org/project/munkres/1.0.5.4/
摘抄的一些零散的总结帮助大家理解
[二分图带权匹配与最佳匹配]
什么是二分图的带权匹配?二分图的带权匹配就是求出一个匹配集合,使得集合中边的权值之和最大或最小。而二分图的最佳匹配则一定为完备匹配,在此基础上,才要求匹配的边权值之和最大或最小。二分图的带权匹配与最佳匹配不等价,也不互相包含。
这两个的关系比较悬乎。我的理解就是带权匹配是不考虑是不是完备,只求最大或最小权匹配。而最佳匹配则必须在完备匹配的基础上找最大或最小权匹配。
这两个还是结合具体题目比较好理解些。
KM算法是求最大权完备匹配,如果要求最小权完备匹配怎么办?方法很简单,只需将所有的边权值取其相反数,求最大权完备匹配,匹配的值再取相反数即可。
KM算法的运行要求是必须存在一个完备匹配,如果求一个最大权匹配(不一定完备)该如何办?依然很简单,把不存在的边权值赋为0。
KM算法求得的最大权匹配是边权值和最大,如果我想要边权之积最大,又怎样转化?还是不难办到,每条边权取自然对数,然后求最大和权匹配,求得的结果a再算出e^a就是最大积匹配。至于精度问题则没有更好的办法了。
二分图最优匹配:对于二分图的每条边都有一个权(非负),要求一种完备匹配方案,使得所有匹配边的权和最大,记做最优完备匹配。(特殊的,当所有边的权为1时,就是最大完备匹配问题)
定义 设G=<V1,V2,E>为二部图,|V1|≤|V2|,M为G中一个最大匹配,且|M|=|V1|,则称M为V1到V2的完备匹配。
在上述定义中,若|V2|=|V1|,则完备匹配即为完美匹配,若|V1|<|V2|,则完备匹配为G中最大匹配。
KM算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题的。设顶点Xi的顶标为A[i],顶点Yi的顶标为B[i],顶点Xi与Yj之间的边权为w[i,j]。在算法执行过程中的任一时刻,对于任一条边(i,j),A[i]+B[j]>=w[i,j]始终成立,初始A[i]为与xi相连的边的最大边权,B[j]=0。KM算法的正确性基于以下定理:
若由二分图中所有满足A[i]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和(即不是最优匹配)。所以相等子图的完备匹配一定是二分图的最大权匹配。
该算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题的。设顶点Xi的顶标为A[ i ],顶点Yj的顶标为B[ j ],顶点Xi与Yj之间的边权为w[i,j]。在算法执行过程中的任一时刻,对于任一条边(i,j),A[ i ]+B[j]>=w[i,j]始终成立。
KM算法的正确性基于以下定理:
若由二分图中所有满足A[ i ]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。
首先解释下什么是完备匹配,所谓的完备匹配就是在二部图中,X点集中的所有点都有对应的匹配或者是
Y点集中所有的点都有对应的匹配,则称该匹配为完备匹配。
这个定理是显然的。因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。所以相等子图的完备匹配一定是二分图的最大权匹配。
初始时为了使A[ i ]+B[j]>=w[i,j]恒成立,令A[ i ]为所有与顶点Xi关联的边的最大权,B[j]=0。如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。
我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它出发的交错路。这时我们获得了一棵交错树,它的叶子结点全部是X顶点。现在我们把交错树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d,那么我们会发现:
1)两端都在交错树中的边(i,j),A[ i ]+B[j]的值没有变化。也就是说,它原来属于相等子图,现在仍属于相等子图。
2)两端都不在交错树中的边(i,j),A[ i ]和B[j]都没有变化。也就是说,它原来属于(或不属于)相等子图,现在仍属于(或不属于)相等子图。
3)X端不在交错树中,Y端在交错树中的边(i,j),它的A[ i ]+B[j]的值有所增大。它原来不属于相等子图,现在仍不属于相等子图。
4)X端在交错树中,Y端不在交错树中的边(i,j),它的A[ i ]+B[j]的值有所减小。也就说,它原来不属于相等子图,现在可能进入了相等子图,因而使相等子图得到了扩大。
现在的问题就是求d值了。为了使A[ i ]+B[j]>=w[i,j]始终成立,且至少有一条边进入相等子图,d应该等于:
Min{A[ i ]+B[j]-w[i,j] | Xi在交错树中,Yi不在交错树中}。 以上就是KM算法的基本思路。但是朴素的实现方法,时间复杂度为O(n4)——需要找O(n)次增广路,每次增广最多需要修改O(n)次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为O(n2)。实际上KM算法的复杂度是可以做到O(n3)的。我们给每个Y顶点一个“松弛量”函数slack,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(i,j)时,如果它不在相等子图中,则让slack[j]变成原值与A[ i ]+B[j]-w[i,j]的较小值。这样,在修改顶标时,取所有不在交错树中的Y顶点的slack值中的最小值作为d值即可。但还要注意一点:修改顶标后,要把所有的不在交错树中的Y顶点的slack值都减去d。
Kuhn-Munkras算法流程:
(1)初始化可行顶标的值
(2)用匈牙利算法寻找完备匹配
(3)若未找到完备匹配则修改可行顶标的值
(4)重复(2)(3)直到找到相等子图的完备匹配为止
最后还是强调一点:
KM算法用来解决最大权匹配问题: 在一个二分图内,左顶点为X,右顶点为Y,现对于每组左右连接XiYj有权wij,求一种匹配使得所有wij的和最大。
也就是最大权匹配一定是完备匹配。如果两边的点数相等则是完美匹配。
如果点数不相等,其实可以虚拟一些点,使得点数相等,也成为了完美匹配。
最大权匹配还可以用最大流去解决。。。