声名—
部分内容为杜撰,如有雷同,不胜荣幸!
版权所有,如要引用,请标明出处! 如果打赏,请自便!
1 背景介绍
最近一周在忙一个SQL Server 的Bug,一个简单的Bug,更新两张表。
小 Case? 是的小 Case, 一条Update 语句搞得定:
- Update Table SET Columen1 = ‘Value1’, Column12 = ‘Value2’, Where ….
- 再不然,来一条Join 的 Update:
Update TableAlias SET TableAlias.Column1 = JoinedTable.Colum1, TableAlias.Column2 = Value2 FROM TableName AS TableAlias INNER JOIN TableName as JoinedTable ON TableAlias.IdColumn = JoinedTable.IdColumn Where TableAlias.FilterColumn = condition;
- 你还不满足,来一个With 语句 + Join Update
With Help-Table (Column1, Column2, Column3) AS (SELECT Statements AS Complexity AS Possible) Update xx
现在,我们可以Happy 了?Yo, T-SQL 我不拍, Yo, Bug fix 我最强!
然而,生活总不尽如人意?总是要等到伤痕累累后,才在眼泪中明白,有些事不是简简单单就可以明白。
好的,现在给你们更多的背景:
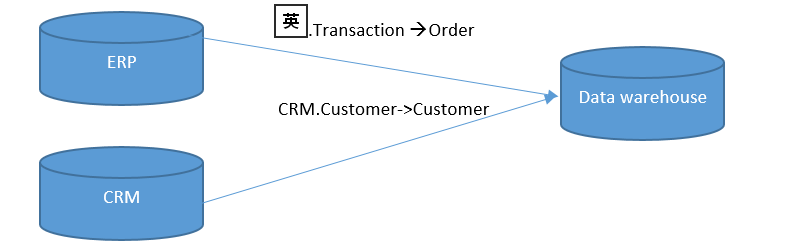
- 需要更新的表,是一个数据仓库数据库(data warehouse)的表 – Customer, Order,它的作用是用来存储历史数据,它的表设计被重新设计以便用来做报表和快速的查询。
- 这两张表的数据就来源于,CRM 系统和ERP 系统,他们通过 ETL(Extraction-Transformation-Loading ,SSIS Package) 写入到这两张表中
- CRM 中的 Customer 的数据量是 2千万+, ERP 中 Order (Transaction) 数据量 2 亿条以上。
- 所有的数据库服务器,均有严格的 Access 权限设置
- 所有的数据库服务器均在使用中
- 只有部分错误的数据列需要被更新
画一张图来大致表示一下:
2 分析
2.1 干系人分析及应对
大部分工程师,程序员,或者技术人员,在拿到工作后第一反应是,用什么技术解决,这很好,但是往往还不够。
因为针对一个问题可以很多的解决方案,当你还不明白问题的全部背景时,做出的解决方案,很有可能能解决问题,但是不可行。
做了很多事情,老板不开心,客户不开心,我也不开心。做了事情,付出了许多努力,但是得不到认可,这不是世界上最悲惨的事么?
