一、 验证
1、进入bin目录
cd bin
2、ls查看脚本
会发现下面有很多脚本文件,由于我是要创建一个topic所有直接打开kafka-topics.sh脚本查看命令

打开脚本后发现里面有很多命令,里面命令都有提示,平时操作不知道怎么写时可以查看

由于我要创建的topic要设置分区和副本,所以需要的命令有下面这五个
-
- --create是创建命令
- --topic是创建topic的名字
- --bootstrap-server指连接到哪个节点
- --partitions指定多少个分区
- --replication-factor副本
3、创建命令
./bin/kafka-topics.sh --create --topic test --bootstrap-server 192.168.32.122:9092 --partitions 1 --replication-factor 1
里面日志非常详细可以看下,里面写了副本名称例如set(test-0)还有他存放位置及刷新时间

4、查看信息
cd /root/kafka/kafka-logs
可以看到里面有个test-0信息

进入test-0可以看到里面详细信息,但里面消息是空的
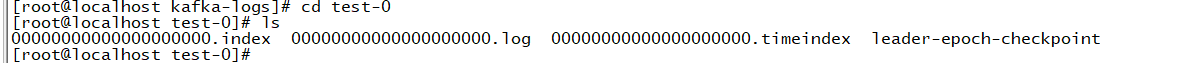
5、查看topic信息命令
./bin/kafka-topics.sh --describe --topic test --bootstrap-server 192.168.32.122:9092

6、发送消息
进入ls bin/可以看到里面的发送消息和消费消息的脚本,所以平时如果需要什么命令可以自己进去查看

发送消息
./bin/kafka-console-producer.sh --bootstrap-server 192.168.32.122:9092 --topic test
7、消费消息
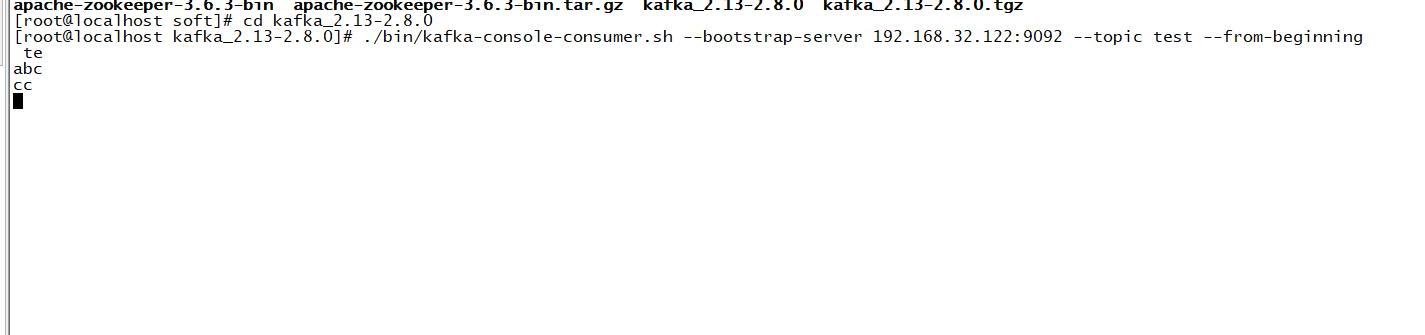
另起一台服务器,发送命令
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.32.122:9092 --topic test --from-beginning
这样就可以一边发消息一边消费了

二、kafka应用场景
2.1 消息
kafka 更好的替换传统的消息系统,消息系统被用于各种场景(解耦数据生产者,缓存未处理的消息),与大多数消息系统比较,kafka 有更好的吞吐量,内置分区,副本和故障转移等功能,这有利于处理大规模的消息。
根据官方的经验,通常消息传递使用较低的吞吐量,但可能要求较低的端到端延迟,kafka 提供强大的持久性来满足这一要求。在这方面,Kafka 可以与传统的消息传递系统(ActiveMQ 和 RabbitMQ)相媲美。但是RabbitMQ可以顺序消费但kafka很难实现。
2.2 跟踪网站活动
kafka 的最初始作用就是是将用户活动跟踪管道重建为一组实时发布-订阅源。 把网站活动(浏览网页、搜索或其他的用户操作)发布到中心 topic,其中每个活动类型有一个 topic。 这些订阅源提供一系列用例,包括实时处理、实时监视、对加载到Hadoop或离线数据仓库系统的数据进行离线处理和报告等。每个用户浏览网页时都生成了许多活动信息,因此活动跟踪的数据量通常非常大。这就非常使用使用 kafka。
2.3 日志聚合
许多人使用 kafka来替代日志聚合解决方案。日志聚合系统通常从服务器收集物理日志文件,并将其置于一个中心系统(可能是文件服务器或HDFS)进行处理。kafka 从这些日志文件中提取信息,并将其抽象为一个更加清晰的消息流。 这样可以实现更低的延迟处理且易于支持多个数据源及分布式数据的消耗。与 Scribe 或 Flume 等以日志为中心的系统相比,Kafka具备同样出色的性能、更强的耐用性(因为复制功能)和更低的端到端延迟。
2.4 流处理
从0.10.0.0开始,kafka 支持轻量,但功能强大的流处理。kafka消息处理包含多个阶段。其中原始输入数据是从kafka主题消费的,然后汇总,丰富,或者以其他的方式处理转化为新主题以供进一步消费或后续处理。例如,一个推荐新闻文章,文章内容可能从“articles”主题获取;然后进一步处理内容,得到一个处理后的新内容,最后推荐给用户。这种处理是基于单个主题的实时数据流。除了Kafka Streams,还有 Apache Storm 和 Apache Samza 也是不错的流处理框架。
2.5 事件采集
Event sourcing是一种应用程序设计风格,按时间来记录状态的更改。 Kafka 可以存储非常多的日志数据,为基于 event sourcing 的应用程序提供强有力的支持。
2.6 提交日志
kafka 可以从外部为分布式系统提供日志提交功能。 日志有助于记录节点和行为间的数据,采用重新同步机制可以从失败节点恢复数据。 Kafka的日志压缩 功能支持这一用法。 这一点与Apache BookKeeper 项目类似。