1.原理
awk,一个行文本处理工具,逐行处理文件中的数据
语法:awk 'pattern + {action}'
说明:
(1)单引号''是为了和shell命令区分开;
(2)大括号{}表示一个命令分组;
(3)pattern是一个过滤器,表示命中pattern的行才进行action处理;
(4)action是处理动作;
(5)使用#作为注释;
pattern参数可以是egrep正则中的一个,正则使用/pattern/
例子:显示hello.txt中的第3行至第5行:cat hello.txt | awk 'NR==3, NR==5{print;}'
例子:显示hello.txt中,正则匹配hello的行:cat hello.txt | awk '/hello/'
说明:
(1)pattern和action可以只有其一,但不能两者都没有;
(2)默认的action是print;
例子:显示hello.txt中,长度大于100的行号:cat hello.txt | awk 'length($0)>80{print NR}'
#内置变量
FS 分隔符,默认是空格
NR 当前行数,从1开始
NF 当前记录字段个数
$0 当前记录
$1~$n 当前记录第n个字段
例子:显示hello.txt中的第3行至第5行的第一列与最后一列:cat hello.txt | awk 'NR==3, NR==5{print $1,$NF}'
#内置函数
gsub(r,s):在$0中用s代替r
index(s,t):返回s中t的第一个位置
length(s):s的长度
match(s,r):s是否匹配r
split(s,a,fs):在fs上将s分成序列a
substr(s,p):返回s从p开始的子串
#时间格式
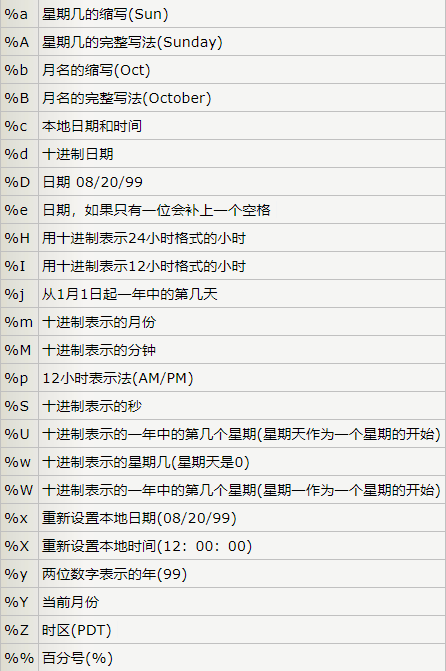
$ awk '{ now=strftime( "%D", systime() ); print now }'
$ awk '{ now=strftime("%m/%d/%y"); print now }'
#操作符
##运算符
类似于c,支持+、-、*、/、%、++、–、+=、-=等诸多操作;
##判断符
类似于c,支持==、!=、>、=>、~(匹配于)等诸多判断操作;
#控制流程
##BEGIN和END
BEGIN和END本质是一个pattern。
BEGIN用于awk程序开始开始前,做一些初始化的工作;
END用于awk程序结束前,做一些收尾的工作。
例子:awk 'begin { count=0;} { count+=length($0); } { print count; } end'
##流程控制语句
(1)if(condition){}else{}
(2)while{}
(3)do{}while(condition);
(4)for(init;condition;step){}
(5)break/continue:如果有END,会执行END中的收尾工作
流程控制语句用法几乎与c相同。
awk '{if(NR>=20 && NR<=30) print $1}' test.txt
awk与shell的交互
awk中使用shell中定义的变量:使用单引号即可;
#!/bin/bash
STR="hello"
echo | awk '{
print "'${STR}'";
}'
awk中使用shell命令:使用双引号,或者system命令;
#!/bin/bash
echo hello | awk '{
print $0 | "cat" 或 system("date > date.txt ")
}'
getline:awk里,从文件中读取变量到awk中
#!/bin/bash
echo | awk '{
while(getline < "date.txt")
{
print $0;
}
}'