让我分析一下这个问题的所有干系人,以及他们的关切:
|
干系人 |
关切 |
备注 |
|
数据仓库管理团队 |
1. Bug 修复 2. 步骤不能太复杂 3. 不能对数据库正常使用有大的影响 |
|
|
CRM 运维团队 |
1. 不管哥的事,不要搞乱我的数据库 2. 给你们只读权限,你们自己看着办 |
|
|
ERP 运维团队 |
1. 不管哥的事,不要搞乱我的数据库 2. 给你们只读权限,你们自己看着办 |
|
|
我的老板 |
1. 赶快给我并把活干完,不然,哼! |
写到这里,不由仰天长叹…. |
好了,现在先做下几件事稳住老板和数据仓库管理团队:
- 发邮件给 “CRM 运维团队”,” ERP 运维团队” 申请可访问的账号
- 做一份计划,发给自己的老板和数据仓库管理团队,计划大致如下 – 高富帅的方式使用 Microsoft Project:
- 申请权限 --
- 分析原因并找出解决方案以供审阅—1 人/天
- 创建模拟环境-- 1人/天
- 实现解决方案 -- 1人/天
- 测试解决方案 -- 1人/天
- 发布解决方案给数据仓库管理团队,包括相应文档 -- 1人/天
- 支持后续问题修复
2.2 技术分析及应对
做技术是一个让工程人员能够安静下来的事情,也是一个能够让你能抛开老板咆哮,客户抱怨的事情。
但是,记住技术是解决问题的,是解决老板和客户问题的,所以技术分析不能把老板,客户排除在外,要密切关注他们的关注,充分考虑他们的需要,这样可以提高老板和客户的满意度,客户爽了,老板爽了,你才能松口气。
好了,根据以上内容进行头脑风暴,列出所有的可能的解决方案:
注意: 在进行头脑风暴时,不要列出优缺点,只提方案。在收集到一些方案后再分析优缺点。
|
编码 |
方案 |
描述 |
优点 |
缺点 |
|
1 |
ETL - SSIS Package |
创建 SSIS 包,部署到数据仓库服务器上 |
||
|
2 |
T-Sql Script |
从 数据仓库服务器创建 Linked Server 到 CRM, ERP 数据库,然后把CRM, ERP 视为本地表执行Update 语句 |
||
|
3 |
Pure C# Code |
通过 ADO.Net 执行所有的更新逻辑 |
||
|
4 |
C# Code + T-SQL |
通过 ADO.Net 执行从CRM,ERP通过 ADO.Net 执行从CRM,ERP 查询数据并存储到文本文件中, 然后通过 T-Sql 读取文本文件脚本执行更新操作查询数据并存储到文本文件中, |
好了,收集到不少的解决方案,现在是进行分析的时候了,看看那个是最佳的解决方案,那个是次佳的解决方案。
|
编码 |
方案 |
描述 |
优点 |
缺点 |
|
1 |
ETL - SSIS Package |
创建 SSIS 包,部署到数据仓库服务器上 |
功能强大强大,可以包含复杂的逻辑 |
1. 对于一次性的执行,成本过高 2. 部署麻烦,且执行完成后需要删除 |
|
2 |
T-Sql Script |
从 数据仓库服务器创建 Linked Server 到 CRM, ERP 数据库,然后把CRM, ERP 视为本地表执行Update 语句 |
简单,清晰,容易执行,开发成本低 |
1. 需要修改 CRM, ERP 数据库服务器配置,从而允许建立 Linked Server 2. 需要不同团队审核,审批 |
|
3 |
Pure C# Code |
通过 ADO.Net 执行所有的更新逻辑 |
简单,清晰,容易执行,开发成本低 |
1. ADO.Net 执行大数据量的更新占用网络带宽,且速度较慢 2. 可能引入代码问题 3. 会部分影响数据仓库使用,应为更新操作是事务,需要加锁 |
|
4 |
C# Code + T-SQL |
通过 ADO.Net 执行从CRM,ERP 查询数据并存储到文本文件中, 然后通过 T-Sql 读取文本文件脚本执行更新操作 |
简单,清晰,容易执行,开发成本低 |
1. ADO.Net 执行从大数据量的操作占用网络带宽,且速度较慢 2. 可能引入代码问题 |
首先,选出最差的,选项1,理由是不能用大炮打蚊子。
其次,选出第二差的3, 理由是不确定因素太多
现在,我们还剩余两个,PK 一下那个是最优选项,从开发成本来说,方案2无疑是最节省成本,对我最有利, 那当然是最优选项,次优的是选项4。
好了,分析完成,发报告给老板还有客户” 数据仓库管理团队” 吧。在邮件里说,经过大量的分析研究,对比实现,我头发掉了一大把,终于找出了一些解决方案,然后再详细的对比分析各种解决方案的优缺点, 最后强烈推荐使用方案2, 实在不行使用方案4。
好了,一天后,老板回信说,因为要保护 CRM, ERP 数据库不受干扰,任何设置更改需要公司董事会决定, 不能搭建 Linked Server, 请使用方案4。
然后,收到邮件后,心里忍不住窃笑,就知道你要用方案4,然后立马回邮件,夸奖老板英明神武,决策正确,真乃千古一老板。然后说因为这个是次优方案,可能导致工作时间延长。并把邮件CC 给客户“数据仓库管理团队”。
呵呵!开始干活!
