一。Hibernate概述
ORM框架诞生的意义
在JavaWeb中,我们使用JDBC来操作数据库,并且需要对不同的数据库来编写不同的原生态sql。在我们使用Java这种面向对象语言来进行应用开发的时候,从项目的初期,我们要进行面向对象分析(OOA),面向对象设计(OOD),面向对象编程(OOP)。但是到了持久层数据库访问时,就要考虑关系数据库的访问方式。显然面向对象与基于关系的思想完全不同,于是我们需要一个工具,这个工具可以把关系数据库包装成面向对象模型,因此ORM框架的使得我们可以用面向对象的方式来操作数据库
ORM框架是面向对象程序设计语言与关系数据库发展不同步时的中间解决方案。
ORM框架提供的思路
那么ORM框架如何解决了面向对象到关系数据库之间的问题?映射!
ORM基本映射有:
(1)数据表映射类:持久化类与数据表的映射
(2)数据表的行映射对象:持久化类实例与数据表一条记录的映射
(3)数据表的列映射对象属性:持久化类的属性类型与数据表中字段类型的映射。
正是基于这三种基本映射,ORM工具可以完成对象模型和关系模型之间的相互映射,由此看来持久化类是一种中间媒介,我们只需要对持久化类进行操作,就有ORM框架自动帮我们生成JDBC,来进行操作。使得Java程序员从关系模型中解脱出来。
ORM框架-Hibernate
Hibernate是目前比较的流行的ORM框架,Hibernate不仅管理Java类(持久化类)到数据表的映射,还提供了数据查询,获取数据的方法,大幅度减少了人工使用SQL和JDBC处理数据的时间
Hibernate相比较其他ORM框架的优势
(1)开源和免费的License,研究源代码,改写源代码,进行功能定制
(2)轻量级封装,避免引入过多复杂问题,调试容易
(3)有可扩展性,API开放。
Hibernate比较其他持久层解决方案的优势
(1)面向对象编程
(2)可以使用缓存。值得一提,hibernate的缓存是世界级的,Hibernate中缓存有很多种,一级缓存,二级缓存,查询缓存。
(3)编程比较简单,和Spring一整盒,更加的简单
(4)跨平台很好,因为面向对象,无论底层的数据库是什么,
Hibernate的缺点
(1)效率比较低,因为底层就是对jdbc的封装。
(2)一张表如果有上千万的数据,则hibernate不适合,效率惨不忍睹。
(3)如果表与表之间的关系复杂,则hibernate不适合。比如:淘宝,京东这样的网站就不适合用hibernate,因为数据量又大又负责。
Hibernate的适用范围
企业内部的系统,因为企业内部数据量不大。
二。第一个Hibernate项目(CRUD)
1. 创建项目
2. 导入jar包
(1) hibernate-distribution-x.x.x Final 文件夹中的
hibernate3.jar
作用:核心包
(2) hibernate-distribution-x.x.x Final 文件夹中的
(1.1)/lib/required下的6个jar包
antlr-2.7.6.jar
作用:语言转换工具:Hibernate利用它实现HQL到SQL的转换
commons-collections-3.1.jar
作用:collections Apache的工具集,用来增强Java对集合的处理能力
dom4j-1.6.1.jar
作用:dom4j XML 解析器
javassist-3.12.0.GA.jar
作用:代码生成工具,Hibernate用它在运行时扩展Java类,用来创建代理对象
ps:创建代理对象的主流的三种方式(1.jdkproxy 2.cglib 3.javassist)
jta-1.1.jar
作用:标准的Java事务处理接口, sun公司给分布式事务处理(解释:事务涉及到的数据来自不同的jvm)提供的规范,jta是一个标准和规范(意味着jta是一个接口)
slf4j-api-1.6.1.jar
作用:Hibernate的一个日记系统(与slf4j-log4j12-1.7.13.jar一起构成日记系统)
(1.2)/lib/jpa/hibernate-jpa-2.0-api-1.0.0.Final.jar(1个jar包)
作用:jpa接口开发包
(3) slf4j-1.7.13 文件夹中的
slf4j-log4j12-1.7.13.jar(1个jar包)
作用:Hibernate的一个日记系统(与slf4j-api-1.6.1.jar一起构成日记系统)
(3)数据库的驱动包
(4) Log4j的核心jar包
作用:Hibernate没有提供日志的实现,通过slf4j和Log4j开发包,整合Hibernate的日志系统到Log4j
共计:11个jar包
3. hibernate.cfg.xml配置文件
