跳表 = 单链表 + 多级索引
O(log2n)
和红黑树的查询率同数量级。
是一种用空间换时间的数据结构。
下面,
表是怎么跳的呢?
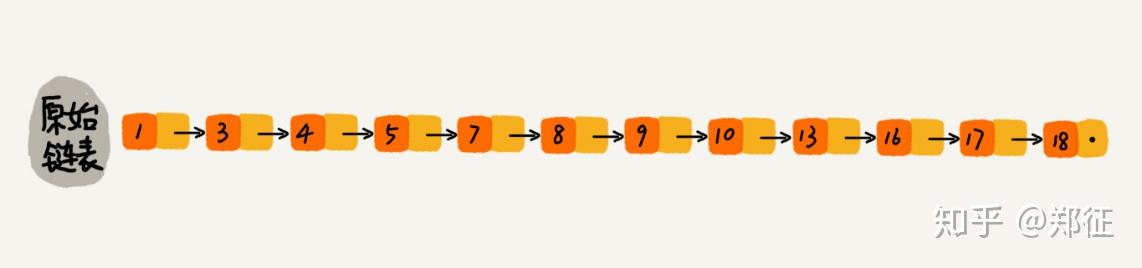
上图是一个简单的有序的单链表,如果要查找某个数据,只能从头至尾遍历链表,查找到值与给定元素时返回该结点,这样的查询效率很低,时间复杂度是为O(n)。
假如对链表进行改造,先对链表中每两个节点建立第一级索引,再对第一级索引每两个节点建立第二级索引。如下图所示:
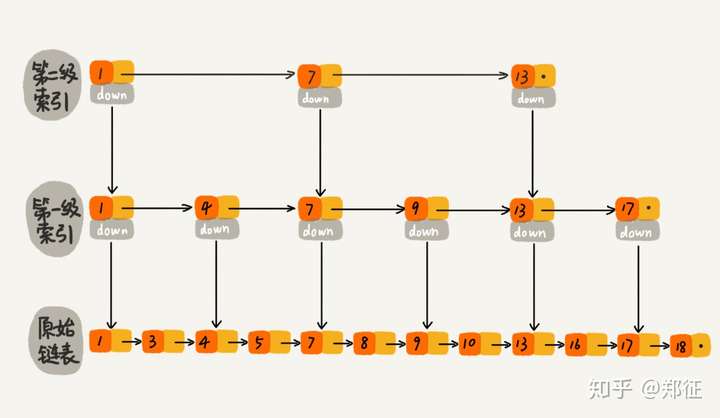
对于上图中的带二级索引的链表中,我们查询元素 16,先从第二级索引查询 1 -> 7->13,发现16大于13 ,然后通过 13 的 down 指针找到第一级索引的 17,发现 16 小于17 ,再通过13 的 down 指针找到链表中的 16,只需要遍历 6 个节点就完成 16 的查找。如果在单链表中直接查找 16 的话,只能顺序遍历,需要遍历 10 个节点,是不是效率上有所提升呢,由于数据量较小,遍历 10 个节点到遍历 6 个节点你可能觉得没有提升多少性能,那么请看下图:
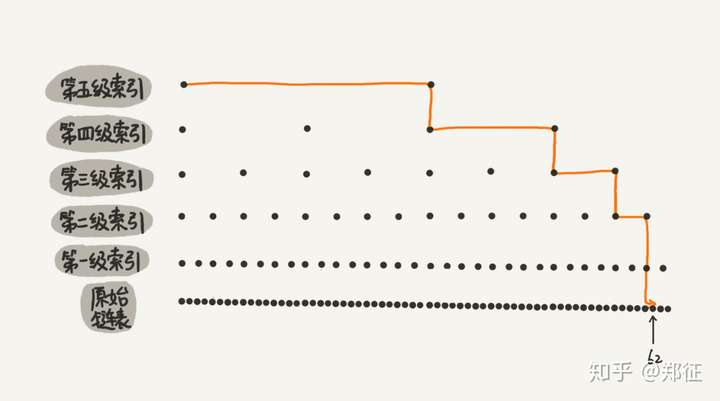
从图中我们可以看出,原来没有索引的时候,查找 62 需要遍历 62 个结点,现在只需要遍历 11 个结点,速度是不是提高了很多?所以,当链表的长度 n 比较大时,比如 1000、10000 的时候,在构建索引之后,查找效率的提升就会非常明显。
这种带多级索引的链表,就是跳表。,是不是很像数据库中的索引?
跳表有多快?
单链表的查找一个元素的时间复杂度为O(n),那么跳表的时间复杂度是多少?
假如链表中有 n 个元素,我们每两个节点建立一个索引,那么第 1 级索引的结点个数就是 n/2 ,第二级就是 n/4,第三级就是 n/8, 依次类推,也就是说第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那么第k级索引的节点个数为 n 除以 2 的 k 次方,即 n/(2^k)。
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2^h) = 2,得到 h=log2n - 1,包含原始链表这一层的话,跳表的高度就是 log2n,假设每层需要访问 m 个结点,那么总的时间复杂度就是O(m*log2n)。而每层需要访问的 m 个结点,m 的最大值不超过 3,这里为什么是 3 ,可以自己试着走一个。
因此跳表的时间复杂度为O(3log2n) = O(log2n)
跳表有多占内存?
天下没有免费的午餐,时间复杂度能做到 O(logn) 是以建立在多级索引的基础之上,这会导致内存占用增加,那么跳表的空间复杂度是多少呢?
假如有 n 个元素的链表,第一级索引为 n/2 个,第二级为 n/4 个,第三级为 n/8 个,......,最后一级为 2 个。这几级索引的结点总和就是n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是 O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,我们需要额外再用接近 n 个结点的存储空间。那我们有没有办法降低索引占用的内存空间呢?
假如每 3 个节点抽取一个作为索引,同样的方法,可以计算出空间复杂度为 O(n/2) ,已经节约一半的存储空间了。
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
跳表如何实现
跳表这种拿空间换时间的思想非常巧妙。那么如何编程实现一个跳表的数据结构呢?
其实,知道与践行之间隔着巨大的鸿沟,知道那么多的算法,可是仍写不出牛逼的代码。还是要多写多练,不然就会被说 talk is cheap,show me the code。
编码之前,应该思考一下跳表应支持的功能: 1、插入一个元素 2、删除一个元素 3、查找一个元素 4、查找一个区间的元素 5、输出有序序列
其实 redis 中有序集合支持的核心操作也就是这几个。这里说下为什么 redis 使用跳表而不使用红黑树。
1、红黑树在查找区间元素的效率没有跳表高,其他操作时间复杂度一致。 2、相比红黑树,跳表的实现还是简单的,简单就意味着不容易出错,bug 少,稳定,易读,易维护。 3、跳表更加灵活,通过改变索引构建策略,有效平衡效率和内存消耗。