翌日,老板回信说,因为条件有变,故批准延后一日! -- 开心ing …
生活还是很美好的….
3 技术
从上述分析,我们可以看到,从拿到一个问题,分析问题,调研相应的技术需求和开发本,以及分析相应干系人的关切,是一个比解决问题本身更费力的事情。
记得,在易中天品三国中,有一句话 意识是最简单的就是最有效的,面对问题时先不要自己把他弄复杂了,从最简单的解决方案开始,没有好的方案,只有合适的方案。
要做出,出力又讨好的双赢局面是件很苦难的事情! -- 上下而求索吧…
把解决问题调研用到的技术以及遇到的问题给大家分享一下 ,因为我也是现学现卖,所以不足,错误请指正!
看到这些东西,特别想问老板一句?我是一个 Code 的程序员,不是DBA 也不是 T-SQL 程序员,为什么让我做这么专业的数据库的东西? 为什么?但是我没有去问,因为答案是大家都知道了。如果有不知道的,不懂的,请留言让知道的给你答案!
3.1 Linked Server
3.1.1 什么是Linked Server
先来一段官方解释,当然是英文的 –
Configure a linked server to enable the SQL Server Database Engine to execute commands against OLE DB data sources outside of the instance of SQL Server. Typically linked servers are configured to enable the Database Engine to execute a Transact-SQL statement that includes tables in another instance of SQL Server, or another database product such as Oracle. Many types OLE DB data sources can be configured as linked servers, including Microsoft Access and Excel. Linked servers offer the following advantages:
• The ability to access data from outside of SQL Server.
• The ability to issue distributed queries, updates, commands, and transactions on heterogeneous data sources across the enterprise.
• The ability to address diverse data sources similarly.
没办法,再用我小学英语毕业证的能力来翻译一下,如果看官英文水平达到 CET4 水平则直接跳过-最好是指出错误。
配置一个Linked Server(连接的服务器) 使得SQL Server 数据库引擎能对 位于本SQL Server数据库实例以外的OLEDB 数据源执行SQL命令。
看到一个专业的翻译是:”创建一个链接的服务器,使其允许对分布式的、针对 OLE DB 数据源的异类查询进行访问”。
通常情况下,Linked Server(链接的服务器) 是用来执行访问处于不同SQL Server数据库实例的表的T-SQL 语句,当然表所在的数据库也可以是 Oracle, Access, Excel 等支持 OLE DB的数据源
Linked Server (链接的服务器) 提供如下优点:
• 访问SQL Server 实例以外数据的能力.