位置: 根目录
用途:告诉hibernate连接数据库的信息,用什么样的数据库,根据映射文件和持久化类生成表的策略,并引用映射文件
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <!-- 一个session-factory代表数据库的一个连接 --> <session-factory> <property name="connection.username">root</property> <property name="connection.password">617475430</property> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.url">jdbc:mysql://localhost:3307/myhibernate</property> <!-- 告诉hibernate使用什么样的数据库,hibernate在底层拼接什么样的sql语句 --> <property name="dialect">org.hibernate.dialect.MySQLDialect</property> <!-- 根据持久化类生成表的策略 validate:通过映射文件检查表与持久类的匹配 (*)update:每次hibernate启动的时候,检查表是否存在,如果不存在则创建,如果存在,则没有任何动作 create:每次hibernate启动的时候,根据持久化类和映射文件生成表 create-drop:每次hibernate启动的时候,根据持久化类和映射文件生成表,关闭时丢弃表 --> <property name="hbm2ddl.auto">update</property>
</session-factory> </hibernate-configuration>
ps:正确软件开发流程应该为:
需求分析 -> 写e-r图 -> 设计类 -> 再设计表 (hbm2ddl.auto 就根据持久化类生成表的策略)
而在中国:
需求分析(不确定) -> 无法继续
采用:设计表 -> 设计类 。。。逆向开发
4. 创建domain类
Hibernate采用低侵入式设计,这种设计对持久化类几乎不做任何要求,也就是说,Hibernate操作的持久化类基本都是普通的,传统的Java对象(POJO),虽然对持久化类没有太多要求,但我们还是需要遵守以下规范
(1)提供无参构造函数,Hibernate内部会创建持久化类的代理对象,我们知道,通过反射创建对象的一个前提就是有无参构造函数。
(2)提供标识属性,也就是与表的主键字段的映射,我们尽量使用可以为空的数据类型,尽量避免使用基本数据类型
(3)使用非final的类,Hibernate会在运行的时候,生成持久化类的代理对象,如果持久化类没有实现任何接口,Hibernate使用javassit生成代理,如果持久化类有实现的public 接口,则使用JDK的动态代理,如果为持久化类为final,则无法进行性能优化,如果一定要使用final,通过设置lazy="false"。明确禁用代理.
ps:一般都会实现Serializable接口
只要是分布式环境传递对象,对象就需要在网络上传输,就需要把对象变成二进制码,这时就需要实现Serializable,jvm会自动把对象变成二进制码,
(4)重写equals()和hashCode()方法,当把持久化类放入Set集合时,在我们后续学习会出现这种情况,此时我们需要重写equals和hashCode()方法,通常比较是两个对象的标识属性的值
5. *.hbm.xml 映射文件
作用:持久化类通过映射文件去数据库找对应的表
大体为三对映射:
1,从表到类的映射
2,从表的字段名称到类的属性名称的映射
3,从表的字段类型到类的字段类型的映射
<?xml version="1.0"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"> <!-- Generated 2015-12-30 15:39:58 by Hibernate Tools 3.5.0.Final --> <hibernate-mapping> <!-- class用来描述一个类。
table属性用来描述持久类对应的表的名字,可以不写,默认为类名。
catalog属性设置数据库的名字,因为在配置文件中已经指定了(connection.url中指定了数据库名) --> <class name="domain.Customer" table="CUSTOMER"> <!-- id用来描述主键
length:属性名称对应的表字段的长度,如果不写,默认是最大的长度,leng越大,数据库在物理层开辟的空间越大,空间过大相对来说影响性能