• 执行分布式的查询,更新 命令,在企业级的异构/异类的数据源上执行事务的能力
• 把异构/异类的数据源同等对待的能力
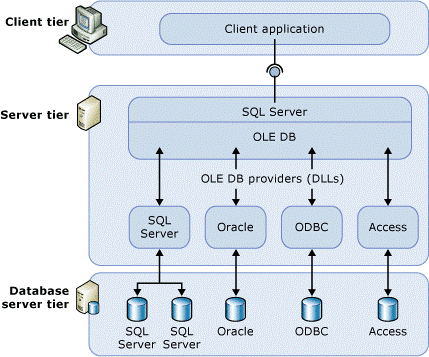
从以上的官方的解释,大概有两点对 Linked Server 比较重要
- OLE DB Provider – OLE DB 数据访问的程序集 (dll), 负责与具体的 OLE DB 数据源进行交互。如果你碰巧使用过 OLE DB Jet 访问 Excel 的话,可能对这个有个比较直观的印象。
如果你熟悉 ADO.NET, Entity Framework 的话对Provider 可谓是轻车熟路。
- OLE DB 数据源 – Oracel 数据库,Excel, Access, CSV, MySql 等几乎现行的所有的数据库都可以,前提是有相应的 OLE DB Provider。
贴一个官方图例:
3.1.2 如何创建 Linked Server
3.1.2.1 手工创建
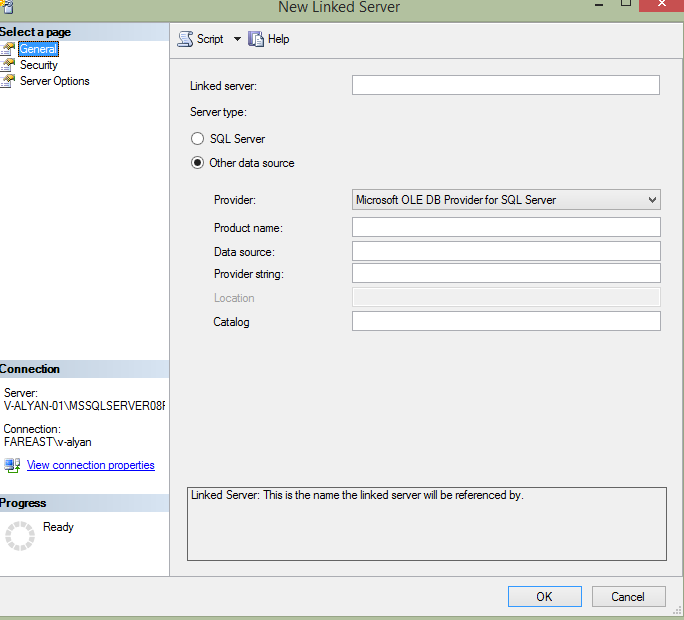
- 打开 “Microsoft SQL Server Management Studio”
- 选择数据库实例-> 右击 Server Objects -> New -> Add Linked Server。具体设置参考- http://msdn.microsoft.com/en-us/library/ff772782.aspx
- 选中已存在的 Linked Server, 右击->Delete/删除,删除Linked Server
3.1.2.2 代码创建
- 创建
exec sp_addlinkedserver @server,@srvproduct,@provider,@datasrc,@location,@provstr,@catalog; -- 类似于手工创建的Generable Tab exec sp_addlinkedsrvlogin @rmtsrvname,@useself,@locallogin,@rmtuser,@rmtpassword; --类似于手工创建的 Seurity Tab exec sp_serveroption @server,@optname,@optvalue; --类似于手工创建的 Server Options Tab
- 删除
sp_dropserver @server
3.1.3 如何使用 Linked Server
使用 linkedservername.catalog.schema.object_name 来访问远程对象:
select * from ERP.CRM.INQ linked_server_name Linked server referencing the OLE DB data source – 数据库服务器名 catalog Catalog in the OLE DB data source that contains the object – 数据库 schema Schema in the catalog that contains the object – 可以省略,类是于 dbo. object_name Data object in the schema – 表
3.1.4 其他
节选自-- http://www.cnblogs.com/RicCC/archive/2009/07/23/sql-server-linked-server.html
SQL Server中使用openquery、openrowset、opendatasource叫做distributed query分布式查询。
SQL Server支持分布式查询主要有2种方式,一种是上面讲到的Linked Server,另外一种叫做Ad Hoc方式,即使用openrowset或者opendatasource。
Linked Server用于执行较频繁的情况,Ad Hoc方式用于执行频率不高的情况
OLE DB provider有2种方式,一种是直接将数据库表作为rowset暴露出来,这样客户程序可以通过OLE DB接口操作这个数据库表,这种方式叫做remote tables。
另外一种是通过OLE DB接口将查询sql语句发送给数据库服务器,服务器执行查询,将rowset返回给客户程序,这种方式叫做pass-through queries
前面查询语句的2种方法,
方法一应当使用remote tables方式,
方法二使用pass-through queries方式。
所以方法二完全支持远程链接服务器的SQL语法
SQL Server将openquery和remote tables返回的rowset当作一个表,查询处理中将它与SQL Server自己的表一样进行处理。Sql中可能对openquery的rowset字段下条件过滤、需要排序、与其他表关联等,SQL Server根据OLE DB provider接口提供的信息,确定这些操作能否委托给远程链接服务器。
OLE DB provider接口能够提供的元数据信息非常有限,不同数据库之间的数据结构造成的数据转换操作等,造成SQL Server对非SQL Server的链接服务器无法进行过多的查询优化策略。使用pass-through queries方式时,远程数据库服务器可以充分利用自己维护的统计信息、索引等优化措施,因此应当尽量使用pass-through queries方式充分的利用链接服务器
3.2 Bulk Insert
通过 Bulk Insert 命令可以把格式化的文本文件,txt, csv 导入到数据库中。
先来一个示例:
bulk insert xsxt.dbo.tabletest from 'c:/data.txt' with( FIELDTERMINATOR=',', ROWTERMINATOR='/n' )
然后标准定义-- http://msdn.microsoft.com/zh-cn/library/ms188365.aspx
BULK INSERT [ [ 'database_name'.][ 'owner' ].]{ 'table_name' FROM 'data_file' }
WITH (
[ BATCHSIZE [ = batch_size ] ],
[ CHECK_CONSTRAINTS ],
[ CODEPAGE [ = 'ACP' | 'OEM' | 'RAW' | 'code_page' ] ],
[ DATAFILETYPE [ = 'char' | 'native'| 'widechar' | 'widenative' ] ],
[ FIELDTERMINATOR [ = 'field_terminator' ] ],
[ FIRSTROW [ = first_row ] ],
[ FIRE_TRIGGERS ],
[ FORMATFILE = 'format_file_path' ],
[ KEEPIDENTITY ],
[ KEEPNULLS ],
[ KILOBYTES_PER_BATCH [ = kilobytes_per_batch ] ],
[ LASTROW [ = last_row ] ],
[ MAXERRORS [ = max_errors ] ],
[ ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ],
[ ROWS_PER_BATCH [ = rows_per_batch ] ],
[ ROWTERMINATOR [ = 'row_terminator' ] ],
[ TABLOCK ],
)
3.3 临时表与表变量
3.3.1 概述
临时表和表变量,都可以在它的生命周期把其视为一个 真实的Table来使用。
当创建本地或全局临时表时,CREATE TABLE 语法支持除 FOREIGN KEY 约束以外的其
它所有约束定义。如果在临时表中指定 FOREIGN KEY 约束,该语句将返回警告信息,指出此约束已被忽略,表仍会创建,但不具有 FOREIGN KEY 约束。在 FOREIGN KEY 约束中不能引用临时表。
临时也是表,是实体,数据保存在数据库文件内。表变量是一种特殊变量,存储在内存中,只对当前会话有效。
考虑使用表变量而不使用临时表。当需要在临时表上显式地创建索引时,或多个存储过程或函数需要使用表值时,临时表很有用。通常,表变量提供更有效的查询处理
3.3.2 局部临时表
局部临时表(local temporary table) –也称本地临时表, 以 # 开头,在会话,过程结束后自动删除,或者显示被 Drop 删除。
--创建临时表#Tmp
create table #Tmp
(
ID int IDENTITY (1,1) not null, --创建列ID,并且每次新增一条记录就会加1
WokNo varchar(50),
primary key (ID) --定义ID为临时表#Tmp的主键
);
Select * from #Tmp --查询临时表的数据
truncate table #Tmp --清空临时表的所有数据和约束
如果局部临时表由存储过程创建或由多个用户同时执行的应用程序创建,则 SQL Server 必须能够区分由不同用户创建的表。
为此,SQL Server 在内部为每个本地临时表的表名追加一个数字后缀。存储在 tempdb 数据库的 sysobjects 表中的临时表,其全名由 CREATE TABLE 语句中指定的表名和系统生成的数字后缀组成。为了允许追加后缀,为本地临时表指定的表名 table_name 不能超过 116 个字符。
除非使用 DROP TABLE 语句显式除去临时表,否则临时表将在退出其作用域时由系统自动删除。
当存储过程完成时,将自动删除在存储过程中创建的本地临时表。由创建表的存储过程执行的所有嵌套存储过程都可以引用此表。但调用创建此表的存储过程的进程无法引用此表。
所有其它本地临时表在当前会话结束时自动删除。
3.3.3 全局临时表 – 以 ## 开头,在没有任何任务引用它时删除,或Drop 语句删除
全局临时表(global temporary table) – 在创建此表的会话结束且其它任务停止对其引用时自动删除。或者使用 Drop 语句显示删除。
任务与表之间的关联只在单个 Transact-SQL 语句的生存周期内保持。换言之,当创建全局临时表的会话结束时,最后一条引用此表的 Transact-SQL 语句完成后,将自动除去此表。
3.3.4 表变量
一种特殊的数据类型,用于存储结果集以供后续处理。该数据类型主要用于临时存储一组行,这些行将作为表值函数的结果集返回。
尽可能使用表变量而不使用临时表。table 变量有以下优点:
- table 变量的行为类似于局部变量,有明确定义的作用域。该作用域为声明该变量的函数、存储过程或批处理。
- 在其作用域内,table 变量可像常规表那样使用。该变量可应用于 SELECT、INSERT、UPDATE 和 DELETE 语句中用到表或表的表达式的地方。但是,table 不能用在下列语句中:INSERT INTO table_variable EXEC 存储过程,SELECT select_list INTO table_variable 语句。