column:数据库中表的字段名,如果不写,默认就是name中的值,
--> <id name="id" type="int"> <column name="ID" /> <!-- 主键生成策略 --> <generator class="assigned" /> </id> <property name="username" type="java.lang.String"> <column name="USERNAME" /> </property> <property name="password" type="java.lang.String"> <column name="PASSWORD" /> </property> </class> </hibernate-mapping>
6.生成表
ps:注意把你的映射文件导入到配置文件中,在配置文件中的<session-factory>..</session-factory>中加入这样一句
<session-factory> .... <mapping resource="domain/*.hbm.xml"> <!-- *.hbm.xml为表的配置文件 --> </session-factory>
public void create() { Configuration c=new Configuration(); //加载配置文件有两种方式: //方式一: c.configure(); /* 方式二:用c.configure("String path"); “String path”:*.cfg.xml配置文件的路径 */ //使用配置文件和映射文件进行建表操作 c.buildSessionFactory(); }
ps:加载配置文件方式一的源代码,这样子我们知道了配置文件的一些规则。

加载配置文件方式一的两个规则
1."/..."是相对目录。该配置文件必须在classpath的根目录下
2.配置文件名字是固定的
7.CRUD操作
- 保存(Save)
@Test public void save(){ Configuration c=new Configuration(); c.configure(); SessionFactory sf=c.buildSessionFactory(); //sessionfactory等于数据库中的一个连接· Session session=sf.openSession();//打开一个连接 Transaction t=session.beginTransaction();//产生一个事务 Customer p=new Customer();//创建一个对象 p.setUsername("a164123"); p.setPassword("123456"); session.save(p); //保存对象 t.commit(); //事务提交 sf.close(); //session关闭 }
- 查(Read)
@Test public void testGetCustomerById(){ Configuration c=new Configuration(); c.configure(); SessionFactory sf=c.buildSessionFactory(); Session s=sf.openSession(); //s.get(Class class,Serializable id)
//第一个参数为持久化类的字节码 //第二个参数为数据库中的主键的值 Customer p=(Customer)s.get(Customer.class, 0); s.close(); }
- 修改(Update)
@Test public void testUpdateCustomer(){ Configuration c=new Configuration(); c.configure(); SessionFactory sf=c.buildSessionFactory(); Session s=sf.openSession(); Transaction t=s.beginTransaction(); t.begin(); /* 修改的流程: 第一步:先把对象查询出来 第二步: 再进行修改 */ Customer p=(Customer)s.get(Customer.class, 0); p.setUsername("new"); p.setPassword("new"); s.update(p); t.commit(); s.close(); }
- 删除(Delete)