- 在定义 table 变量的函数、存储过程或批处理结束时,自动清除 table 变量。
- 表类型声明中的 CHECK 约束、DEFAULT 值和计算列不能调用用户定义函数。
- 在存储过程中使用 table 变量与使用临时表相比,减少了存储过程的重新编译量。
- 涉及表变量的事务只在表变量更新期间存在。这样就减少了表变量对锁定和记录资源的需求。
不支持在表变量之间进行赋值操作。
declare @t1 table(t1 int) declare @t2 table(t2 int) set @t1=@t2 --错误
3.4 如何把 DataTable 做为参数传递给存储过程
在ADO.Net 中一个非常重要的对象是 DataTable, 我们经常使用 DataAdapter 把查询语句的返回值存储到 DataTable 中。
但是有没有一种可能性,把内存中的 DataTable 作为参数直接传递给数据库?
在SQL Server 数据库中,这是可行的,具体步骤为:
- 定义一个数据库自定义类型:
CREATE TYPE [dbo].[MyTableType] AS TABLE(
Id int,
Code nvarhcar(50)
)
- 假设你定义了一个存储过程使用了自定义类型MyTableType
Create PROCEDURE [dbo].[MyProcedure]
(
@myTableType AS MyTableType READONLY
)
- 在代码中顶一个DataTable
DataTable myDataTable = new DataTable("MyTable");
drProspectFileType.Columns.Add("Id", typeof(int));
drProspectFileType.Columns.Add("Code", typeof(string));
- 创建 SqlCommand 参数,Value为 myDataTable – 内存DataTable 参数。
- 注意: SqlDbType, TypeName 的赋值
SqlParameter para = new SqlParameter("@myTableType ", SqlDbType.Structured)
{
TypeName = "dbo. MyTableType",
Direction = ParameterDirection.Input,
Value = myDataTable
};
4 源代码
干货来了。。。
不解释,自己看。。。
4.1 C# 代码
using System;
using System.Configuration;
using System.Data;
using System.Data.SqlClient;
using System.IO;
using System.Text;
namespace DataFixer
{
internal class Program
{
private static void Main(string[] args)
{
var crmConnectionString = ConfigurationManager.ConnectionStrings["CRMDbConnectionString"].ConnectionString;
var erpConnectionString = ConfigurationManager.ConnectionStrings["ERPDbConnectionString"].ConnectionString;
var UpdateSql = ConfigurationManager. AppSettings["UpdateSql"];
var CleanSql = = ConfigurationManager. AppSettings["CleanSql "];
PrintUseage();
try
{
var outPutFolder = ConfigurationManager.AppSettings["OutputFolder"];
if (string.IsNullOrEmpty(outPutFolder) || !Directory.Exists(outPutFolder) || string.IsNullOrEmpty(crmConnectionString) || string.IsNullOrEmpty(axConnectionString))
{
Console.WriteLine("Wrong configuration, please check by the usage description ....");
PrintUseage();
}
// get from ContactId & EmailAddress1 from CRM where EamialAddress 1 Is Not Null and ContactId is not Null
var crmFilePath = Path.Combine(outPutFolder, "crmIdEmail.txt");
if (!string.IsNullOrEmpty(ConfigurationManager.AppSettings["CRMIdAndEmailFromCRMOutputFile"]))
{
Console.WriteLine("Export CRMId, Email from CRM database to " + ConfigurationManager.AppSettings["CRMIdAndEmailFromCRMOutputFile"] + " ... ");
var contactIdEmailDataTable = new DataTable();
FillDataTable(contactIdEmailDataTable,
crmConnectionString,
"SELECT [ContactId],[EmailAddress1] AS [Email] FROM dbo.Contact (nolock) WHERE [ContactId] IS NOT NULL AND [EmailAddress1] IS NOT NULL");
ExportCrmidEMailFromCrmToCsv(contactIdEmailDataTable, crmFilePath);
Console.WriteLine("Export CRMId, Email from CRM database to " + ConfigurationManager.AppSettings["CRMIdAndEmailFromCRMOutputFile"] + "completed.");
}
// get TransacitonId,CustomerId from Ax database
var axFilePath = Path.Combine(outPutFolder, "crmIdAndTransactionId.txt");
if (!string.IsNullOrEmpty(ConfigurationManager.AppSettings["TransactionIdAndCustomerIdFromAxOutputFile"]))
{
Console.WriteLine("Export TransactionId, CustomerId from AX database to " + ConfigurationManager.AppSettings["TransactionIdAndCustomerIdFromAxOutputFile"] + " ... ");
var srcOrderIdCusAccountTable = new DataTable();
FillDataTable(srcOrderIdCusAccountTable,
axConnectionString,
@"SELECT [Store]+[Terminal]+[TransactionID] AS TransactionId , [CRMCustAccount] FROM [RBOTransactionTable] (nolock) WHERE CRMCUSTACCOUNT != '' and Dataareaid='mrs'");
ExportTransactionIdAndCustomerIdToCsv(srcOrderIdCusAccountTable, axFilePath);
Console.WriteLine("Export TransactionId, CustomerId from AX database to " +
ConfigurationManager.AppSettings["TransactionIdAndCustomerIdFromAxOutputFile"] +
" completed.");
}
Console.WriteLine("Generating update.sql...");
File.WriteAllText(Path.Combine(outPutFolder, "update.sql"), string.Format(UpdateSql, crmFilePath, axFilePath));
Console.WriteLine("Generating clean.sql ....");
File.WriteAllText(Path.Combine(outPutFolder, "clean.sql"), CleanSql);
Console.WriteLine("Press any key to exit.");
Console.Read();
}
catch (Exception ex)
{
Console.WriteLine("Excepiton occured during the process:" + Environment.NewLine
+ "Exception message:" + ex.Message + Environment.NewLine +
"Stack Trace:" + ex.StackTrace);
Console.WriteLine("You may need prelong the connectiontimeout time in configure file and then rerun this applicaton.");
}
}
private static void PrintUseage()
{
Console.WriteLine(new string('*', 40) + "Usage" + new string('*', 40));
Console.WriteLine();
Console.Write(@"Ensure you modified config based on you real enviroments:
1.ConnectionString: CRMDbConnectionString: database connection string of CRM
2.ConnectionString:AXDbConnectionString: database of AX
3.AppSetting: OutputFolder: the folder you want to put all the files.