@Test public void testDeleteCustomer(){ Configuration c=new Configuration(); c.configure(); SessionFactory sf=c.buildSessionFactory(); Session s=sf.openSession(); Transaction t=s.beginTransaction(); Customer p=(Customer)s.get(Customer.class, 0); //第一步:把要删除的先get出来 s.delete(p); //第二步:再进行删除 t.commit(); s.close(); }
番外篇:【eclipse】反向工程,根据数据库中的表生成持久化类和映射文件
大体分为两个步骤:
1.要在eclipse中采用自带的数据库管理器,连通数据库(Show View->找到Data Source Explorer)
这一步就主要就是指定驱动jar包,填写连接数据库的一些信息
2.生成Hibernate实体类
(1)打开Hibernate Configurations(找不到该窗口是因为:需要给eclipse下载插件)
(2)找到Hibernate Code Generation并勾选,之后会在eclipse工具栏中显示一个图标,点击Hibernate Code Generat...等配置并Run生成
学习逆向链接:http://blog.csdn.net/wangpeng047/article/details/6877720
三。详解hibernate流程
-
SessionFactory类
1.SessionFactory是单个数据库映射关系经过编译后的内存镜像,这种映射关系,就包括了ORM框架的基本三种映射关系。那么当然SessionFactory中就包括了配置文件,映射文件,持久化类的信息。
2.sessionFactory中存在的信息是共享的,因为配置文件,映射文件,持久化类的信息都只有一份,
3.SessionFactory是线程安全的,所以这些共享信息没有线程安全问题。
4.一个Hibernate框架,只会产生一个SessionFactory对象
-
Session
1.得到了session,相当于打开了一次数据库连接
2.所有的持久化对象必须在Session管理下才可以进行持久化操作。
3.在Hibernate中,对数据的CRUD都是由session来完成的
-
Transaction
jdbc中事务是自动提交的,如果需要手动提交就需要开启事务,自动提交相对来说是不安全的,在Hibernate中事务默认就是手动提交的,Hibernate内部实际是通过jdbc得到事务的,所以实际上session.beginTransaction()就是把jdbc的自动提交给关闭了
Hibernate流程汇总(图中有错,图下进行了纠正)
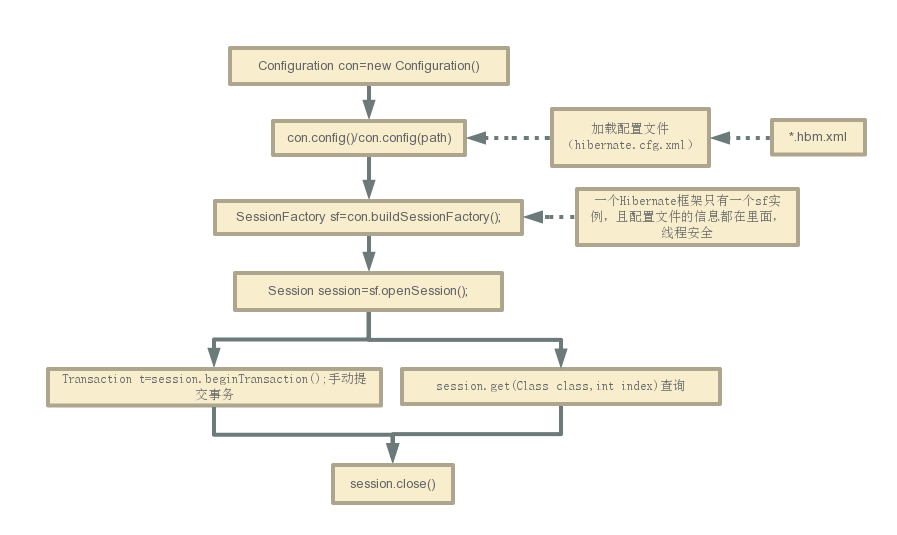
ps:注意有个严重的错误:
在session.close()之前,要先关闭事务,也就是在close之前要先t.commit(),一定要记得先提交事务,在关闭session
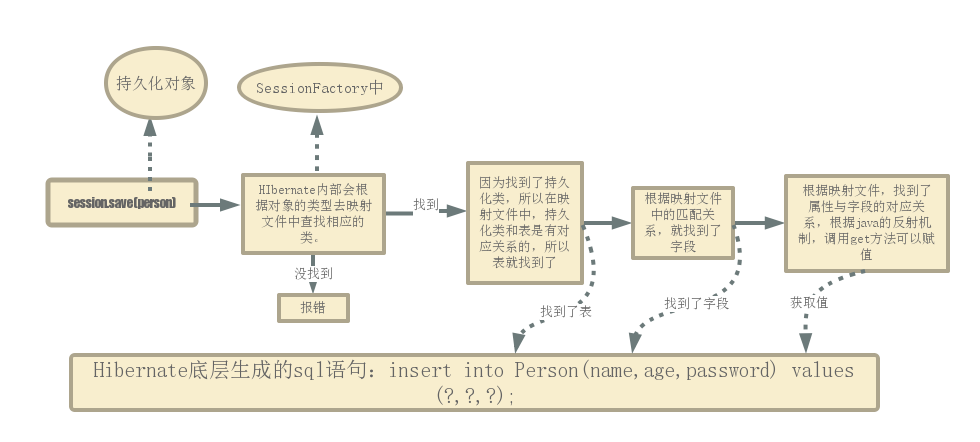
四。Hibernate底层拼接原理
为了看清楚Hibernate最终拼接成的sql语句,我们可以再hibernate.cfg.xml的<session-factory.../>中增加两个配置
<!-- 控制台显示拼接后的sql语句 --> <property name="show_sql">true</property> <!-- 后台显示的sql语句给我美观一点 --> <property name="format_sql>true</property>
五。详解映射文件(*.hbm.xml)-字段类型
Hibernate类型
回去看映射文件(*.hbm.xml),type属性的值 既可以是Hibernate类型,也可是Java类型
<property name="username" type="java.lang.String"> <column name="USERNAME" /> </property> <property name="password" type="java.lang.String"> <column name="PASSWORD" /> </property>
Hibernate类型对应的其实就是java的原始类型和包装类。不过包装类变成小写,如Java中的Integer类型,对应Hibernate的integer类型。如Java的String类型,对应Hibernate的string类型。
那一会java类型,一会Hibernate类型,Hibernate不就懵逼了吗?
在Hibernate内部映射了一个类型的维护,Hibernate的string类型就是把java.lang.String到VARCHAR的映射,所以Java类型效率高,因为type如何写了Hibernate类型,Hibernate要去内部进行先变成java类型再变成sql类型。
五。详解映射文件(*.hbm.xml)-主键生成策略
<class name=".." table="..">
<id name="id" type="int"> <column name="ID" /> <!-- 主键生成策略 --> <generator class="increment" /> </id>
</class>
increment: 先找到主键的最大值,然后+1。 所以该主键必须是数字类型,会从数据库查询主键,
assgned: 主键我们要在程序中手动设置
identity: 表的自动增长:注意数据库中的表也要自动增长,否则报错,必须为数字,效率比increment高,因为不用查询主键。但是id值不连续
uuid: 主键要为string类型,uuid字符串是由hibernate内部生成的
sequence(Oracle特有) oracle特有,在oracle生成一个数字串,而不是string,可以设置单步增长,前面的所有行为都在oracle内部做,所以效率很高
六。Hibernate中对象的状态
-
save()
让一个临时状态对象变成持久化状态对象,

注意:
1.持久化对象在数据库中不一定有对应的值
2.临时状态和脱管状态 就好像 单身与离婚的区别。
-
修改数据
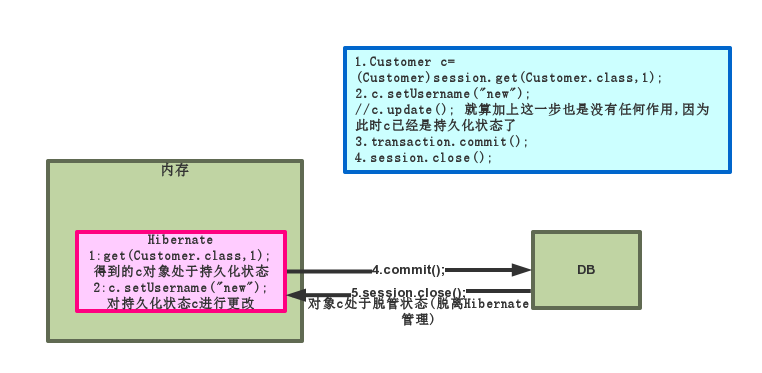
-
get()
从数据库中,根据主键,提取一个对象,该对象就是持久化状态对象
-
update()
把一个对象变成持久化状态对象

-
evict
使一个持久化状态对象变成脱管状态对象
-
clear
把Hibernate中所有的对象(所有持久化状态对象)都变成脱管状态对象
总结:
Hibernate中的对象有三种状态:1.临时状态 2.持久化状态 3.脱管状态。 显然当事务提交的时候,只对持久化状态的对象的操作才起作用
七。Hiernate对象的副本
1。对取出的数据进行修改
Customer customer=(Customer)session.get(Customer.class, 1); customer.setUsername("new"); transaction.commit();
看控制台的输出情况:
Hibernate: select customer0_.ID as ID0_0_, customer0_.USERNAME as USERNAME0_0_, customer0_.PASSWORD as PASSWORD0_0_ from CUSTOMER customer0_ where customer0_.ID=?
Hibernate: update CUSTOMER set USERNAME=?, PASSWORD=? where ID=?
2。对取出的数据不修改
Customer customer=(Customer)session.get(Customer.class, 1); customer.setPassword("ok"); transaction.commit();
Hibernate: select customer0_.ID as ID0_0_, customer0_.USERNAME as USERNAME0_0_, customer0_.PASSWORD as PASSWORD0_0_ from CUSTOMER customer0_ where customer0_.ID=?
结论:看到在第二次再次进行get,update操作的时候,控制台并没有输入修改的sql语句,原因就是Hibernate对get的对象进行了创建副本的操作,副本的数据和数据库中的数据保持一致。在commit之前,hibernate会对要提交的对象进行判断是否进行了修改,只有修改了才会提交,而是否修改的判断标准就是使用了副本对象,因为副本对象数据始终与数据库中的数据保持一致,hibernate会把我们要修改的对象与副本中的对象进行比较。