And it should can be accessed by RODS server.
Otherwise copy all files generated to a folder that can be accessed manually.
Recommend a UNC path like \servernamefoldername.
The files generated like below, any you maybe need modify it before you run it:
a. crmIdEmail.txt a text file from CRM stores CRMId, Email info
b. crmIdAndTransactionId.txt a text file from AX stores TransactionId, CustomerId info
c. update.sql which is to update the RODS Customer and Order table
d. clean.sql delete all the temp global table");
Console.WriteLine();
Console.WriteLine();
Console.WriteLine(new string('*', 40) + "Usage" + new string('*', 40));
}
private static void ExportTransactionIdAndCustomerIdToCsv(DataTable dt, string filePath)
{
var stringBuilder = new StringBuilder(1024 * 1024);
foreach (DataRow row in dt.Rows)
{
stringBuilder.Append(string.Format("{0},{1}", row[0], row[1]));
stringBuilder.AppendLine();
}
File.WriteAllText(filePath, stringBuilder.ToString());
}
private static void ExportCrmidEMailFromCrmToCsv(DataTable contactIdEmailDataTable, string filePath)
{
var stringBuilder = new StringBuilder(1024 * 1024);
foreach (DataRow row in contactIdEmailDataTable.Rows)
{
stringBuilder.Append(string.Format("{0},{1}", row[0], row[1]));
stringBuilder.AppendLine();
}
File.WriteAllText(filePath, stringBuilder.ToString());
}
private static void FillDataTable(DataTable filledDt, string connectionString, string commandText)
{
using (var connection = new SqlConnection(connectionString))
{
connection.Open();
var sqlCommand = connection.CreateCommand();
sqlCommand.CommandText = commandText;
sqlCommand.CommandType = CommandType.Text;
var dataAdapter = new SqlDataAdapter
{
SelectCommand = sqlCommand
};
dataAdapter.Fill(filledDt);
}
}
}
}
4.2 Sql 脚本:
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER OFF GO /*Update Customer Table*/ CREATE TABLE ##crmIdEmailInMemory([CrmId] nvarchar(50) ,[EMail] nvarchar(150)); BULK INSERT ##crmIdEmailInMemory FROM '\servername estcrmIdEmail.txt' WITH( FIELDTERMINATOR = ',', ROWTERMINATOR = ' ' ) --Execute Update SQL UPDATE C SET C.CrmId = T.CrmId FROM dbo.[Customer] AS C INNER JOIN ##crmIdEmailInMemory AS T ON C.Email = T.EMail WHERE C.CrmId IS NULL /*-- Update Order Table --*/ CREATE TABLE ##tranasactionIdAndCustomerIdInMemory([TransactionId] nvarchar(50) ,[CustomerId] nvarchar(50)); BULK INSERT ##tranasactionIdAndCustomerIdInMemory FROM '\servername estcrmIdAndTransactionId.txt' WITH( FIELDTERMINATOR = ',', ROWTERMINATOR = ' ' ); --Execute Update SQL On Orders table -- CustomerId WITH CustomerTempTable( TransactionId, CustomerId ) AS (SELECT Trans.TransactionId AS TransactionId, C.CustomerId AS CustomerId FROM dbo.Customer AS C INNER JOIN ##tranasactionIdAndCustomerIdInMemory AS Trans ON C.CrmId = Trans.CustomerId) UPDATE O SET O.CustomerId = T.CustomerId FROM dbo.[Order] AS O INNER JOIN CustomerTempTable AS T ON O.SrcOrderId = T.TransactionId Where O.CustomerId = -1 And O.ChannelId = 1; GO